 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation Methods for Anaphoric Zero Pronouns
Sep 20, 2021
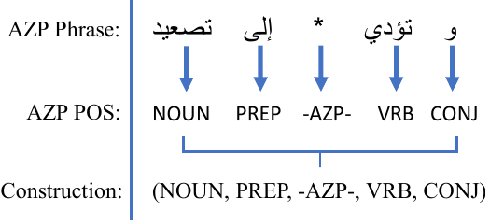
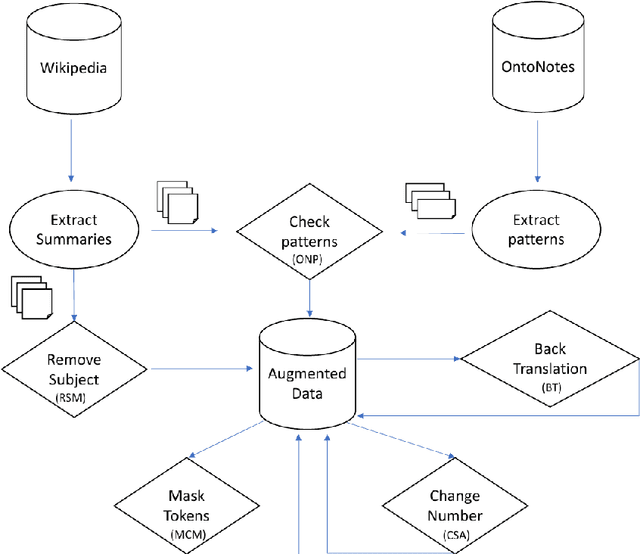

In pro-drop language like Arabic, Chinese, Italian, Japanese, Spanish, and many others, unrealized (null) arguments in certain syntactic positions can refer to a previously introduced entity, and are thus called anaphoric zero pronouns. The existing resources for studying anaphoric zero pronoun interpretation are however still limited. In this paper, we use five data augmentation methods to generate and detect anaphoric zero pronouns automatically. We use the augmented data as additional training materials for two anaphoric zero pronoun systems for Arabic. Our experimental results show that data augmentation improves the performance of the two systems, surpassing the state-of-the-art results.
Neural Coreference Resolution for Arabic
Oct 31, 2020
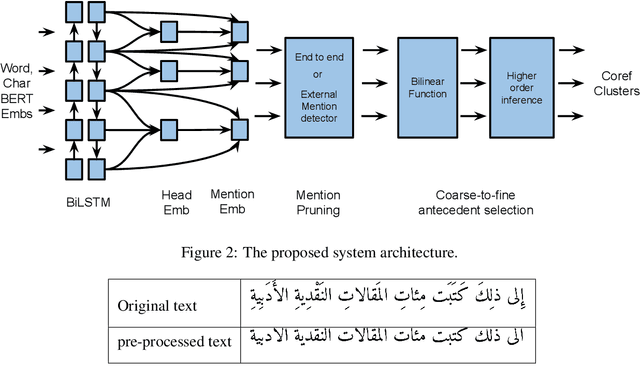
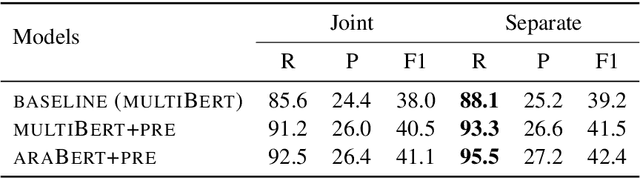
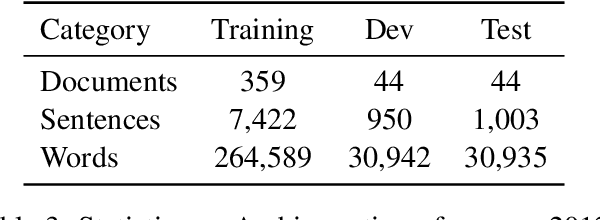
No neural coreference resolver for Arabic exists, in fact we are not aware of any learning-based coreference resolver for Arabic since (Bjorkelund and Kuhn, 2014). In this paper, we introduce a coreference resolution system for Arabic based on Lee et al's end to end architecture combined with the Arabic version of bert and an external mention detector. As far as we know, this is the first neural coreference resolution system aimed specifically to Arabic, and it substantially outperforms the existing state of the art on OntoNotes 5.0 with a gain of 15.2 points conll F1. We also discuss the current limitations of the task for Arabic and possible approaches that can tackle these challenges.