Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation Methods for Anaphoric Zero Pronouns
Paper and Code

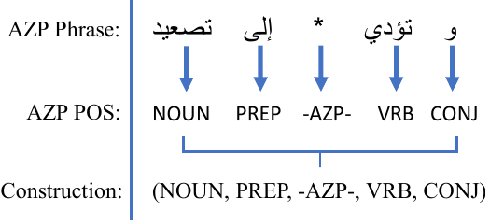
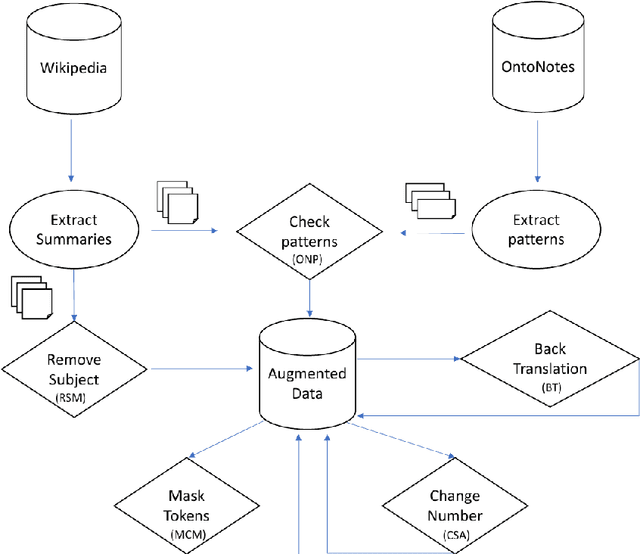

In pro-drop language like Arabic, Chinese, Italian, Japanese, Spanish, and many others, unrealized (null) arguments in certain syntactic positions can refer to a previously introduced entity, and are thus called anaphoric zero pronouns. The existing resources for studying anaphoric zero pronoun interpretation are however still limited. In this paper, we use five data augmentation methods to generate and detect anaphoric zero pronouns automatically. We use the augmented data as additional training materials for two anaphoric zero pronoun systems for Arabic. Our experimental results show that data augmentation improves the performance of the two systems, surpassing the state-of-the-art results.
* CRAC2021@EMNLP2021
View paper on