 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScoring Coreference Chains with Split-Antecedent Anaphors
Paper and Code
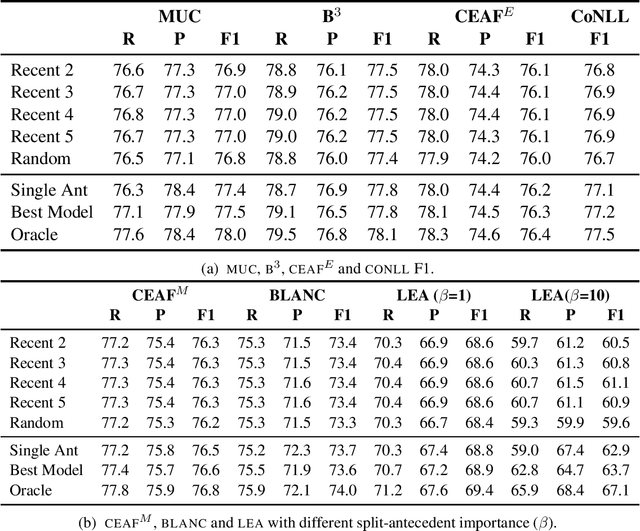

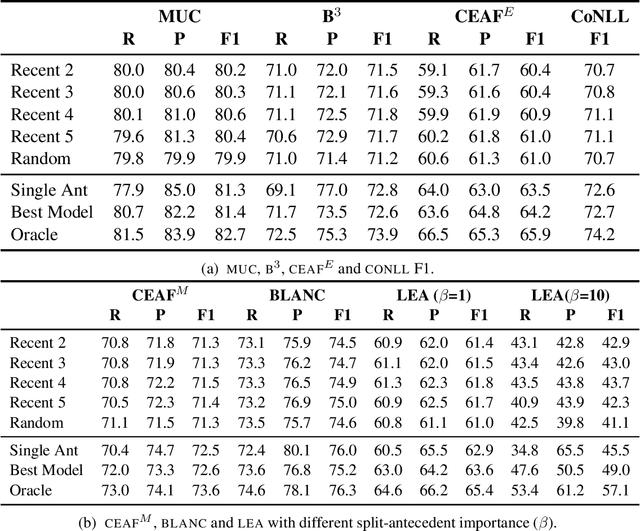

Anaphoric reference is an aspect of language interpretation covering a variety of types of interpretation beyond the simple case of identity reference to entities introduced via nominal expressions covered by the traditional coreference task in its most recent incarnation in ONTONOTES and similar datasets. One of these cases that go beyond simple coreference is anaphoric reference to entities that must be added to the discourse model via accommodation, and in particular split-antecedent references to entities constructed out of other entities, as in split-antecedent plurals and in some cases of discourse deixis. Although this type of anaphoric reference is now annotated in many datasets, systems interpreting such references cannot be evaluated using the Reference coreference scorer Pradhan et al. (2014). As part of the work towards a new scorer for anaphoric reference able to evaluate all aspects of anaphoric interpretation in the coverage of the Universal Anaphora initiative, we propose in this paper a solution to the technical problem of generalizing existing metrics for identity anaphora so that they can also be used to score cases of split-antecedents. This is the first such proposal in the literature on anaphora or coreference, and has been successfully used to score both split-antecedent plural references and discourse deixis in the recent CODI/CRAC anaphora resolution in dialogue shared tasks.