 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2023 Task 11: Learning With Disagreements (LeWiDi)
Apr 28, 2023NLP datasets annotated with human judgments are rife with disagreements between the judges. This is especially true for tasks depending on subjective judgments such as sentiment analysis or offensive language detection. Particularly in these latter cases, the NLP community has come to realize that the approach of 'reconciling' these different subjective interpretations is inappropriate. Many NLP researchers have therefore concluded that rather than eliminating disagreements from annotated corpora, we should preserve them-indeed, some argue that corpora should aim to preserve all annotator judgments. But this approach to corpus creation for NLP has not yet been widely accepted. The objective of the LeWiDi series of shared tasks is to promote this approach to developing NLP models by providing a unified framework for training and evaluating with such datasets. We report on the second LeWiDi shared task, which differs from the first edition in three crucial respects: (i) it focuses entirely on NLP, instead of both NLP and computer vision tasks in its first edition; (ii) it focuses on subjective tasks, instead of covering different types of disagreements-as training with aggregated labels for subjective NLP tasks is a particularly obvious misrepresentation of the data; and (iii) for the evaluation, we concentrate on soft approaches to evaluation. This second edition of LeWiDi attracted a wide array of participants resulting in 13 shared task submission papers.
Leveraging Social Interactions to Detect Misinformation on Social Media
Apr 06, 2023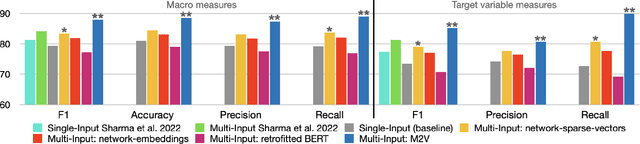


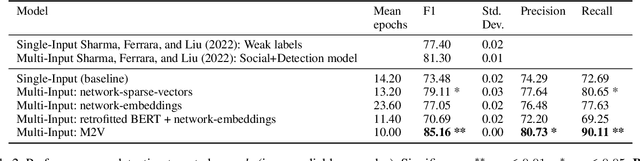
Detecting misinformation threads is crucial to guarantee a healthy environment on social media. We address the problem using the data set created during the COVID-19 pandemic. It contains cascades of tweets discussing information weakly labeled as reliable or unreliable, based on a previous evaluation of the information source. The models identifying unreliable threads usually rely on textual features. But reliability is not just what is said, but by whom and to whom. We additionally leverage on network information. Following the homophily principle, we hypothesize that users who interact are generally interested in similar topics and spreading similar kind of news, which in turn is generally reliable or not. We test several methods to learn representations of the social interactions within the cascades, combining them with deep neural language models in a Multi-Input (MI) framework. Keeping track of the sequence of the interactions during the time, we improve over previous state-of-the-art models.
ProSiT! Latent Variable Discovery with PROgressive SImilarity Thresholds
Oct 26, 2022



The most common ways to explore latent document dimensions are topic models and clustering methods. However, topic models have several drawbacks: e.g., they require us to choose the number of latent dimensions a priori, and the results are stochastic. Most clustering methods have the same issues and lack flexibility in various ways, such as not accounting for the influence of different topics on single documents, forcing word-descriptors to belong to a single topic (hard-clustering) or necessarily relying on word representations. We propose PROgressive SImilarity Thresholds - ProSiT, a deterministic and interpretable method, agnostic to the input format, that finds the optimal number of latent dimensions and only has two hyper-parameters, which can be set efficiently via grid search. We compare this method with a wide range of topic models and clustering methods on four benchmark data sets. In most setting, ProSiT matches or outperforms the other methods in terms six metrics of topic coherence and distinctiveness, producing replicable, deterministic results.