 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrowth First, Care Second? Tracing the Landscape of LLM Value Preferences in Everyday Dilemmas
Feb 04, 2026People increasingly seek advice online from both human peers and large language model (LLM)-based chatbots. Such advice rarely involves identifying a single correct answer; instead, it typically requires navigating trade-offs among competing values. We aim to characterize how LLMs navigate value trade-offs across different advice-seeking contexts. First, we examine the value trade-off structure underlying advice seeking using a curated dataset from four advice-oriented subreddits. Using a bottom-up approach, we inductively construct a hierarchical value framework by aggregating fine-grained values extracted from individual advice options into higher-level value categories. We construct value co-occurrence networks to characterize how values co-occur within dilemmas and find substantial heterogeneity in value trade-off structures across advice-seeking contexts: a women-focused subreddit exhibits the highest network density, indicating more complex value conflicts; women's, men's, and friendship-related subreddits exhibit highly correlated value-conflict patterns centered on security-related tensions (security vs. respect/connection/commitment); by contrast, career advice forms a distinct structure where security frequently clashes with self-actualization and growth. We then evaluate LLM value preferences against these dilemmas and find that, across models and contexts, LLMs consistently prioritize values related to Exploration & Growth over Benevolence & Connection. This systemically skewed value orientation highlights a potential risk of value homogenization in AI-mediated advice, raising concerns about how such systems may shape decision-making and normative outcomes at scale.
Is Grokipedia Right-Leaning? Comparing Political Framing in Wikipedia and Grokipedia on Controversial Topics
Jan 21, 2026Online encyclopedias are central to contemporary information infrastructures and have become focal points of debates over ideological bias. Wikipedia, in particular, has long been accused of left-leaning bias, while Grokipedia, an AI-generated encyclopedia launched by xAI, has been framed as a right-leaning alternative. This paper presents a comparative analysis of Wikipedia and Grokipedia on well-established politically contested topics. Specifically, we examine differences in semantic framing, political orientation, and content prioritization. We find that semantic similarity between the two platforms decays across article sections and diverges more strongly on controversial topics than on randomly sampled ones. Additionally, we show that both encyclopedias predominantly exhibit left-leaning framings, although Grokipedia exhibits a more bimodal distribution with increased prominence of right-leaning content. The experimental code is publicly available.
Harm in AI-Driven Societies: An Audit of Toxicity Adoption on Chirper.ai
Jan 03, 2026Large Language Models (LLMs) are increasingly embedded in autonomous agents that participate in online social ecosystems, where interactions are sequential, cumulative, and only partially controlled. While prior work has documented the generation of toxic content by LLMs, far less is known about how exposure to harmful content shapes agent behavior over time, particularly in environments composed entirely of interacting AI agents. In this work, we study toxicity adoption of LLM-driven agents on Chirper.ai, a fully AI-driven social platform. Specifically, we model interactions in terms of stimuli (posts) and responses (comments), and by operationalizing exposure through observable interactions rather than inferred recommendation mechanisms. We conduct a large-scale empirical analysis of agent behavior, examining how response toxicity relates to stimulus toxicity, how repeated exposure affects the likelihood of toxic responses, and whether toxic behavior can be predicted from exposure alone. Our findings show that while toxic responses are more likely following toxic stimuli, a substantial fraction of toxicity emerges spontaneously, independent of exposure. At the same time, cumulative toxic exposure significantly increases the probability of toxic responding. We further introduce two influence metrics, the Influence-Driven Response Rate and the Spontaneous Response Rate, revealing a strong trade-off between induced and spontaneous toxicity. Finally, we show that the number of toxic stimuli alone enables accurate prediction of whether an agent will eventually produce toxic content. These results highlight exposure as a critical risk factor in the deployment of LLM agents and suggest that monitoring encountered content may provide a lightweight yet effective mechanism for auditing and mitigating harmful behavior in the wild.
Network-informed Prompt Engineering against Organized Astroturf Campaigns under Extreme Class Imbalance
Jan 21, 2025Detecting organized political campaigns is of paramount importance in fighting against disinformation on social media. Existing approaches for the identification of such organized actions employ techniques mostly from network science, graph machine learning and natural language processing. Their ultimate goal is to analyze the relationships and interactions (e.g. re-posting) among users and the textual similarities of their posts. Despite their effectiveness in recognizing astroturf campaigns, these methods face significant challenges, notably the class imbalance in available training datasets. To mitigate this issue, recent methods usually resort to data augmentation or increasing the number of positive samples, which may not always be feasible or sufficient in real-world settings. Following a different path, in this paper, we propose a novel framework for identifying astroturf campaigns based solely on large language models (LLMs), introducing a Balanced Retrieval-Augmented Generation (Balanced RAG) component. Our approach first gives both textual information concerning the posts (in our case tweets) and the user interactions of the social network as input to a language model. Then, through prompt engineering and the proposed Balanced RAG method, it effectively detects coordinated disinformation campaigns on X (Twitter). The proposed framework does not require any training or fine-tuning of the language model. Instead, by strategically harnessing the strengths of prompt engineering and Balanced RAG, it facilitates LLMs to overcome the effects of class imbalance and effectively identify coordinated political campaigns. The experimental results demonstrate that by incorporating the proposed prompt engineering and Balanced RAG methods, our framework outperforms the traditional graph-based baselines, achieving 2x-3x improvements in terms of precision, recall and F1 scores.
IOHunter: Graph Foundation Model to Uncover Online Information Operations
Dec 19, 2024



Social media platforms have become vital spaces for public discourse, serving as modern agor\'as where a wide range of voices influence societal narratives. However, their open nature also makes them vulnerable to exploitation by malicious actors, including state-sponsored entities, who can conduct information operations (IOs) to manipulate public opinion. The spread of misinformation, false news, and misleading claims threatens democratic processes and societal cohesion, making it crucial to develop methods for the timely detection of inauthentic activity to protect the integrity of online discourse. In this work, we introduce a methodology designed to identify users orchestrating information operations, a.k.a. \textit{IO drivers}, across various influence campaigns. Our framework, named \texttt{IOHunter}, leverages the combined strengths of Language Models and Graph Neural Networks to improve generalization in \emph{supervised}, \emph{scarcely-supervised}, and \emph{cross-IO} contexts. Our approach achieves state-of-the-art performance across multiple sets of IOs originating from six countries, significantly surpassing existing approaches. This research marks a step toward developing Graph Foundation Models specifically tailored for the task of IO detection on social media platforms.
Contextualizing Internet Memes Across Social Media Platforms
Nov 18, 2023



Internet memes have emerged as a novel format for communication and expressing ideas on the web. Their fluidity and creative nature are reflected in their widespread use, often across platforms and occasionally for unethical or harmful purposes. While computational work has already analyzed their high-level virality over time and developed specialized classifiers for hate speech detection, there have been no efforts to date that aim to holistically track, identify, and map internet memes posted on social media. To bridge this gap, we investigate whether internet memes across social media platforms can be contextualized by using a semantic repository of knowledge, namely, a knowledge graph. We collect thousands of potential internet meme posts from two social media platforms, namely Reddit and Discord, and perform an extract-transform-load procedure to create a data lake with candidate meme posts. By using vision transformer-based similarity, we match these candidates against the memes cataloged in a recently released knowledge graph of internet memes, IMKG. We provide evidence that memes published online can be identified by mapping them to IMKG. We leverage this grounding to study the prevalence of memes on different platforms, discover popular memes, and select common meme channels and subreddits. Finally, we illustrate how the grounding can enable users to get context about memes on social media thanks to their link to the knowledge graph.
Leveraging Large Language Models to Detect Influence Campaigns in Social Media
Nov 14, 2023



Social media influence campaigns pose significant challenges to public discourse and democracy. Traditional detection methods fall short due to the complexity and dynamic nature of social media. Addressing this, we propose a novel detection method using Large Language Models (LLMs) that incorporates both user metadata and network structures. By converting these elements into a text format, our approach effectively processes multilingual content and adapts to the shifting tactics of malicious campaign actors. We validate our model through rigorous testing on multiple datasets, showcasing its superior performance in identifying influence efforts. This research not only offers a powerful tool for detecting campaigns, but also sets the stage for future enhancements to keep up with the fast-paced evolution of social media-based influence tactics.
Leveraging Social Interactions to Detect Misinformation on Social Media
Apr 06, 2023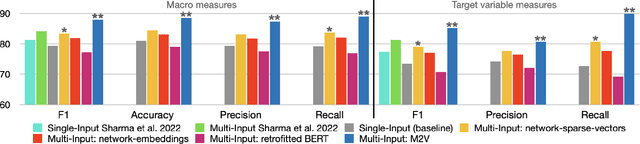


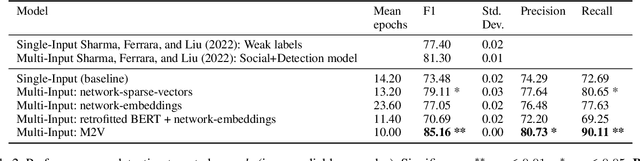
Detecting misinformation threads is crucial to guarantee a healthy environment on social media. We address the problem using the data set created during the COVID-19 pandemic. It contains cascades of tweets discussing information weakly labeled as reliable or unreliable, based on a previous evaluation of the information source. The models identifying unreliable threads usually rely on textual features. But reliability is not just what is said, but by whom and to whom. We additionally leverage on network information. Following the homophily principle, we hypothesize that users who interact are generally interested in similar topics and spreading similar kind of news, which in turn is generally reliable or not. We test several methods to learn representations of the social interactions within the cascades, combining them with deep neural language models in a Multi-Input (MI) framework. Keeping track of the sequence of the interactions during the time, we improve over previous state-of-the-art models.
Multimodal and Explainable Internet Meme Classification
Dec 11, 2022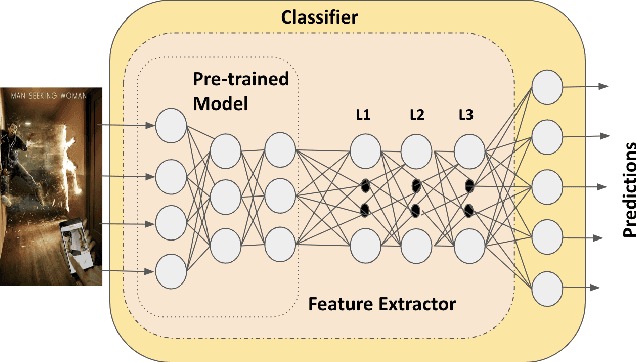

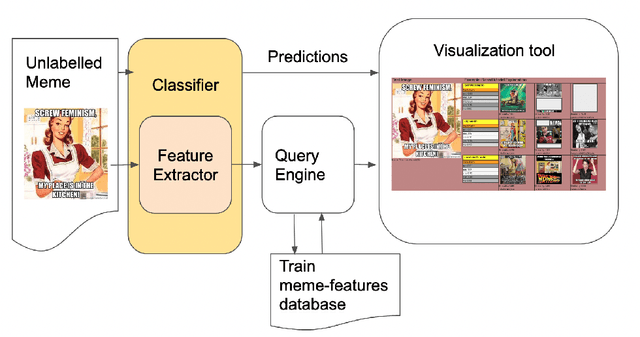

Warning: this paper contains content that may be offensive or upsetting. In the current context where online platforms have been effectively weaponized in a variety of geo-political events and social issues, Internet memes make fair content moderation at scale even more difficult. Existing work on meme classification and tracking has focused on black-box methods that do not explicitly consider the semantics of the memes or the context of their creation. In this paper, we pursue a modular and explainable architecture for Internet meme understanding. We design and implement multimodal classification methods that perform example- and prototype-based reasoning over training cases, while leveraging both textual and visual SOTA models to represent the individual cases. We study the relevance of our modular and explainable models in detecting harmful memes on two existing tasks: Hate Speech Detection and Misogyny Classification. We compare the performance between example- and prototype-based methods, and between text, vision, and multimodal models, across different categories of harmfulness (e.g., stereotype and objectification). We devise a user-friendly interface that facilitates the comparative analysis of examples retrieved by all of our models for any given meme, informing the community about the strengths and limitations of these explainable methods.
How "troll" are you? Measuring and detecting troll behavior in online social networks
Oct 17, 2022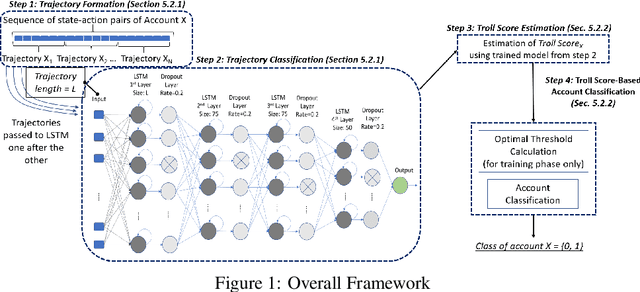
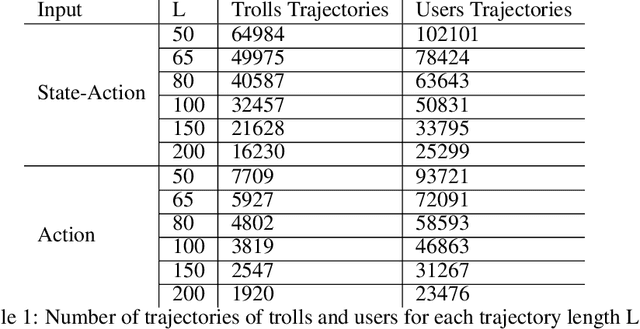
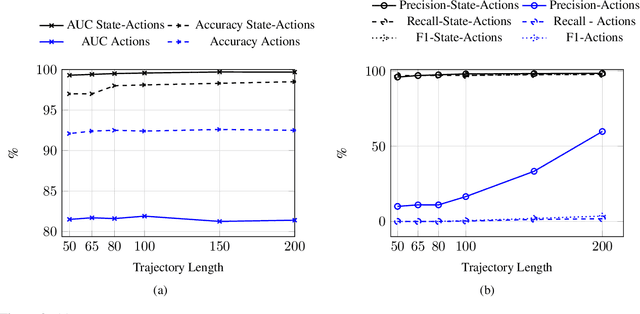

The detection of state-sponsored trolls acting in misinformation operations is an unsolved and critical challenge for the research community, with repercussions that go beyond the online realm. In this paper, we propose a novel approach for the detection of troll accounts, which consists of two steps. The first step aims at classifying trajectories of accounts' online activities as belonging to either a troll account or to an organic user account. In the second step, we exploit the classified trajectories to compute a metric, namely "troll score", which allows us to quantify the extent to which an account behaves like a troll. Experimental results show that our approach identifies accounts' trajectories with an AUC close to 99% and, accordingly, classify trolls and organic users with an AUC of 97%. Finally, we evaluate whether the proposed solution can be generalized to different contexts (e.g., discussions about Covid-19) and generic misbehaving users, showing promising results that will be further expanded in our future endeavors.