 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagging-Augmented Generation: Assisting Language Models in Finding Intricate Knowledge In Long Contexts
Oct 27, 2025Recent investigations into effective context lengths of modern flagship large language models (LLMs) have revealed major limitations in effective question answering (QA) and reasoning over long and complex contexts for even the largest and most impressive cadre of models. While approaches like retrieval-augmented generation (RAG) and chunk-based re-ranking attempt to mitigate this issue, they are sensitive to chunking, embedding and retrieval strategies and models, and furthermore, rely on extensive pre-processing, knowledge acquisition and indexing steps. In this paper, we propose Tagging-Augmented Generation (TAG), a lightweight data augmentation strategy that boosts LLM performance in long-context scenarios, without degrading and altering the integrity and composition of retrieved documents. We validate our hypothesis by augmenting two challenging and directly relevant question-answering benchmarks -- NoLima and NovelQA -- and show that tagging the context or even just adding tag definitions into QA prompts leads to consistent performance gains over the baseline -- up to 17% for 32K token contexts, and 2.9% in complex reasoning question-answering for multi-hop queries requiring knowledge across a wide span of text. Additional details are available at https://sites.google.com/view/tag-emnlp.
H$^2$GFM: Towards unifying Homogeneity and Heterogeneity on Text-Attributed Graphs
Jun 10, 2025The growing interests and applications of graph learning in diverse domains have propelled the development of a unified model generalizing well across different graphs and tasks, known as the Graph Foundation Model (GFM). Existing research has leveraged text-attributed graphs (TAGs) to tackle the heterogeneity in node features among graphs. However, they primarily focus on homogeneous TAGs (HoTAGs), leaving heterogeneous TAGs (HeTAGs), where multiple types of nodes/edges reside, underexplored. To enhance the capabilities and applications of GFM, we introduce H$^2$GFM, a novel framework designed to generalize across both HoTAGs and HeTAGs. Our model projects diverse meta-relations among graphs under a unified textual space, and employs a context encoding to capture spatial and higher-order semantic relationships. To achieve robust node representations, we propose a novel context-adaptive graph transformer (CGT), effectively capturing information from both context neighbors and their relationships. Furthermore, we employ a mixture of CGT experts to capture the heterogeneity in structural patterns among graph types. Comprehensive experiments on a wide range of HoTAGs and HeTAGs as well as learning scenarios demonstrate the effectiveness of our model.
ContextGNN goes to Elliot: Towards Benchmarking Relational Deep Learning for Static Link Prediction (aka Personalized Item Recommendation)
Mar 20, 2025

Relational deep learning (RDL) settles among the most exciting advances in machine learning for relational databases, leveraging the representational power of message passing graph neural networks (GNNs) to derive useful knowledge and run predicting tasks on tables connected through primary-to-foreign key links. The RDL paradigm has been successfully applied to recommendation lately, through its most recent representative deep learning architecture namely, ContextGNN. While acknowledging ContextGNN's improved performance on real-world recommendation datasets and tasks, preliminary tests for the more traditional static link prediction task (aka personalized item recommendation) on the popular Amazon Book dataset have demonstrated how ContextGNN has still room for improvement compared to other state-of-the-art GNN-based recommender systems. To this end, with this paper, we integrate ContextGNN within Elliot, a popular framework for reproducibility and benchmarking analyses, counting around 50 state-of-the-art recommendation models from the literature to date. On such basis, we run preliminary experiments on three standard recommendation datasets and against six state-of-the-art GNN-based recommender systems, confirming similar trends to those observed by the authors in their original paper. The code is publicly available on GitHub: https://github.com/danielemalitesta/Rel-DeepLearning-RecSys.
HDLCoRe: A Training-Free Framework for Mitigating Hallucinations in LLM-Generated HDL
Mar 18, 2025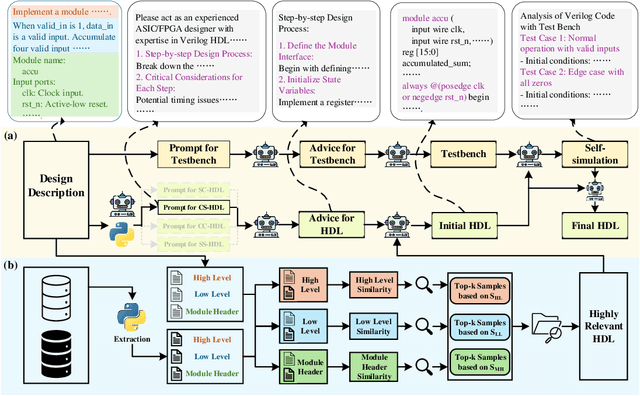



Recent advances in large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, when applied to hardware description languages (HDL), these models exhibit significant limitations due to data scarcity, resulting in hallucinations and incorrect code generation. To address these challenges, we propose HDLCoRe, a training-free framework that enhances LLMs' HDL generation capabilities through prompt engineering techniques and retrieval-augmented generation (RAG). Our approach consists of two main components: (1) an HDL-aware Chain-of-Thought (CoT) prompting technique with self-verification that classifies tasks by complexity and type, incorporates domain-specific knowledge, and guides LLMs through step-by-step self-simulation for error correction; and (2) a two-stage heterogeneous RAG system that addresses formatting inconsistencies through key component extraction and efficiently retrieves relevant HDL examples through sequential filtering and re-ranking. HDLCoRe eliminates the need for model fine-tuning while substantially improving LLMs' HDL generation capabilities. Experimental results demonstrate that our framework achieves superior performance on the RTLLM2.0 benchmark, significantly reducing hallucinations and improving both syntactic and functional correctness.
Network-informed Prompt Engineering against Organized Astroturf Campaigns under Extreme Class Imbalance
Jan 21, 2025Detecting organized political campaigns is of paramount importance in fighting against disinformation on social media. Existing approaches for the identification of such organized actions employ techniques mostly from network science, graph machine learning and natural language processing. Their ultimate goal is to analyze the relationships and interactions (e.g. re-posting) among users and the textual similarities of their posts. Despite their effectiveness in recognizing astroturf campaigns, these methods face significant challenges, notably the class imbalance in available training datasets. To mitigate this issue, recent methods usually resort to data augmentation or increasing the number of positive samples, which may not always be feasible or sufficient in real-world settings. Following a different path, in this paper, we propose a novel framework for identifying astroturf campaigns based solely on large language models (LLMs), introducing a Balanced Retrieval-Augmented Generation (Balanced RAG) component. Our approach first gives both textual information concerning the posts (in our case tweets) and the user interactions of the social network as input to a language model. Then, through prompt engineering and the proposed Balanced RAG method, it effectively detects coordinated disinformation campaigns on X (Twitter). The proposed framework does not require any training or fine-tuning of the language model. Instead, by strategically harnessing the strengths of prompt engineering and Balanced RAG, it facilitates LLMs to overcome the effects of class imbalance and effectively identify coordinated political campaigns. The experimental results demonstrate that by incorporating the proposed prompt engineering and Balanced RAG methods, our framework outperforms the traditional graph-based baselines, achieving 2x-3x improvements in terms of precision, recall and F1 scores.
Personalized Graph-Based Retrieval for Large Language Models
Jan 04, 2025As large language models (LLMs) evolve, their ability to deliver personalized and context-aware responses offers transformative potential for improving user experiences. Existing personalization approaches, however, often rely solely on user history to augment the prompt, limiting their effectiveness in generating tailored outputs, especially in cold-start scenarios with sparse data. To address these limitations, we propose Personalized Graph-based Retrieval-Augmented Generation (PGraphRAG), a framework that leverages user-centric knowledge graphs to enrich personalization. By directly integrating structured user knowledge into the retrieval process and augmenting prompts with user-relevant context, PGraphRAG enhances contextual understanding and output quality. We also introduce the Personalized Graph-based Benchmark for Text Generation, designed to evaluate personalized text generation tasks in real-world settings where user history is sparse or unavailable. Experimental results show that PGraphRAG significantly outperforms state-of-the-art personalization methods across diverse tasks, demonstrating the unique advantages of graph-based retrieval for personalization.
ICML Topological Deep Learning Challenge 2024: Beyond the Graph Domain
Sep 08, 2024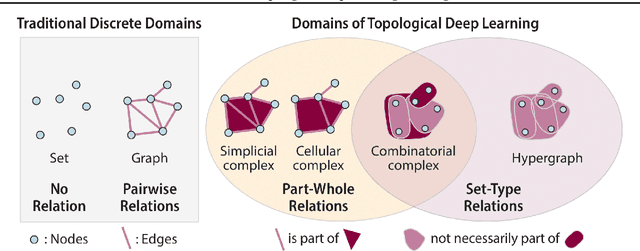
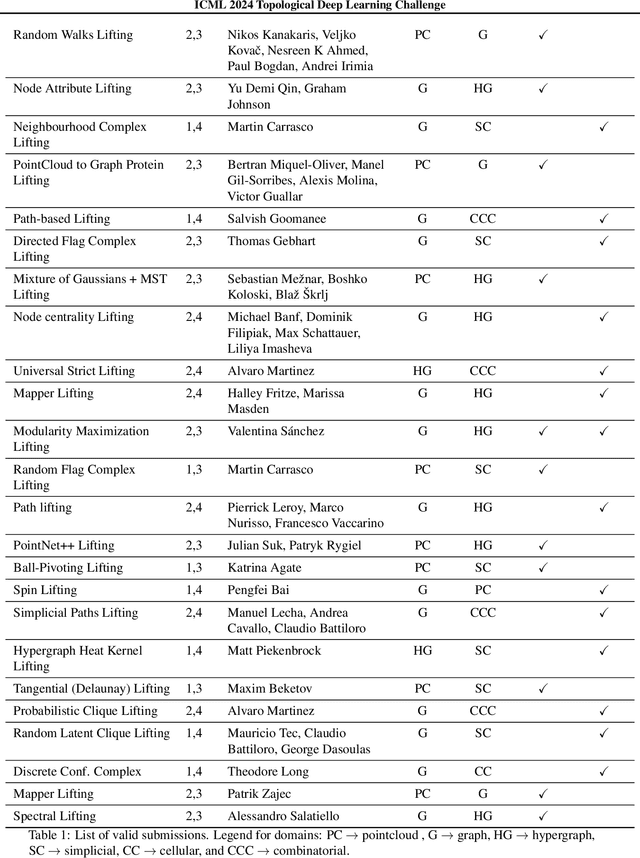
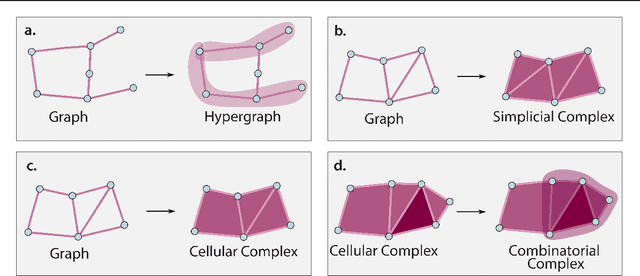
This paper describes the 2nd edition of the ICML Topological Deep Learning Challenge that was hosted within the ICML 2024 ELLIS Workshop on Geometry-grounded Representation Learning and Generative Modeling (GRaM). The challenge focused on the problem of representing data in different discrete topological domains in order to bridge the gap between Topological Deep Learning (TDL) and other types of structured datasets (e.g. point clouds, graphs). Specifically, participants were asked to design and implement topological liftings, i.e. mappings between different data structures and topological domains --like hypergraphs, or simplicial/cell/combinatorial complexes. The challenge received 52 submissions satisfying all the requirements. This paper introduces the main scope of the challenge, and summarizes the main results and findings.
A structure-aware framework for learning device placements on computation graphs
May 23, 2024



Existing approaches for device placement ignore the topological features of computation graphs and rely mostly on heuristic methods for graph partitioning. At the same time, they either follow a grouper-placer or an encoder-placer architecture, which requires understanding the interaction structure between code operations. To bridge the gap between encoder-placer and grouper-placer techniques, we propose a novel framework for the task of device placement, relying on smaller computation graphs extracted from the OpenVINO toolkit using reinforcement learning. The framework consists of five steps, including graph coarsening, node representation learning and policy optimization. It facilitates end-to-end training and takes into consideration the directed and acyclic nature of the computation graphs. We also propose a model variant, inspired by graph parsing networks and complex network analysis, enabling graph representation learning and personalized graph partitioning jointly, using an unspecified number of groups. To train the entire framework, we utilize reinforcement learning techniques by employing the execution time of the suggested device placements to formulate the reward. We demonstrate the flexibility and effectiveness of our approach through multiple experiments with three benchmark models, namely Inception-V3, ResNet, and BERT. The robustness of the proposed framework is also highlighted through an ablation study. The suggested placements improve the inference speed for the benchmark models by up to $58.2\%$ over CPU execution and by up to $60.24\%$ compared to other commonly used baselines.
Leveraging Reinforcement Learning and Large Language Models for Code Optimization
Dec 09, 2023



Code optimization is a daunting task that requires a significant level of expertise from experienced programmers. This level of expertise is not sufficient when compared to the rapid development of new hardware architectures. Towards advancing the whole code optimization process, recent approaches rely on machine learning and artificial intelligence techniques. This paper introduces a new framework to decrease the complexity of code optimization. The proposed framework builds on large language models (LLMs) and reinforcement learning (RL) and enables LLMs to receive feedback from their environment (i.e., unit tests) during the fine-tuning process. We compare our framework with existing state-of-the-art models and show that it is more efficient with respect to speed and computational usage, as a result of the decrement in training steps and its applicability to models with fewer parameters. Additionally, our framework reduces the possibility of logical and syntactical errors. Toward evaluating our approach, we run several experiments on the PIE dataset using a CodeT5 language model and RRHF, a new reinforcement learning algorithm. We adopt a variety of evaluation metrics with regards to optimization quality, and speedup. The evaluation results demonstrate that the proposed framework has similar results in comparison with existing models using shorter training times and smaller pre-trained models. In particular, we accomplish an increase of 5.6% and 2.2 over the baseline models concerning the %OP T and SP metrics.