 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMoE: Eigenbasis-Guided Routing for Mixture-of-Experts
Jan 17, 2026The relentless scaling of deep learning models has led to unsustainable computational demands, positioning Mixture-of-Experts (MoE) architectures as a promising path towards greater efficiency. However, MoE models are plagued by two fundamental challenges: 1) a load imbalance problem known as the``rich get richer" phenomenon, where a few experts are over-utilized, and 2) an expert homogeneity problem, where experts learn redundant representations, negating their purpose. Current solutions typically employ an auxiliary load-balancing loss that, while mitigating imbalance, often exacerbates homogeneity by enforcing uniform routing at the expense of specialization. To resolve this, we introduce the Eigen-Mixture-of-Experts (EMoE), a novel architecture that leverages a routing mechanism based on a learned orthonormal eigenbasis. EMoE projects input tokens onto this shared eigenbasis and routes them based on their alignment with the principal components of the feature space. This principled, geometric partitioning of data intrinsically promotes both balanced expert utilization and the development of diverse, specialized experts, all without the need for a conflicting auxiliary loss function. Our code is publicly available at https://github.com/Belis0811/EMoE.
ERMoE: Eigen-Reparameterized Mixture-of-Experts for Stable Routing and Interpretable Specialization
Nov 14, 2025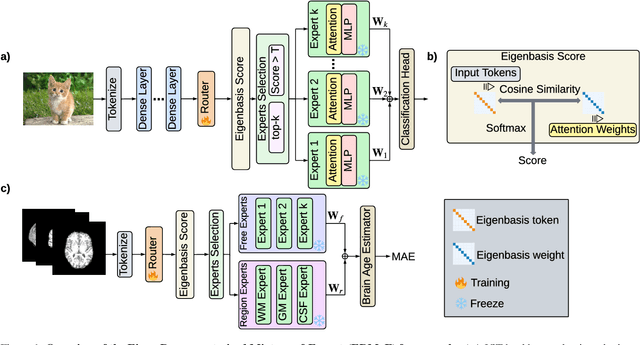
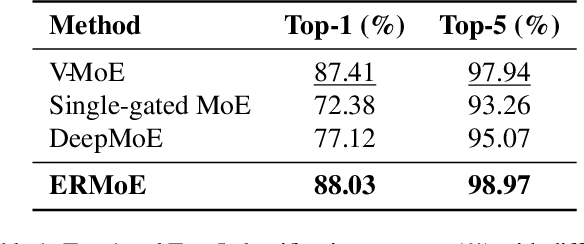
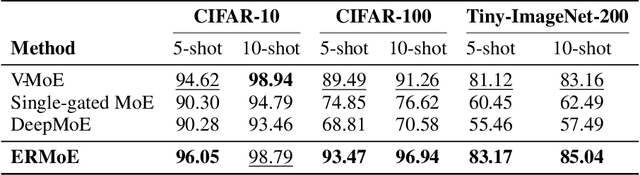
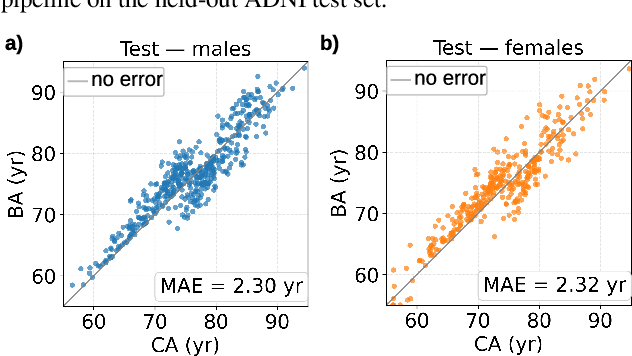
Mixture-of-Experts (MoE) architectures expand model capacity by sparsely activating experts but face two core challenges: misalignment between router logits and each expert's internal structure leads to unstable routing and expert underutilization, and load imbalances create straggler bottlenecks. Standard solutions, such as auxiliary load-balancing losses, can reduce load disparities but often weaken expert specialization and hurt downstream performance. To address these issues, we propose ERMoE, a sparse MoE transformer that reparameterizes each expert in a learned orthonormal eigenbasis and replaces learned gating logits with an "Eigenbasis Score", defined as the cosine similarity between input features and an expert's basis. This content-aware routing ties token assignments directly to experts' representation spaces, stabilizing utilization and promoting interpretable specialization without sacrificing sparsity. Crucially, ERMoE removes the need for explicit balancing losses and avoids the interfering gradients they introduce. We show that ERMoE achieves state-of-the-art accuracy on ImageNet classification and cross-modal image-text retrieval benchmarks (e.g., COCO, Flickr30K), while naturally producing flatter expert load distributions. Moreover, a 3D MRI variant (ERMoE-ba) improves brain age prediction accuracy by more than 7\% and yields anatomically interpretable expert specializations. ERMoE thus introduces a new architectural principle for sparse expert models that directly addresses routing instabilities and enables improved performance with scalable, interpretable specialization.
HDLCoRe: A Training-Free Framework for Mitigating Hallucinations in LLM-Generated HDL
Mar 18, 2025



Recent advances in large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, when applied to hardware description languages (HDL), these models exhibit significant limitations due to data scarcity, resulting in hallucinations and incorrect code generation. To address these challenges, we propose HDLCoRe, a training-free framework that enhances LLMs' HDL generation capabilities through prompt engineering techniques and retrieval-augmented generation (RAG). Our approach consists of two main components: (1) an HDL-aware Chain-of-Thought (CoT) prompting technique with self-verification that classifies tasks by complexity and type, incorporates domain-specific knowledge, and guides LLMs through step-by-step self-simulation for error correction; and (2) a two-stage heterogeneous RAG system that addresses formatting inconsistencies through key component extraction and efficiently retrieves relevant HDL examples through sequential filtering and re-ranking. HDLCoRe eliminates the need for model fine-tuning while substantially improving LLMs' HDL generation capabilities. Experimental results demonstrate that our framework achieves superior performance on the RTLLM2.0 benchmark, significantly reducing hallucinations and improving both syntactic and functional correctness.
A structure-aware framework for learning device placements on computation graphs
May 23, 2024



Existing approaches for device placement ignore the topological features of computation graphs and rely mostly on heuristic methods for graph partitioning. At the same time, they either follow a grouper-placer or an encoder-placer architecture, which requires understanding the interaction structure between code operations. To bridge the gap between encoder-placer and grouper-placer techniques, we propose a novel framework for the task of device placement, relying on smaller computation graphs extracted from the OpenVINO toolkit using reinforcement learning. The framework consists of five steps, including graph coarsening, node representation learning and policy optimization. It facilitates end-to-end training and takes into consideration the directed and acyclic nature of the computation graphs. We also propose a model variant, inspired by graph parsing networks and complex network analysis, enabling graph representation learning and personalized graph partitioning jointly, using an unspecified number of groups. To train the entire framework, we utilize reinforcement learning techniques by employing the execution time of the suggested device placements to formulate the reward. We demonstrate the flexibility and effectiveness of our approach through multiple experiments with three benchmark models, namely Inception-V3, ResNet, and BERT. The robustness of the proposed framework is also highlighted through an ablation study. The suggested placements improve the inference speed for the benchmark models by up to $58.2\%$ over CPU execution and by up to $60.24\%$ compared to other commonly used baselines.
Unlocking Deep Learning: A BP-Free Approach for Parallel Block-Wise Training of Neural Networks
Dec 20, 2023



Backpropagation (BP) has been a successful optimization technique for deep learning models. However, its limitations, such as backward- and update-locking, and its biological implausibility, hinder the concurrent updating of layers and do not mimic the local learning processes observed in the human brain. To address these issues, recent research has suggested using local error signals to asynchronously train network blocks. However, this approach often involves extensive trial-and-error iterations to determine the best configuration for local training. This includes decisions on how to decouple network blocks and which auxiliary networks to use for each block. In our work, we introduce a novel BP-free approach: a block-wise BP-free (BWBPF) neural network that leverages local error signals to optimize distinct sub-neural networks separately, where the global loss is only responsible for updating the output layer. The local error signals used in the BP-free model can be computed in parallel, enabling a potential speed-up in the weight update process through parallel implementation. Our experimental results consistently show that this approach can identify transferable decoupled architectures for VGG and ResNet variations, outperforming models trained with end-to-end backpropagation and other state-of-the-art block-wise learning techniques on datasets such as CIFAR-10 and Tiny-ImageNet. The code is released at https://github.com/Belis0811/BWBPF.
Leveraging Reinforcement Learning and Large Language Models for Code Optimization
Dec 09, 2023



Code optimization is a daunting task that requires a significant level of expertise from experienced programmers. This level of expertise is not sufficient when compared to the rapid development of new hardware architectures. Towards advancing the whole code optimization process, recent approaches rely on machine learning and artificial intelligence techniques. This paper introduces a new framework to decrease the complexity of code optimization. The proposed framework builds on large language models (LLMs) and reinforcement learning (RL) and enables LLMs to receive feedback from their environment (i.e., unit tests) during the fine-tuning process. We compare our framework with existing state-of-the-art models and show that it is more efficient with respect to speed and computational usage, as a result of the decrement in training steps and its applicability to models with fewer parameters. Additionally, our framework reduces the possibility of logical and syntactical errors. Toward evaluating our approach, we run several experiments on the PIE dataset using a CodeT5 language model and RRHF, a new reinforcement learning algorithm. We adopt a variety of evaluation metrics with regards to optimization quality, and speedup. The evaluation results demonstrate that the proposed framework has similar results in comparison with existing models using shorter training times and smaller pre-trained models. In particular, we accomplish an increase of 5.6% and 2.2 over the baseline models concerning the %OP T and SP metrics.
Leader-Follower Neural Networks with Local Error Signals Inspired by Complex Collectives
Oct 11, 2023
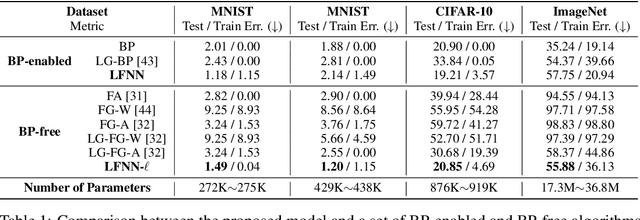


The collective behavior of a network with heterogeneous, resource-limited information processing units (e.g., group of fish, flock of birds, or network of neurons) demonstrates high self-organization and complexity. These emergent properties arise from simple interaction rules where certain individuals can exhibit leadership-like behavior and influence the collective activity of the group. Motivated by the intricacy of these collectives, we propose a neural network (NN) architecture inspired by the rules observed in nature's collective ensembles. This NN structure contains workers that encompass one or more information processing units (e.g., neurons, filters, layers, or blocks of layers). Workers are either leaders or followers, and we train a leader-follower neural network (LFNN) by leveraging local error signals and optionally incorporating backpropagation (BP) and global loss. We investigate worker behavior and evaluate LFNNs through extensive experimentation. Our LFNNs trained with local error signals achieve significantly lower error rates than previous BP-free algorithms on MNIST and CIFAR-10 and even surpass BP-enabled baselines. In the case of ImageNet, our LFNN-l demonstrates superior scalability and outperforms previous BP-free algorithms by a significant margin.
End-to-end Mapping in Heterogeneous Systems Using Graph Representation Learning
Apr 25, 2022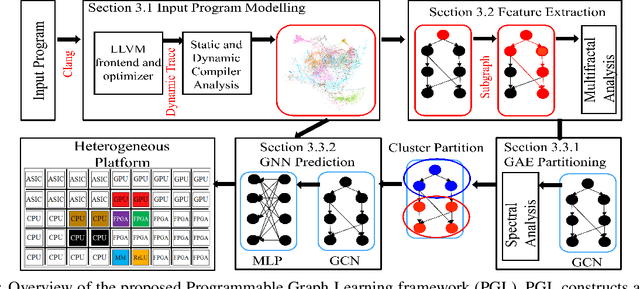
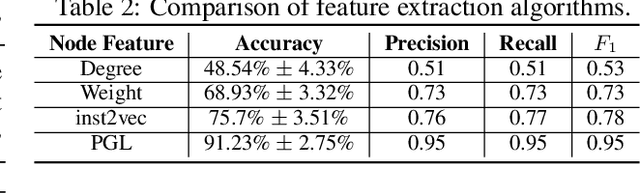
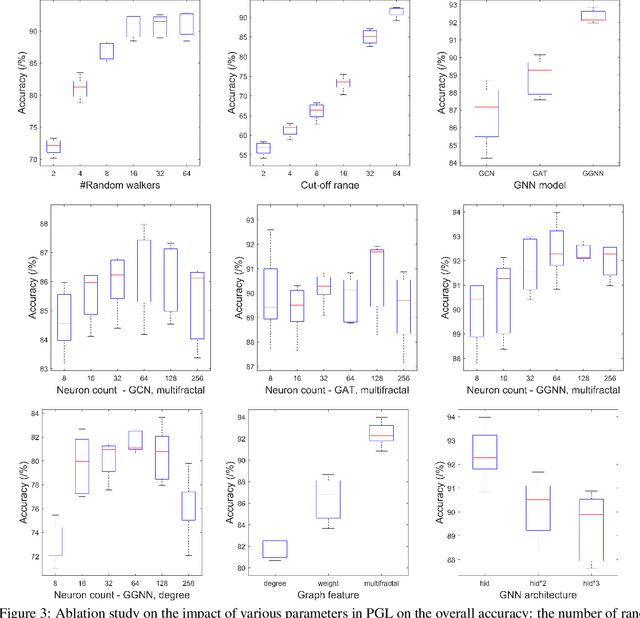
To enable heterogeneous computing systems with autonomous programming and optimization capabilities, we propose a unified, end-to-end, programmable graph representation learning (PGL) framework that is capable of mining the complexity of high-level programs down to the universal intermediate representation, extracting the specific computational patterns and predicting which code segments would run best on a specific core in heterogeneous hardware platforms. The proposed framework extracts multi-fractal topological features from code graphs, utilizes graph autoencoders to learn how to partition the graph into computational kernels, and exploits graph neural networks (GNN) to predict the correct assignment to a processor type. In the evaluation, we validate the PGL framework and demonstrate a maximum speedup of 6.42x compared to the thread-based execution, and 2.02x compared to the state-of-the-art technique.
Trust-aware Control for Intelligent Transportation Systems
Nov 08, 2021



Many intelligent transportation systems are multi-agent systems, i.e., both the traffic participants and the subsystems within the transportation infrastructure can be modeled as interacting agents. The use of AI-based methods to achieve coordination among the different agents systems can provide greater safety over transportation systems containing only human-operated vehicles, and also improve the system efficiency in terms of traffic throughput, sensing range, and enabling collaborative tasks. However, increased autonomy makes the transportation infrastructure vulnerable to compromised vehicular agents or infrastructure. This paper proposes a new framework by embedding the trust authority into transportation infrastructure to systematically quantify the trustworthiness of agents using an epistemic logic known as subjective logic. In this paper, we make the following novel contributions: (i) We propose a framework for using the quantified trustworthiness of agents to enable trust-aware coordination and control. (ii) We demonstrate how to synthesize trust-aware controllers using an approach based on reinforcement learning. (iii) We comprehensively analyze an autonomous intersection management (AIM) case study and develop a trust-aware version called AIM-Trust that leads to lower accident rates in scenarios consisting of a mixture of trusted and untrusted agents.
VRoC: Variational Autoencoder-aided Multi-task Rumor Classifier Based on Text
Jan 28, 2021
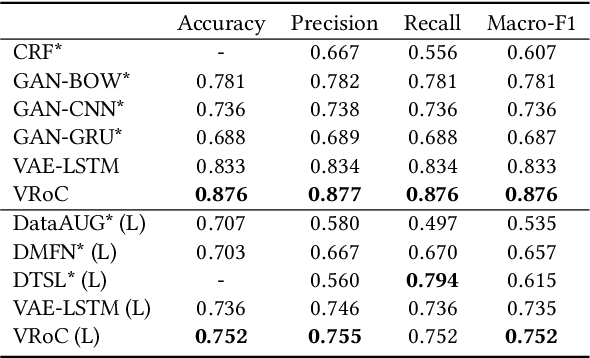

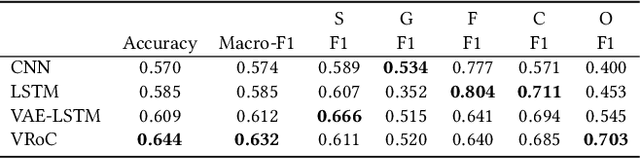
Social media became popular and percolated almost all aspects of our daily lives. While online posting proves very convenient for individual users, it also fosters fast-spreading of various rumors. The rapid and wide percolation of rumors can cause persistent adverse or detrimental impacts. Therefore, researchers invest great efforts on reducing the negative impacts of rumors. Towards this end, the rumor classification system aims to detect, track, and verify rumors in social media. Such systems typically include four components: (i) a rumor detector, (ii) a rumor tracker, (iii) a stance classifier, and (iv) a veracity classifier. In order to improve the state-of-the-art in rumor detection, tracking, and verification, we propose VRoC, a tweet-level variational autoencoder-based rumor classification system. VRoC consists of a co-train engine that trains variational autoencoders (VAEs) and rumor classification components. The co-train engine helps the VAEs to tune their latent representations to be classifier-friendly. We also show that VRoC is able to classify unseen rumors with high levels of accuracy. For the PHEME dataset, VRoC consistently outperforms several state-of-the-art techniques, on both observed and unobserved rumors, by up to 26.9%, in terms of macro-F1 scores.