 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCA-DDReach: Efficient Statistical Reachability Analysis of Stochastic Dynamical Systems via Principal Component Analysis
May 20, 2025This study presents a scalable data-driven algorithm designed to efficiently address the challenging problem of reachability analysis. Analysis of cyber-physical systems (CPS) relies typically on parametric physical models of dynamical systems. However, identifying parametric physical models for complex CPS is challenging due to their complexity, uncertainty, and variability, often rendering them as black-box oracles. As an alternative, one can treat these complex systems as black-box models and use trajectory data sampled from the system (e.g., from high-fidelity simulators or the real system) along with machine learning techniques to learn models that approximate the underlying dynamics. However, these machine learning models can be inaccurate, highlighting the need for statistical tools to quantify errors. Recent advancements in the field include the incorporation of statistical uncertainty quantification tools such as conformal inference (CI) that can provide probabilistic reachable sets with provable guarantees. Recent work has even highlighted the ability of these tools to address the case where the distribution of trajectories sampled during training time are different from the distribution of trajectories encountered during deployment time. However, accounting for such distribution shifts typically results in more conservative guarantees. This is undesirable in practice and motivates us to present techniques that can reduce conservatism. Here, we propose a new approach that reduces conservatism and improves scalability by combining conformal inference with Principal Component Analysis (PCA). We show the effectiveness of our technique on various case studies, including a 12-dimensional quadcopter and a 27-dimensional hybrid system known as the powertrain.
Scaling Learning based Policy Optimization for Temporal Tasks via Dropout
Mar 23, 2024



This paper introduces a model-based approach for training feedback controllers for an autonomous agent operating in a highly nonlinear environment. We desire the trained policy to ensure that the agent satisfies specific task objectives, expressed in discrete-time Signal Temporal Logic (DT-STL). One advantage for reformulation of a task via formal frameworks, like DT-STL, is that it permits quantitative satisfaction semantics. In other words, given a trajectory and a DT-STL formula, we can compute the robustness, which can be interpreted as an approximate signed distance between the trajectory and the set of trajectories satisfying the formula. We utilize feedback controllers, and we assume a feed forward neural network for learning these feedback controllers. We show how this learning problem is similar to training recurrent neural networks (RNNs), where the number of recurrent units is proportional to the temporal horizon of the agent's task objectives. This poses a challenge: RNNs are susceptible to vanishing and exploding gradients, and na\"{i}ve gradient descent-based strategies to solve long-horizon task objectives thus suffer from the same problems. To tackle this challenge, we introduce a novel gradient approximation algorithm based on the idea of dropout or gradient sampling. We show that, the existing smooth semantics for robustness are inefficient regarding gradient computation when the specification becomes complex. To address this challenge, we propose a new smooth semantics for DT-STL that under-approximates the robustness value and scales well for backpropagation over a complex specification. We show that our control synthesis methodology, can be quite helpful for stochastic gradient descent to converge with less numerical issues, enabling scalable backpropagation over long time horizons and trajectories over high dimensional state spaces.
A Neurosymbolic Approach to the Verification of Temporal Logic Properties of Learning enabled Control Systems
Mar 07, 2023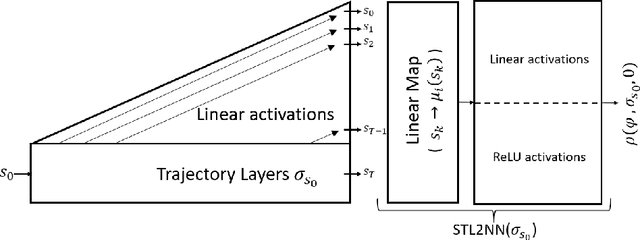

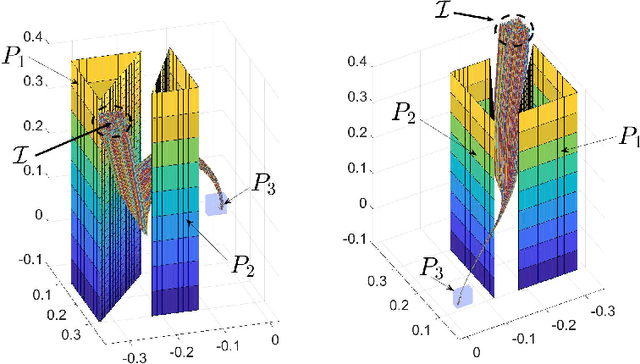
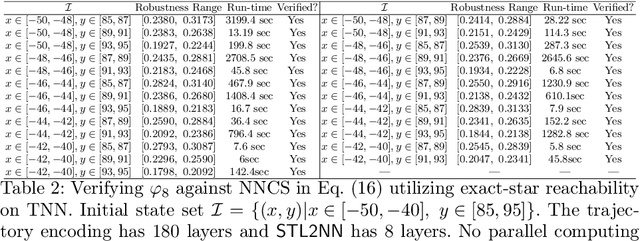
Signal Temporal Logic (STL) has become a popular tool for expressing formal requirements of Cyber-Physical Systems (CPS). The problem of verifying STL properties of neural network-controlled CPS remains a largely unexplored problem. In this paper, we present a model for the verification of Neural Network (NN) controllers for general STL specifications using a custom neural architecture where we map an STL formula into a feed-forward neural network with ReLU activation. In the case where both our plant model and the controller are ReLU-activated neural networks, we reduce the STL verification problem to reachability in ReLU neural networks. We also propose a new approach for neural network controllers with general activation functions; this approach is a sound and complete verification approach based on computing the Lipschitz constant of the closed-loop control system. We demonstrate the practical efficacy of our techniques on a number of examples of learning-enabled control systems.
Model-Free Reinforcement Learning for Symbolic Automata-encoded Objectives
Feb 04, 2022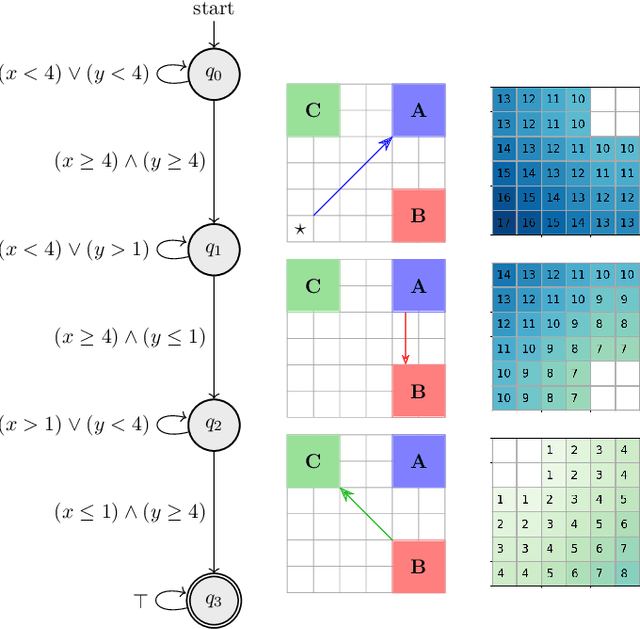
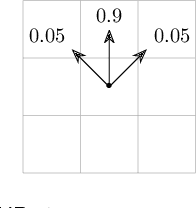
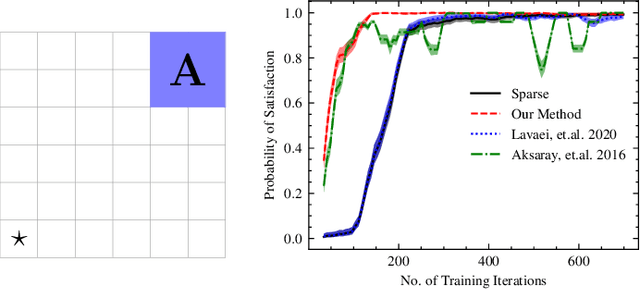
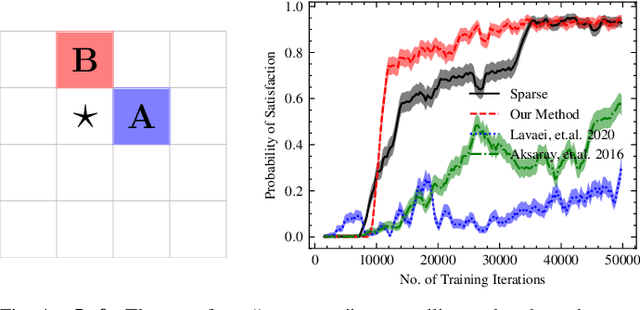
Reinforcement learning (RL) is a popular approach for robotic path planning in uncertain environments. However, the control policies trained for an RL agent crucially depend on user-defined, state-based reward functions. Poorly designed rewards can lead to policies that do get maximal rewards but fail to satisfy desired task objectives or are unsafe. There are several examples of the use of formal languages such as temporal logics and automata to specify high-level task specifications for robots (in lieu of Markovian rewards). Recent efforts have focused on inferring state-based rewards from formal specifications; here, the goal is to provide (probabilistic) guarantees that the policy learned using RL (with the inferred rewards) satisfies the high-level formal specification. A key drawback of several of these techniques is that the rewards that they infer are sparse: the agent receives positive rewards only upon completion of the task and no rewards otherwise. This naturally leads to poor convergence properties and high variance during RL. In this work, we propose using formal specifications in the form of symbolic automata: these serve as a generalization of both bounded-time temporal logic-based specifications as well as automata. Furthermore, our use of symbolic automata allows us to define non-sparse potential-based rewards which empirically shape the reward surface, leading to better convergence during RL. We also show that our potential-based rewarding strategy still allows us to obtain the policy that maximizes the satisfaction of the given specification.
Trust-aware Control for Intelligent Transportation Systems
Nov 08, 2021



Many intelligent transportation systems are multi-agent systems, i.e., both the traffic participants and the subsystems within the transportation infrastructure can be modeled as interacting agents. The use of AI-based methods to achieve coordination among the different agents systems can provide greater safety over transportation systems containing only human-operated vehicles, and also improve the system efficiency in terms of traffic throughput, sensing range, and enabling collaborative tasks. However, increased autonomy makes the transportation infrastructure vulnerable to compromised vehicular agents or infrastructure. This paper proposes a new framework by embedding the trust authority into transportation infrastructure to systematically quantify the trustworthiness of agents using an epistemic logic known as subjective logic. In this paper, we make the following novel contributions: (i) We propose a framework for using the quantified trustworthiness of agents to enable trust-aware coordination and control. (ii) We demonstrate how to synthesize trust-aware controllers using an approach based on reinforcement learning. (iii) We comprehensively analyze an autonomous intersection management (AIM) case study and develop a trust-aware version called AIM-Trust that leads to lower accident rates in scenarios consisting of a mixture of trusted and untrusted agents.
PerceMon: Online Monitoring for Perception Systems
Aug 17, 2021


Perception algorithms in autonomous vehicles are vital for the vehicle to understand the semantics of its surroundings, including detection and tracking of objects in the environment. The outputs of these algorithms are in turn used for decision-making in safety-critical scenarios like collision avoidance, and automated emergency braking. Thus, it is crucial to monitor such perception systems at runtime. However, due to the high-level, complex representations of the outputs of perception systems, it is a challenge to test and verify these systems, especially at runtime. In this paper, we present a runtime monitoring tool, PerceMon that can monitor arbitrary specifications in Timed Quality Temporal Logic (TQTL) and its extensions with spatial operators. We integrate the tool with the CARLA autonomous vehicle simulation environment and the ROS middleware platform while monitoring properties on state-of-the-art object detection and tracking algorithms.
Automatic Testing and Falsification with Dynamically Constrained Reinforcement Learning
Oct 30, 2019
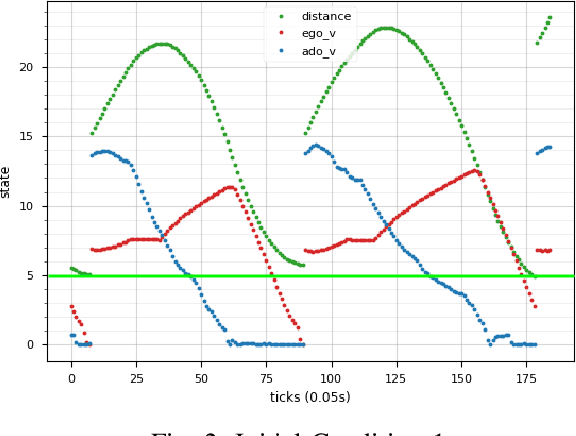
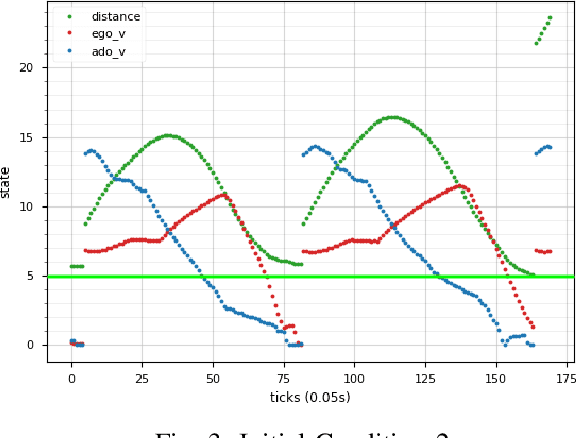
We consider the problem of using reinforcement learning to train adversarial agents for automatic testing and falsification of cyberphysical systems, such as autonomous vehicles, robots, and airplanes. In order to produce useful agents, however, it is useful to be able to control the degree of adversariality by specifying rules that an agent must follow. For example, when testing an autonomous vehicle, it is useful to find maximally antagonistic traffic participants that obey traffic rules. We model dynamic constraints as hierarchically ordered rules expressed in Signal Temporal Logic, and show how these can be incorporated into an agent training process. We prove that our agent-centric approach is able to find all dangerous behaviors that can be found by traditional falsification techniques while producing modular and reusable agents. We demonstrate our approach on two case studies from the automotive domain.
Using Logical Specifications of Objectives in Multi-Objective Reinforcement Learning
Oct 03, 2019
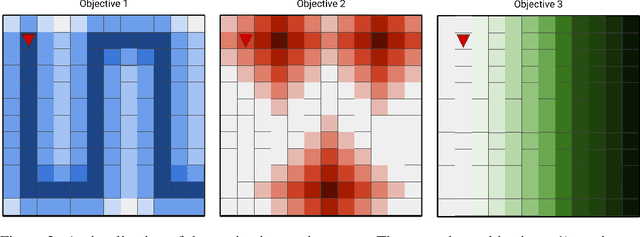

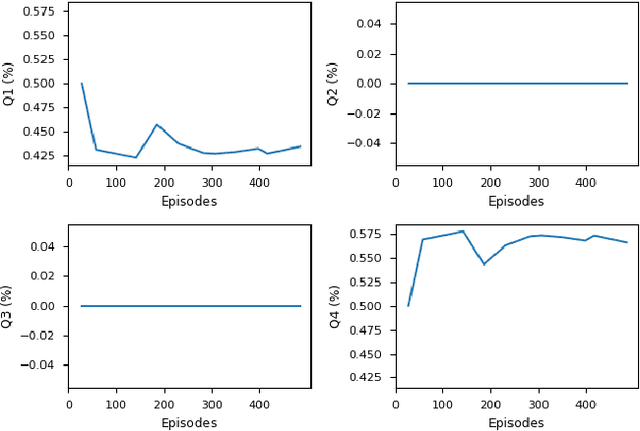
In the multi-objective reinforcement learning (MORL) paradigm, the relative importance of each environment objective is often unknown prior to training, so agents must learn to specialize their behavior to optimize different combinations of environment objectives that are specified post-training. These are typically linear combinations, so the agent is effectively parameterized by a weight vector that describes how to balance competing environment objectives. However, many real world behaviors require non-linear combinations of objectives. Additionally, the conversion between desired behavior and weightings is often unclear. In this work, we explore the use of a language based on propositional logic with quantitative semantics--in place of weight vectors--for specifying non-linear behaviors in an interpretable way. We use a recurrent encoder to encode logical combinations of objectives, and train a MORL agent to generalize over these encodings. We test our agent in several grid worlds with various objectives and show that our agent can generalize to many never-before-seen specifications with performance comparable to single policy baseline agents. We also demonstrate our agent's ability to generate meaningful policies when presented with novel specifications and quickly specialize to novel specifications.
Shield Synthesis for Real: Enforcing Safety in Cyber-Physical Systems
Aug 15, 2019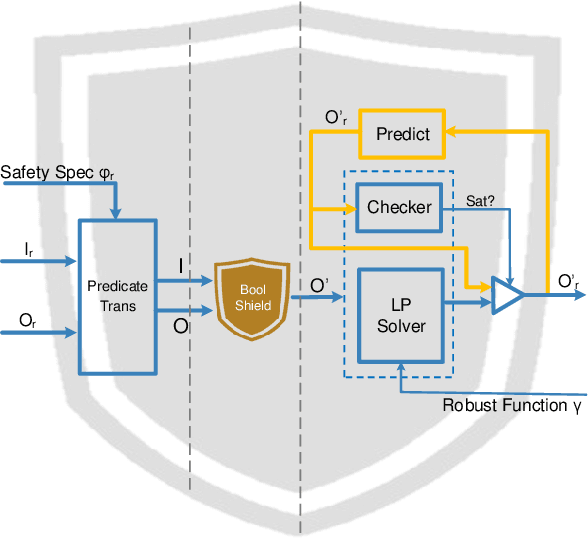
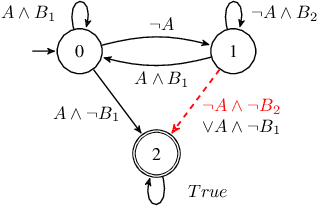
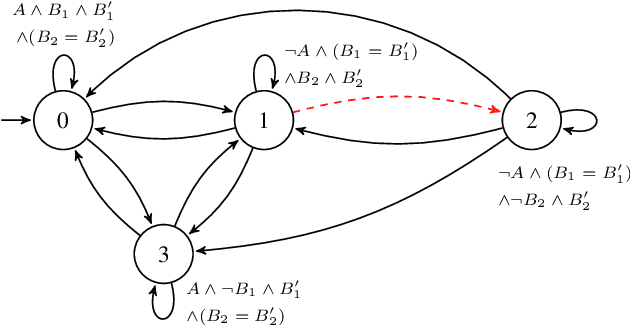
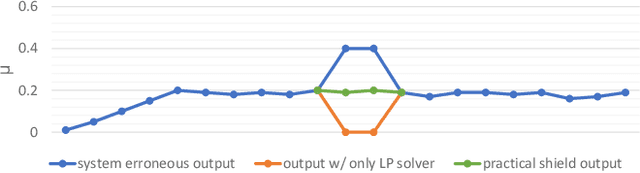
Cyber-physical systems are often safety-critical in that violations of safety properties may lead to catastrophes. We propose a method to enforce the safety of systems with real-valued signals by synthesizing a runtime enforcer called the shield. Whenever the system violates a property, the shield, composed with the system, makes correction instantaneously to ensure that no erroneous output is generated by the combined system. While techniques for synthesizing Boolean shields are well understood, they do not handle real-valued signals ubiquitous in cyber-physical systems, meaning corrections may be either unrealizable or inefficient to compute in the real domain. We solve the realizability and efficiency problems by statically analyzing the compatibility of predicates defined over real-valued signals, and using the analysis result to constrain a two-player safety game used to synthesize the shield. We have implemented the method and demonstrated its effectiveness and efficiency on a variety of applications, including an automotive powertrain control system.