 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent Path Finding for Timed Tasks using Evolutionary Games
Nov 15, 2024Autonomous multi-agent systems such as hospital robots and package delivery drones often operate in highly uncertain environments and are expected to achieve complex temporal task objectives while ensuring safety. While learning-based methods such as reinforcement learning are popular methods to train single and multi-agent autonomous systems under user-specified and state-based reward functions, applying these methods to satisfy trajectory-level task objectives is a challenging problem. Our first contribution is the use of weighted automata to specify trajectory-level objectives, such that, maximal paths induced in the weighted automaton correspond to desired trajectory-level behaviors. We show how weighted automata-based specifications go beyond timeliness properties focused on deadlines to performance properties such as expeditiousness. Our second contribution is the use of evolutionary game theory (EGT) principles to train homogeneous multi-agent teams targeting homogeneous task objectives. We show how shared experiences of agents and EGT-based policy updates allow us to outperform state-of-the-art reinforcement learning (RL) methods in minimizing path length by nearly 30\% in large spaces. We also show that our algorithm is computationally faster than deep RL methods by at least an order of magnitude. Additionally our results indicate that it scales better with an increase in the number of agents as compared to other methods.
Motion Planning for Automata-based Objectives using Efficient Gradient-based Methods
Oct 15, 2024



In recent years, there has been increasing interest in using formal methods-based techniques to safely achieve temporal tasks, such as timed sequence of goals, or patrolling objectives. Such tasks are often expressed in real-time logics such as Signal Temporal Logic (STL), whereby, the logical specification is encoded into an optimization problem. Such approaches usually involve optimizing over the quantitative semantics, or robustness degree, of the logic over bounded horizons: the semantics can be encoded as mixed-integer linear constraints or into smooth approximations of the robustness degree. A major limitation of this approach is that it faces scalability challenges with respect to temporal complexity: for example, encoding long-term tasks requires storing the entire history of the system. In this paper, we present a quantitative generalization of such tasks in the form of symbolic automata objectives. Specifically, we show that symbolic automata can be expressed as matrix operators that lend themselves to automatic differentiation, allowing for the use of off-the-shelf gradient-based optimizers. We show how this helps solve the need to store arbitrarily long system trajectories, while efficiently leveraging the task structure encoded in the automaton.
Model-Free Reinforcement Learning for Symbolic Automata-encoded Objectives
Feb 04, 2022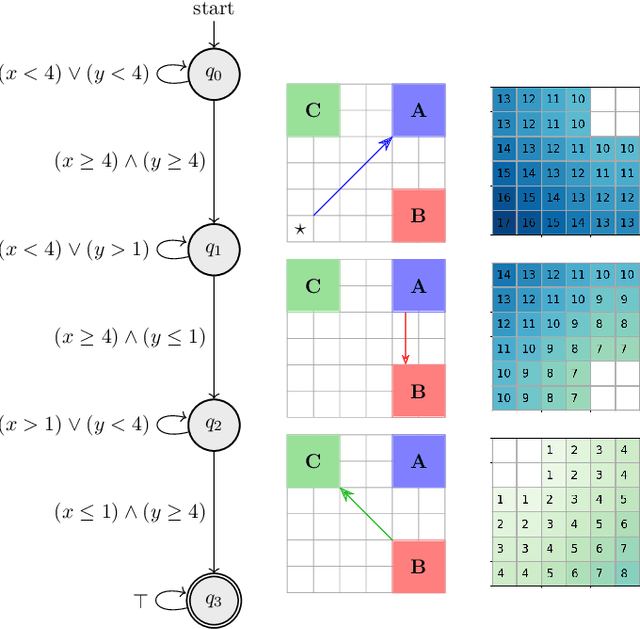
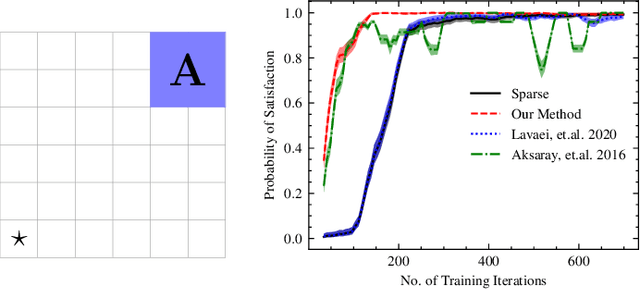
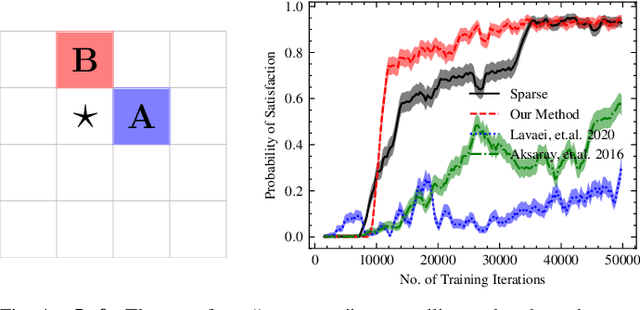
Reinforcement learning (RL) is a popular approach for robotic path planning in uncertain environments. However, the control policies trained for an RL agent crucially depend on user-defined, state-based reward functions. Poorly designed rewards can lead to policies that do get maximal rewards but fail to satisfy desired task objectives or are unsafe. There are several examples of the use of formal languages such as temporal logics and automata to specify high-level task specifications for robots (in lieu of Markovian rewards). Recent efforts have focused on inferring state-based rewards from formal specifications; here, the goal is to provide (probabilistic) guarantees that the policy learned using RL (with the inferred rewards) satisfies the high-level formal specification. A key drawback of several of these techniques is that the rewards that they infer are sparse: the agent receives positive rewards only upon completion of the task and no rewards otherwise. This naturally leads to poor convergence properties and high variance during RL. In this work, we propose using formal specifications in the form of symbolic automata: these serve as a generalization of both bounded-time temporal logic-based specifications as well as automata. Furthermore, our use of symbolic automata allows us to define non-sparse potential-based rewards which empirically shape the reward surface, leading to better convergence during RL. We also show that our potential-based rewarding strategy still allows us to obtain the policy that maximizes the satisfaction of the given specification.
PerceMon: Online Monitoring for Perception Systems
Aug 17, 2021


Perception algorithms in autonomous vehicles are vital for the vehicle to understand the semantics of its surroundings, including detection and tracking of objects in the environment. The outputs of these algorithms are in turn used for decision-making in safety-critical scenarios like collision avoidance, and automated emergency braking. Thus, it is crucial to monitor such perception systems at runtime. However, due to the high-level, complex representations of the outputs of perception systems, it is a challenge to test and verify these systems, especially at runtime. In this paper, we present a runtime monitoring tool, PerceMon that can monitor arbitrary specifications in Timed Quality Temporal Logic (TQTL) and its extensions with spatial operators. We integrate the tool with the CARLA autonomous vehicle simulation environment and the ROS middleware platform while monitoring properties on state-of-the-art object detection and tracking algorithms.
Model-based Reinforcement Learning from Signal Temporal Logic Specifications
Nov 10, 2020
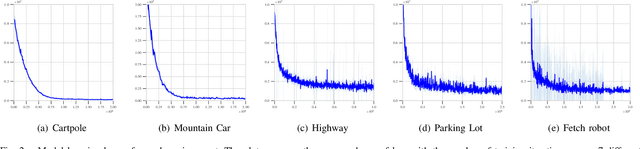

Techniques based on Reinforcement Learning (RL) are increasingly being used to design control policies for robotic systems. RL fundamentally relies on state-based reward functions to encode desired behavior of the robot and bad reward functions are prone to exploitation by the learning agent, leading to behavior that is undesirable in the best case and critically dangerous in the worst. On the other hand, designing good reward functions for complex tasks is a challenging problem. In this paper, we propose expressing desired high-level robot behavior using a formal specification language known as Signal Temporal Logic (STL) as an alternative to reward/cost functions. We use STL specifications in conjunction with model-based learning to design model predictive controllers that try to optimize the satisfaction of the STL specification over a finite time horizon. The proposed algorithm is empirically evaluated on simulations of robotic system such as a pick-and-place robotic arm, and adaptive cruise control for autonomous vehicles.
Using Logical Specifications of Objectives in Multi-Objective Reinforcement Learning
Oct 03, 2019
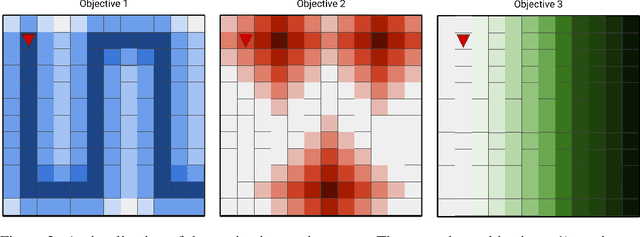
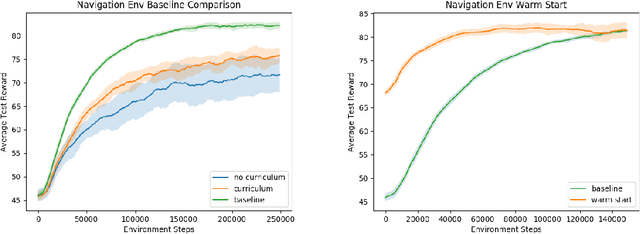

In the multi-objective reinforcement learning (MORL) paradigm, the relative importance of each environment objective is often unknown prior to training, so agents must learn to specialize their behavior to optimize different combinations of environment objectives that are specified post-training. These are typically linear combinations, so the agent is effectively parameterized by a weight vector that describes how to balance competing environment objectives. However, many real world behaviors require non-linear combinations of objectives. Additionally, the conversion between desired behavior and weightings is often unclear. In this work, we explore the use of a language based on propositional logic with quantitative semantics--in place of weight vectors--for specifying non-linear behaviors in an interpretable way. We use a recurrent encoder to encode logical combinations of objectives, and train a MORL agent to generalize over these encodings. We test our agent in several grid worlds with various objectives and show that our agent can generalize to many never-before-seen specifications with performance comparable to single policy baseline agents. We also demonstrate our agent's ability to generate meaningful policies when presented with novel specifications and quickly specialize to novel specifications.
Augmenting Visual SLAM with Wi-Fi Sensing For Indoor Applications
Mar 15, 2019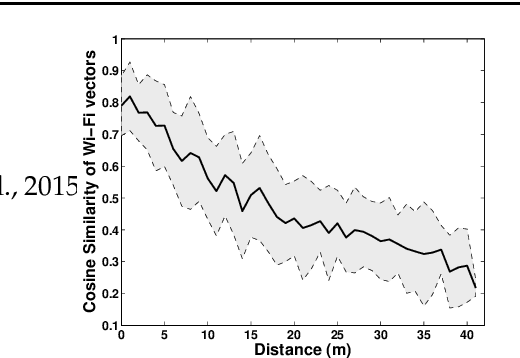

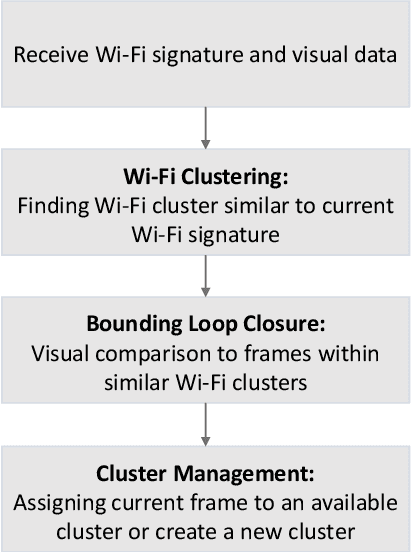
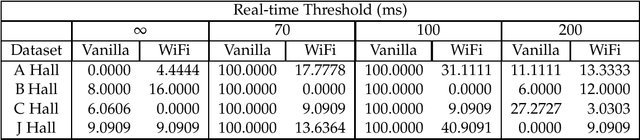
Recent trends have accelerated the development of spatial applications on mobile devices and robots. These include navigation, augmented reality, human-robot interaction, and others. A key enabling technology for such applications is the understanding of the device's location and the map of the surrounding environment. This generic problem, referred to as Simultaneous Localization and Mapping (SLAM), is an extensively researched topic in robotics. However, visual SLAM algorithms face several challenges including perceptual aliasing and high computational cost. These challenges affect the accuracy, efficiency, and viability of visual SLAM algorithms, especially for long-term SLAM, and their use in resource-constrained mobile devices. A parallel trend is the ubiquity of Wi-Fi routers for quick Internet access in most urban environments. Most robots and mobile devices are equipped with a Wi-Fi radio as well. We propose a method to utilize Wi-Fi received signal strength to alleviate the challenges faced by visual SLAM algorithms. To demonstrate the utility of this idea, this work makes the following contributions: (i) We propose a generic way to integrate Wi-Fi sensing into visual SLAM algorithms, (ii) We integrate such sensing into three well-known SLAM algorithms, (iii) Using four distinct datasets, we demonstrate the performance of such augmentation in comparison to the original visual algorithms and (iv) We compare our work to Wi-Fi augmented FABMAP algorithm. Overall, we show that our approach can improve the accuracy of visual SLAM algorithms by 11% on average and reduce computation time on average by 15% to 25%.