 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScenario-Based Curriculum Generation for Multi-Agent Autonomous Driving
Mar 26, 2024The automated generation of diverse and complex training scenarios has been an important ingredient in many complex learning tasks. Especially in real-world application domains, such as autonomous driving, auto-curriculum generation is considered vital for obtaining robust and general policies. However, crafting traffic scenarios with multiple, heterogeneous agents is typically considered as a tedious and time-consuming task, especially in more complex simulation environments. In our work, we introduce MATS-Gym, a Multi-Agent Traffic Scenario framework to train agents in CARLA, a high-fidelity driving simulator. MATS-Gym is a multi-agent training framework for autonomous driving that uses partial scenario specifications to generate traffic scenarios with variable numbers of agents. This paper unifies various existing approaches to traffic scenario description into a single training framework and demonstrates how it can be integrated with techniques from unsupervised environment design to automate the generation of adaptive auto-curricula. The code is available at https://github.com/AutonomousDrivingExaminer/mats-gym.
Model-Free Reinforcement Learning for Symbolic Automata-encoded Objectives
Feb 04, 2022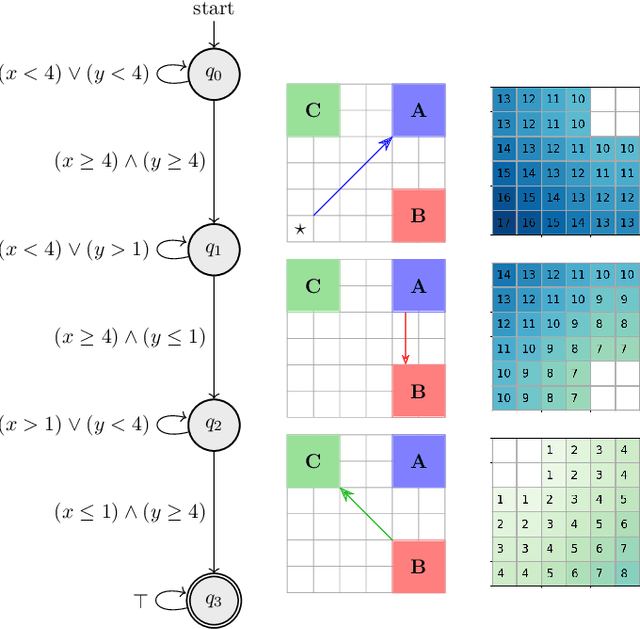
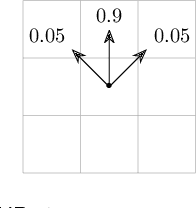
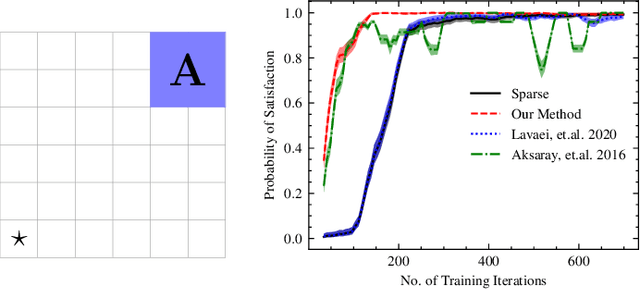
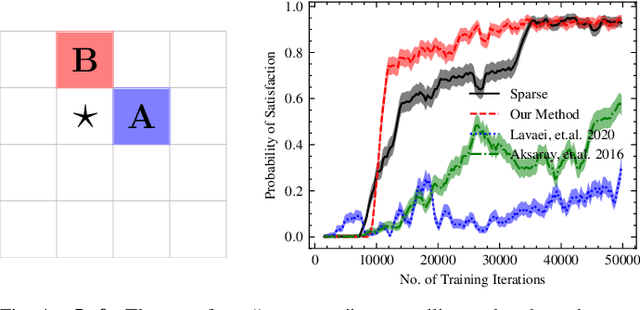
Reinforcement learning (RL) is a popular approach for robotic path planning in uncertain environments. However, the control policies trained for an RL agent crucially depend on user-defined, state-based reward functions. Poorly designed rewards can lead to policies that do get maximal rewards but fail to satisfy desired task objectives or are unsafe. There are several examples of the use of formal languages such as temporal logics and automata to specify high-level task specifications for robots (in lieu of Markovian rewards). Recent efforts have focused on inferring state-based rewards from formal specifications; here, the goal is to provide (probabilistic) guarantees that the policy learned using RL (with the inferred rewards) satisfies the high-level formal specification. A key drawback of several of these techniques is that the rewards that they infer are sparse: the agent receives positive rewards only upon completion of the task and no rewards otherwise. This naturally leads to poor convergence properties and high variance during RL. In this work, we propose using formal specifications in the form of symbolic automata: these serve as a generalization of both bounded-time temporal logic-based specifications as well as automata. Furthermore, our use of symbolic automata allows us to define non-sparse potential-based rewards which empirically shape the reward surface, leading to better convergence during RL. We also show that our potential-based rewarding strategy still allows us to obtain the policy that maximizes the satisfaction of the given specification.