 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Offline Reinforcement Learning for Mean Field Games
Oct 23, 2024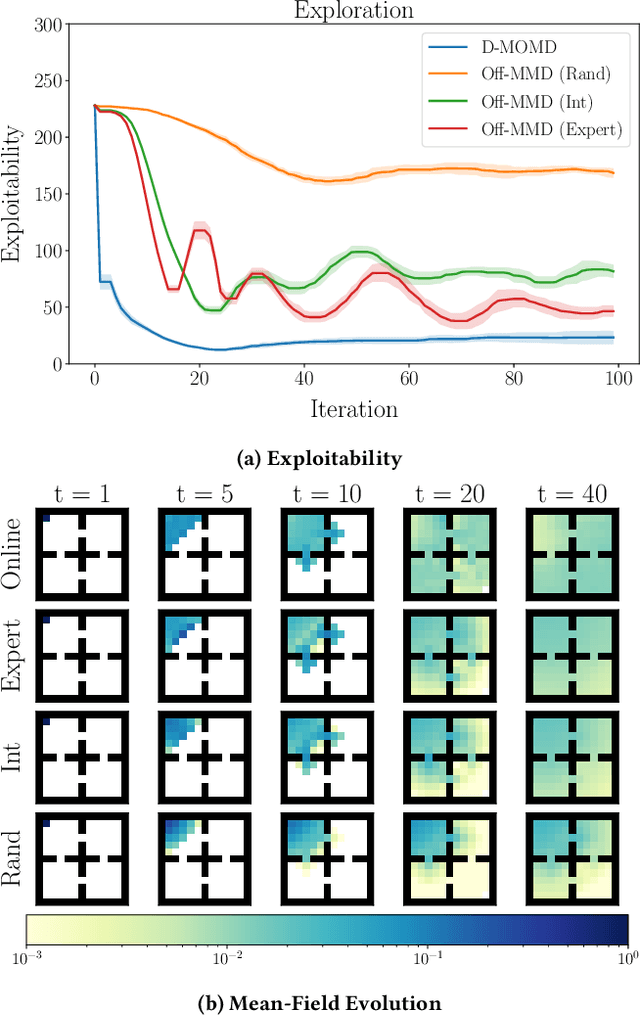



Reinforcement learning algorithms for mean-field games offer a scalable framework for optimizing policies in large populations of interacting agents. Existing methods often depend on online interactions or access to system dynamics, limiting their practicality in real-world scenarios where such interactions are infeasible or difficult to model. In this paper, we present Offline Munchausen Mirror Descent (Off-MMD), a novel mean-field RL algorithm that approximates equilibrium policies in mean-field games using purely offline data. By leveraging iterative mirror descent and importance sampling techniques, Off-MMD estimates the mean-field distribution from static datasets without relying on simulation or environment dynamics. Additionally, we incorporate techniques from offline reinforcement learning to address common issues like Q-value overestimation, ensuring robust policy learning even with limited data coverage. Our algorithm scales to complex environments and demonstrates strong performance on benchmark tasks like crowd exploration or navigation, highlighting its applicability to real-world multi-agent systems where online experimentation is infeasible. We empirically demonstrate the robustness of Off-MMD to low-quality datasets and conduct experiments to investigate its sensitivity to hyperparameter choices.
Scenario-Based Curriculum Generation for Multi-Agent Autonomous Driving
Mar 26, 2024The automated generation of diverse and complex training scenarios has been an important ingredient in many complex learning tasks. Especially in real-world application domains, such as autonomous driving, auto-curriculum generation is considered vital for obtaining robust and general policies. However, crafting traffic scenarios with multiple, heterogeneous agents is typically considered as a tedious and time-consuming task, especially in more complex simulation environments. In our work, we introduce MATS-Gym, a Multi-Agent Traffic Scenario framework to train agents in CARLA, a high-fidelity driving simulator. MATS-Gym is a multi-agent training framework for autonomous driving that uses partial scenario specifications to generate traffic scenarios with variable numbers of agents. This paper unifies various existing approaches to traffic scenario description into a single training framework and demonstrates how it can be integrated with techniques from unsupervised environment design to automate the generation of adaptive auto-curricula. The code is available at https://github.com/AutonomousDrivingExaminer/mats-gym.
From STL Rulebooks to Rewards
Oct 06, 2021



The automatic synthesis of neural-network controllers for autonomous agents through reinforcement learning has to simultaneously optimize many, possibly conflicting, objectives of various importance. This multi-objective optimization task is reflected in the shape of the reward function, which is most often the result of an ad-hoc and crafty-like activity. In this paper we propose a principled approach to shaping rewards for reinforcement learning from multiple objectives that are given as a partially-ordered set of signal-temporal-logic (STL) rules. To this end, we first equip STL with a novel quantitative semantics allowing to automatically evaluate individual requirements. We then develop a method for systematically combining evaluations of multiple requirements into a single reward that takes into account the priorities defined by the partial order. We finally evaluate our approach on several case studies, demonstrating its practical applicability.
Model-based versus Model-free Deep Reinforcement Learning for Autonomous Racing Cars
Mar 08, 2021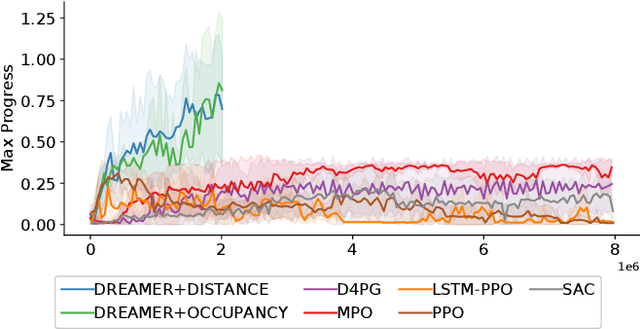
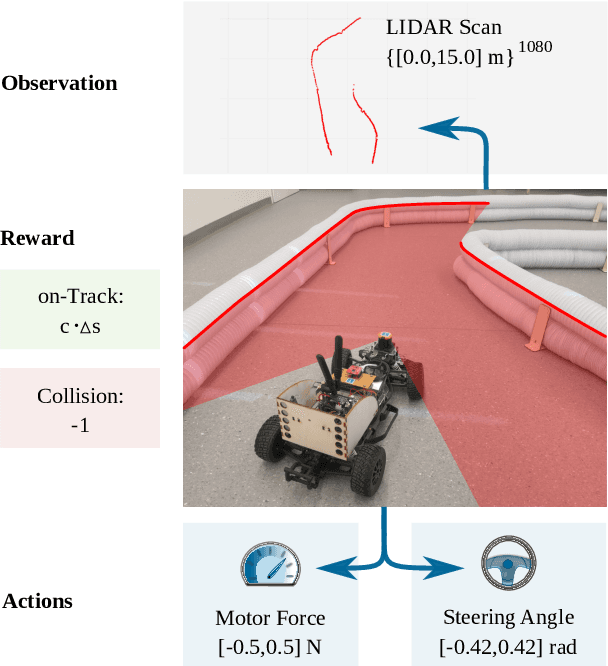

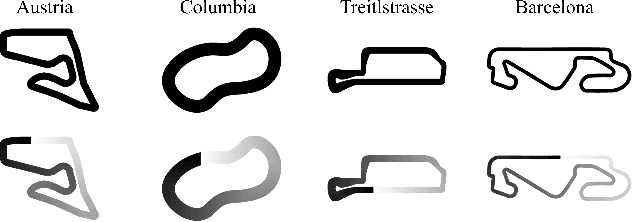
Despite the rich theoretical foundation of model-based deep reinforcement learning (RL) agents, their effectiveness in real-world robotics-applications is less studied and understood. In this paper, we, therefore, investigate how such agents generalize to real-world autonomous-vehicle control-tasks, where advanced model-free deep RL algorithms fail. In particular, we set up a series of time-lap tasks for an F1TENTH racing robot, equipped with high-dimensional LiDAR sensors, on a set of test tracks with a gradual increase in their complexity. In this continuous-control setting, we show that model-based agents capable of learning in imagination, substantially outperform model-free agents with respect to performance, sample efficiency, successful task completion, and generalization. Moreover, we show that the generalization ability of model-based agents strongly depends on the observation-model choice. Finally, we provide extensive empirical evidence for the effectiveness of model-based agents provided with long enough memory horizons in sim2real tasks.