 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling and analysis of the 8 filters from the "master key filters hypothesis" for depthwise-separable deep networks in relation to idealized receptive fields based on scale-space theory
Sep 16, 2025This paper presents the results of analysing and modelling a set of 8 ``master key filters'', which have been extracted by applying a clustering approach to the receptive fields learned in depthwise-separable deep networks based on the ConvNeXt architecture. For this purpose, we first compute spatial spread measures in terms of weighted mean values and weighted variances of the absolute values of the learned filters, which support the working hypotheses that: (i) the learned filters can be modelled by separable filtering operations over the spatial domain, and that (ii) the spatial offsets of the those learned filters that are non-centered are rather close to half a grid unit. Then, we model the clustered ``master key filters'' in terms of difference operators applied to a spatial smoothing operation in terms of the discrete analogue of the Gaussian kernel, and demonstrate that the resulting idealized models of the receptive fields show good qualitative similarity to the learned filters. This modelling is performed in two different ways: (i) using possibly different values of the scale parameters in the coordinate directions for each filter, and (ii) using the same value of the scale parameter in both coordinate directions. Then, we perform the actual model fitting by either (i) requiring spatial spread measures in terms of spatial variances of the absolute values of the receptive fields to be equal, or (ii) minimizing the discrete $l_1$- or $l_2$-norms between the idealized receptive field models and the learned filters. Complementary experimental results then demonstrate the idealized models of receptive fields have good predictive properties for replacing the learned filters by idealized filters in depthwise-separable deep networks, thus showing that the learned filters in depthwise-separable deep networks can be well approximated by discrete scale-space filters.
Visual Graph Arena: Evaluating Visual Conceptualization of Vision and Multimodal Large Language Models
Jun 06, 2025Recent advancements in multimodal large language models have driven breakthroughs in visual question answering. Yet, a critical gap persists, `conceptualization'-the ability to recognize and reason about the same concept despite variations in visual form, a basic ability of human reasoning. To address this challenge, we introduce the Visual Graph Arena (VGA), a dataset featuring six graph-based tasks designed to evaluate and improve AI systems' capacity for visual abstraction. VGA uses diverse graph layouts (e.g., Kamada-Kawai vs. planar) to test reasoning independent of visual form. Experiments with state-of-the-art vision models and multimodal LLMs reveal a striking divide: humans achieved near-perfect accuracy across tasks, while models totally failed on isomorphism detection and showed limited success in path/cycle tasks. We further identify behavioral anomalies suggesting pseudo-intelligent pattern matching rather than genuine understanding. These findings underscore fundamental limitations in current AI models for visual understanding. By isolating the challenge of representation-invariant reasoning, the VGA provides a framework to drive progress toward human-like conceptualization in AI visual models. The Visual Graph Arena is available at: \href{https://vga.csail.mit.edu/}{vga.csail.mit.edu}
The Master Key Filters Hypothesis: Deep Filters Are General in DS-CNNs
Dec 21, 2024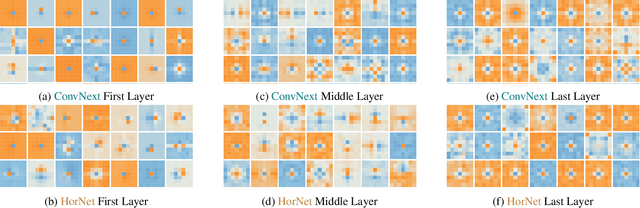
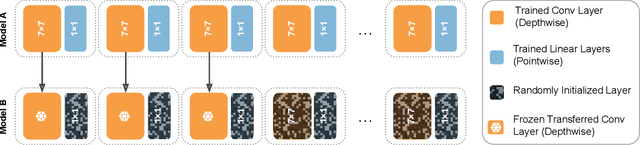
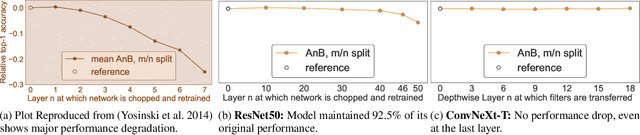
This paper challenges the prevailing view that convolutional neural network (CNN) filters become increasingly specialized in deeper layers. Motivated by recent observations of clusterable repeating patterns in depthwise separable CNNs (DS-CNNs) trained on ImageNet, we extend this investigation across various domains and datasets. Our analysis of DS-CNNs reveals that deep filters maintain generality, contradicting the expected transition to class-specific filters. We demonstrate the generalizability of these filters through transfer learning experiments, showing that frozen filters from models trained on different datasets perform well and can be further improved when sourced from larger datasets. Our findings indicate that spatial features learned by depthwise separable convolutions remain generic across all layers, domains, and architectures. This research provides new insights into the nature of generalization in neural networks, particularly in DS-CNNs, and has significant implications for transfer learning and model design.
Scalable Offline Reinforcement Learning for Mean Field Games
Oct 23, 2024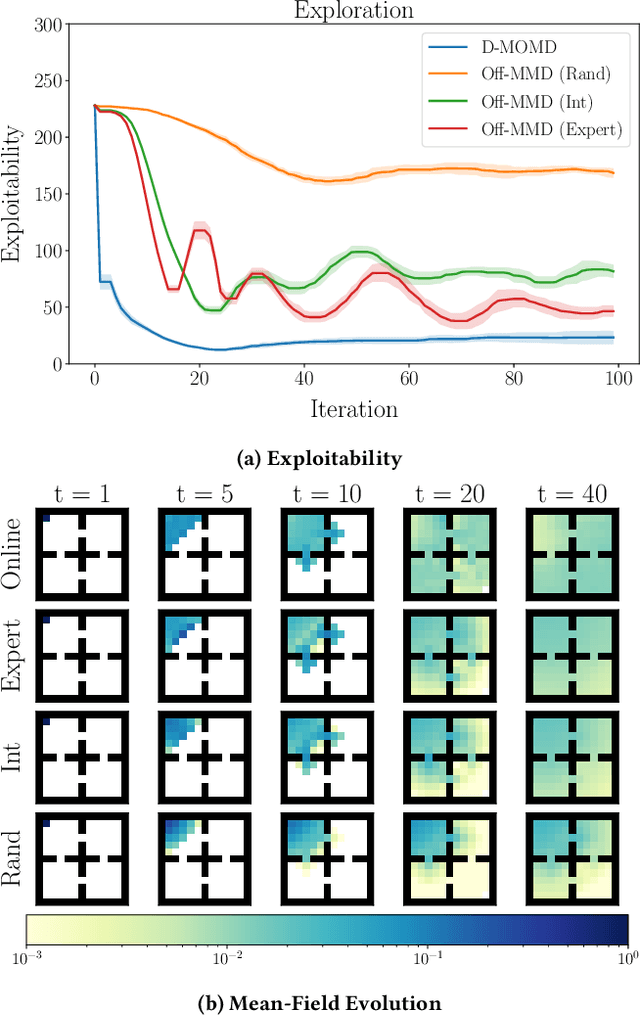



Reinforcement learning algorithms for mean-field games offer a scalable framework for optimizing policies in large populations of interacting agents. Existing methods often depend on online interactions or access to system dynamics, limiting their practicality in real-world scenarios where such interactions are infeasible or difficult to model. In this paper, we present Offline Munchausen Mirror Descent (Off-MMD), a novel mean-field RL algorithm that approximates equilibrium policies in mean-field games using purely offline data. By leveraging iterative mirror descent and importance sampling techniques, Off-MMD estimates the mean-field distribution from static datasets without relying on simulation or environment dynamics. Additionally, we incorporate techniques from offline reinforcement learning to address common issues like Q-value overestimation, ensuring robust policy learning even with limited data coverage. Our algorithm scales to complex environments and demonstrates strong performance on benchmark tasks like crowd exploration or navigation, highlighting its applicability to real-world multi-agent systems where online experimentation is infeasible. We empirically demonstrate the robustness of Off-MMD to low-quality datasets and conduct experiments to investigate its sensitivity to hyperparameter choices.
Segmentation of Prostate Tumour Volumes from PET Images is a Different Ball Game
Jul 15, 2024



Accurate segmentation of prostate tumours from PET images presents a formidable challenge in medical image analysis. Despite considerable work and improvement in delineating organs from CT and MR modalities, the existing standards do not transfer well and produce quality results in PET related tasks. Particularly, contemporary methods fail to accurately consider the intensity-based scaling applied by the physicians during manual annotation of tumour contours. In this paper, we observe that the prostate-localised uptake threshold ranges are beneficial for suppressing outliers. Therefore, we utilize the intensity threshold values, to implement a new custom-feature-clipping normalisation technique. We evaluate multiple, established U-Net variants under different normalisation schemes, using the nnU-Net framework. All models were trained and tested on multiple datasets, obtained with two radioactive tracers: [68-Ga]Ga-PSMA-11 and [18-F]PSMA-1007. Our results show that the U-Net models achieve much better performance when the PET scans are preprocessed with our novel clipping technique.
Unveiling the Unseen: Identifiable Clusters in Trained Depthwise Convolutional Kernels
Jan 25, 2024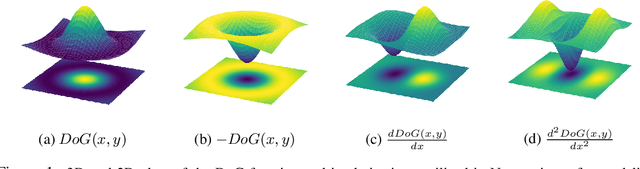
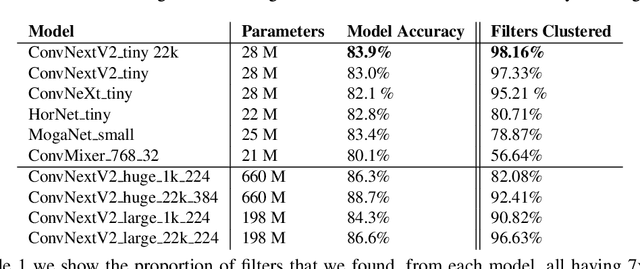
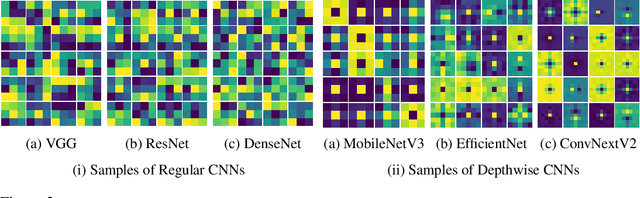

Recent advances in depthwise-separable convolutional neural networks (DS-CNNs) have led to novel architectures, that surpass the performance of classical CNNs, by a considerable scalability and accuracy margin. This paper reveals another striking property of DS-CNN architectures: discernible and explainable patterns emerge in their trained depthwise convolutional kernels in all layers. Through an extensive analysis of millions of trained filters, with different sizes and from various models, we employed unsupervised clustering with autoencoders, to categorize these filters. Astonishingly, the patterns converged into a few main clusters, each resembling the difference of Gaussian (DoG) functions, and their first and second-order derivatives. Notably, we were able to classify over 95\% and 90\% of the filters from state-of-the-art ConvNextV2 and ConvNeXt models, respectively. This finding is not merely a technological curiosity; it echoes the foundational models neuroscientists have long proposed for the vision systems of mammals. Our results thus deepen our understanding of the emergent properties of trained DS-CNNs and provide a bridge between artificial and biological visual processing systems. More broadly, they pave the way for more interpretable and biologically-inspired neural network designs in the future.
Neural Echos: Depthwise Convolutional Filters Replicate Biological Receptive Fields
Jan 18, 2024



In this study, we present evidence suggesting that depthwise convolutional kernels are effectively replicating the structural intricacies of the biological receptive fields observed in the mammalian retina. We provide analytics of trained kernels from various state-of-the-art models substantiating this evidence. Inspired by this intriguing discovery, we propose an initialization scheme that draws inspiration from the biological receptive fields. Experimental analysis of the ImageNet dataset with multiple CNN architectures featuring depthwise convolutions reveals a marked enhancement in the accuracy of the learned model when initialized with biologically derived weights. This underlies the potential for biologically inspired computational models to further our understanding of vision processing systems and to improve the efficacy of convolutional networks.
Prediction of Tourism Flow with Sparse Geolocation Data
Aug 28, 2023Modern tourism in the 21st century is facing numerous challenges. Among these the rapidly growing number of tourists visiting space-limited regions like historical cities, museums and bottlenecks such as bridges is one of the biggest. In this context, a proper and accurate prediction of tourism volume and tourism flow within a certain area is important and critical for visitor management tasks such as sustainable treatment of the environment and prevention of overcrowding. Static flow control methods like conventional low-level controllers or limiting access to overcrowded venues could not solve the problem yet. In this paper, we empirically evaluate the performance of state-of-the-art deep-learning methods such as RNNs, GNNs, and Transformers as well as the classic statistical ARIMA method. Granular limited data supplied by a tourism region is extended by exogenous data such as geolocation trajectories of individual tourists, weather and holidays. In the field of visitor flow prediction with sparse data, we are thereby capable of increasing the accuracy of our predictions, incorporating modern input feature handling as well as mapping geolocation data on top of discrete POI data.
IB-U-Nets: Improving medical image segmentation tasks with 3D Inductive Biased kernels
Oct 28, 2022



Despite the success of convolutional neural networks for 3D medical-image segmentation, the architectures currently used are still not robust enough to the protocols of different scanners, and the variety of image properties they produce. Moreover, access to large-scale datasets with annotated regions of interest is scarce, and obtaining good results is thus difficult. To overcome these challenges, we introduce IB-U-Nets, a novel architecture with inductive bias, inspired by the visual processing in vertebrates. With the 3D U-Net as the base, we add two 3D residual components to the second encoder blocks. They provide an inductive bias, helping U-Nets to segment anatomical structures from 3D images with increased robustness and accuracy. We compared IB-U-Nets with state-of-the-art 3D U-Nets on multiple modalities and organs, such as the prostate and spleen, using the same training and testing pipeline, including data processing, augmentation and cross-validation. Our results demonstrate the superior robustness and accuracy of IB-U-Nets, especially on small datasets, as is typically the case in medical-image analysis. IB-U-Nets source code and models are publicly available.
Deep-Learning vs Regression: Prediction of Tourism Flow with Limited Data
Jun 27, 2022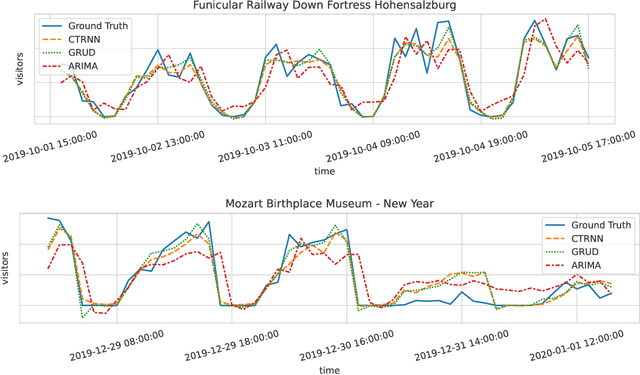

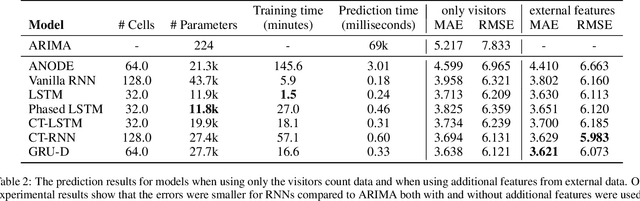
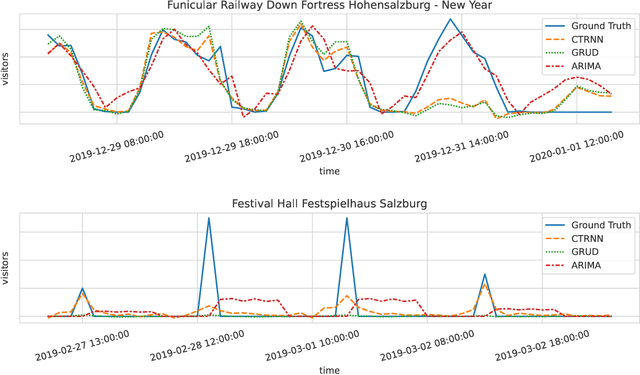
Modern tourism in the 21st century is facing numerous challenges. One of these challenges is the rapidly growing number of tourists in space limited regions such as historical city centers, museums or geographical bottlenecks like narrow valleys. In this context, a proper and accurate prediction of tourism volume and tourism flow within a certain area is important and critical for visitor management tasks such as visitor flow control and prevention of overcrowding. Static flow control methods like limiting access to hotspots or using conventional low level controllers could not solve the problem yet. In this paper, we empirically evaluate the performance of several state-of-the-art deep-learning methods in the field of visitor flow prediction with limited data by using available granular data supplied by a tourism region and comparing the results to ARIMA, a classical statistical method. Our results show that deep-learning models yield better predictions compared to the ARIMA method, while both featuring faster inference times and being able to incorporate additional input features.