 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Offline Reinforcement Learning for Mean Field Games
Paper and Code
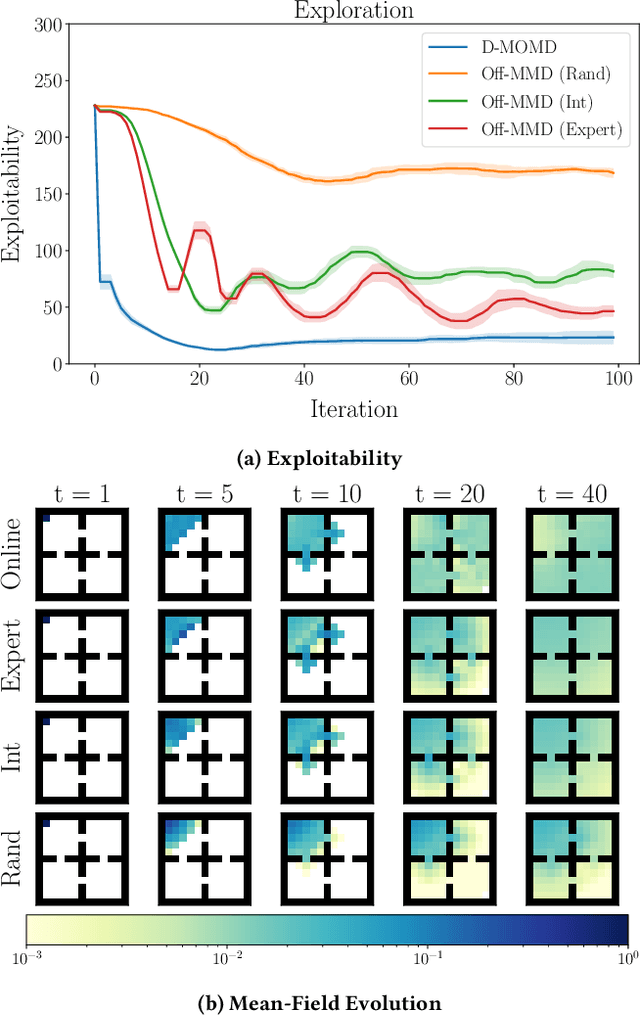



Reinforcement learning algorithms for mean-field games offer a scalable framework for optimizing policies in large populations of interacting agents. Existing methods often depend on online interactions or access to system dynamics, limiting their practicality in real-world scenarios where such interactions are infeasible or difficult to model. In this paper, we present Offline Munchausen Mirror Descent (Off-MMD), a novel mean-field RL algorithm that approximates equilibrium policies in mean-field games using purely offline data. By leveraging iterative mirror descent and importance sampling techniques, Off-MMD estimates the mean-field distribution from static datasets without relying on simulation or environment dynamics. Additionally, we incorporate techniques from offline reinforcement learning to address common issues like Q-value overestimation, ensuring robust policy learning even with limited data coverage. Our algorithm scales to complex environments and demonstrates strong performance on benchmark tasks like crowd exploration or navigation, highlighting its applicability to real-world multi-agent systems where online experimentation is infeasible. We empirically demonstrate the robustness of Off-MMD to low-quality datasets and conduct experiments to investigate its sensitivity to hyperparameter choices.