 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Fine-Tuning of Pretrained Controllers for Autonomous Driving via Real-Time Recurrent RL
Feb 03, 2026Deploying pretrained policies in real-world applications presents substantial challenges that fundamentally limit the practical applicability of learning-based control systems. When autonomous systems encounter environmental changes in system dynamics, sensor drift, or task objectives, fixed policies rapidly degrade in performance. We show that employing Real-Time Recurrent Reinforcement Learning (RTRRL), a biologically plausible algorithm for online adaptation, can effectively fine-tune a pretrained policy to improve autonomous agents' performance on driving tasks. We further show that RTRRL synergizes with a recent biologically inspired recurrent network model, the Liquid-Resistance Liquid-Capacitance RNN. We demonstrate the effectiveness of this closed-loop approach in a simulated CarRacing environment and in a real-world line-following task with a RoboRacer car equipped with an event camera.
Online Fine-Tuning of Carbon Emission Predictions using Real-Time Recurrent Learning for State Space Models
Aug 01, 2025This paper introduces a new approach for fine-tuning the predictions of structured state space models (SSMs) at inference time using real-time recurrent learning. While SSMs are known for their efficiency and long-range modeling capabilities, they are typically trained offline and remain static during deployment. Our method enables online adaptation by continuously updating model parameters in response to incoming data. We evaluate our approach for linear-recurrent-unit SSMs using a small carbon emission dataset collected from embedded automotive hardware. Experimental results show that our method consistently reduces prediction error online during inference, demonstrating its potential for dynamic, resource-constrained environments.
A quantum-classical reinforcement learning model to play Atari games
Dec 11, 2024Recent advances in reinforcement learning have demonstrated the potential of quantum learning models based on parametrized quantum circuits as an alternative to deep learning models. On the one hand, these findings have shown the ultimate exponential speed-ups in learning that full-blown quantum models can offer in certain -- artificially constructed -- environments. On the other hand, they have demonstrated the ability of experimentally accessible PQCs to solve OpenAI Gym benchmarking tasks. However, it remains an open question whether these near-term QRL techniques can be successfully applied to more complex problems exhibiting high-dimensional observation spaces. In this work, we bridge this gap and present a hybrid model combining a PQC with classical feature encoding and post-processing layers that is capable of tackling Atari games. A classical model, subjected to architectural restrictions similar to those present in the hybrid model is constructed to serve as a reference. Our numerical investigation demonstrates that the proposed hybrid model is capable of solving the Pong environment and achieving scores comparable to the classical reference in Breakout. Furthermore, our findings shed light on important hyperparameter settings and design choices that impact the interplay of the quantum and classical components. This work contributes to the understanding of near-term quantum learning models and makes an important step towards their deployment in real-world RL scenarios.
Scalable Offline Reinforcement Learning for Mean Field Games
Oct 23, 2024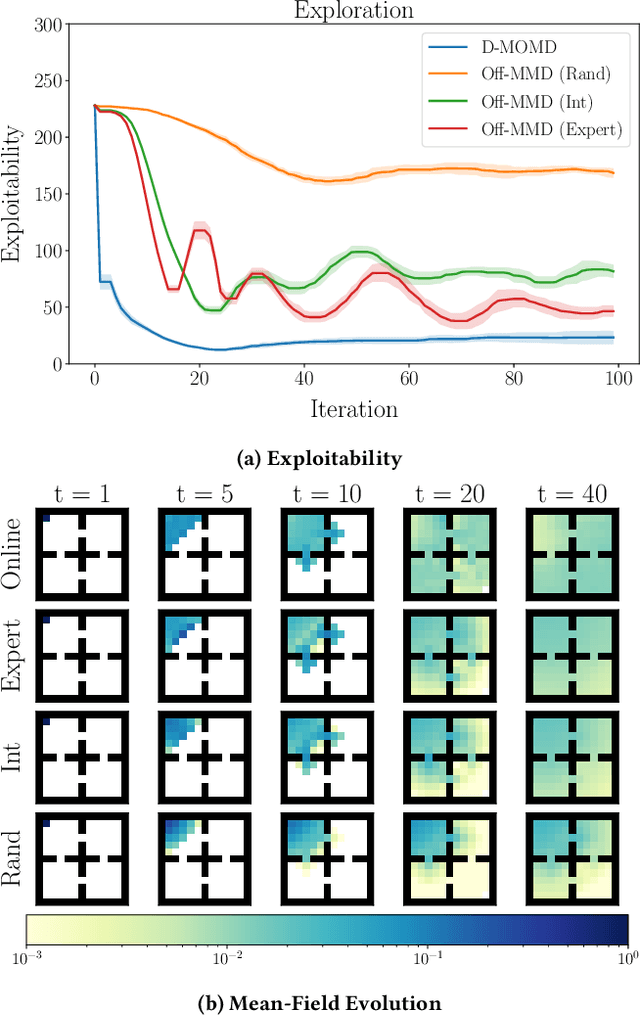



Reinforcement learning algorithms for mean-field games offer a scalable framework for optimizing policies in large populations of interacting agents. Existing methods often depend on online interactions or access to system dynamics, limiting their practicality in real-world scenarios where such interactions are infeasible or difficult to model. In this paper, we present Offline Munchausen Mirror Descent (Off-MMD), a novel mean-field RL algorithm that approximates equilibrium policies in mean-field games using purely offline data. By leveraging iterative mirror descent and importance sampling techniques, Off-MMD estimates the mean-field distribution from static datasets without relying on simulation or environment dynamics. Additionally, we incorporate techniques from offline reinforcement learning to address common issues like Q-value overestimation, ensuring robust policy learning even with limited data coverage. Our algorithm scales to complex environments and demonstrates strong performance on benchmark tasks like crowd exploration or navigation, highlighting its applicability to real-world multi-agent systems where online experimentation is infeasible. We empirically demonstrate the robustness of Off-MMD to low-quality datasets and conduct experiments to investigate its sensitivity to hyperparameter choices.
Real-Time Recurrent Reinforcement Learning
Nov 08, 2023



Recent advances in reinforcement learning, for partially-observable Markov decision processes (POMDPs), rely on the biologically implausible backpropagation through time algorithm (BPTT) to perform gradient-descent optimisation. In this paper we propose a novel reinforcement learning algorithm that makes use of random feedback local online learning (RFLO), a biologically plausible approximation of realtime recurrent learning (RTRL) to compute the gradients of the parameters of a recurrent neural network in an online manner. By combining it with TD($\lambda$), a variant of temporaldifference reinforcement learning with eligibility traces, we create a biologically plausible, recurrent actor-critic algorithm, capable of solving discrete and continuous control tasks in POMDPs. We compare BPTT, RTRL and RFLO as well as different network architectures, and find that RFLO can perform just as well as RTRL while exceeding even BPTT in terms of complexity. The proposed method, called real-time recurrent reinforcement learning (RTRRL), serves as a model of learning in biological neural networks mimicking reward pathways in the mammalian brain.
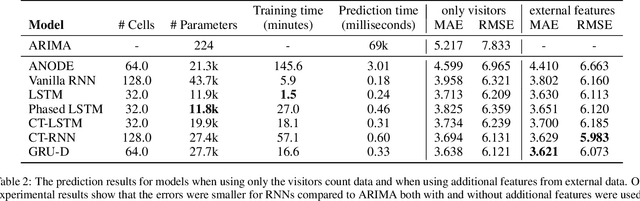
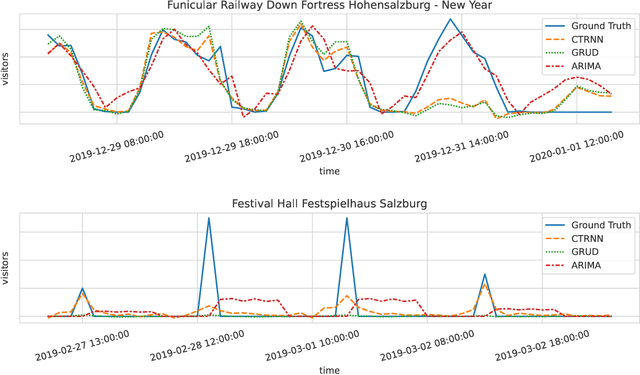
Prediction of Tourism Flow with Sparse Geolocation Data
Aug 28, 2023Modern tourism in the 21st century is facing numerous challenges. Among these the rapidly growing number of tourists visiting space-limited regions like historical cities, museums and bottlenecks such as bridges is one of the biggest. In this context, a proper and accurate prediction of tourism volume and tourism flow within a certain area is important and critical for visitor management tasks such as sustainable treatment of the environment and prevention of overcrowding. Static flow control methods like conventional low-level controllers or limiting access to overcrowded venues could not solve the problem yet. In this paper, we empirically evaluate the performance of state-of-the-art deep-learning methods such as RNNs, GNNs, and Transformers as well as the classic statistical ARIMA method. Granular limited data supplied by a tourism region is extended by exogenous data such as geolocation trajectories of individual tourists, weather and holidays. In the field of visitor flow prediction with sparse data, we are thereby capable of increasing the accuracy of our predictions, incorporating modern input feature handling as well as mapping geolocation data on top of discrete POI data.
On the Benefits of Biophysical Synapses
Mar 08, 2023The approximation capability of ANNs and their RNN instantiations, is strongly correlated with the number of parameters packed into these networks. However, the complexity barrier for human understanding, is arguably related to the number of neurons and synapses in the networks, and to the associated nonlinear transformations. In this paper we show that the use of biophysical synapses, as found in LTCs, have two main benefits. First, they allow to pack more parameters for a given number of neurons and synapses. Second, they allow to formulate the nonlinear-network transformation, as a linear system with state-dependent coefficients. Both increase interpretability, as for a given task, they allow to learn a system linear in its input features, that is smaller in size compared to the state of the art. We substantiate the above claims on various time-series prediction tasks, but we believe that our results are applicable to any feedforward or recurrent ANN.
Deep-Learning vs Regression: Prediction of Tourism Flow with Limited Data
Jun 27, 2022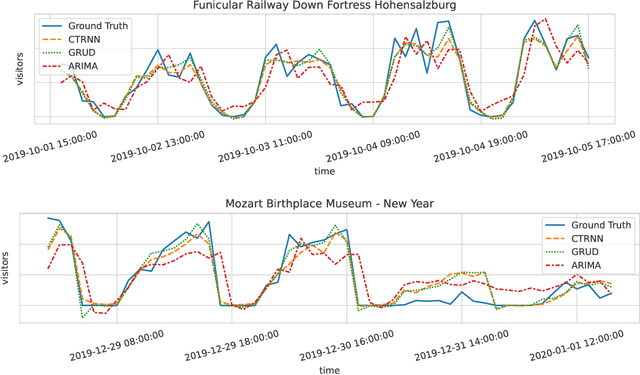

Modern tourism in the 21st century is facing numerous challenges. One of these challenges is the rapidly growing number of tourists in space limited regions such as historical city centers, museums or geographical bottlenecks like narrow valleys. In this context, a proper and accurate prediction of tourism volume and tourism flow within a certain area is important and critical for visitor management tasks such as visitor flow control and prevention of overcrowding. Static flow control methods like limiting access to hotspots or using conventional low level controllers could not solve the problem yet. In this paper, we empirically evaluate the performance of several state-of-the-art deep-learning methods in the field of visitor flow prediction with limited data by using available granular data supplied by a tourism region and comparing the results to ARIMA, a classical statistical method. Our results show that deep-learning models yield better predictions compared to the ARIMA method, while both featuring faster inference times and being able to incorporate additional input features.