 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntangled Residual Mappings
Paper and Code
Jun 02, 2022

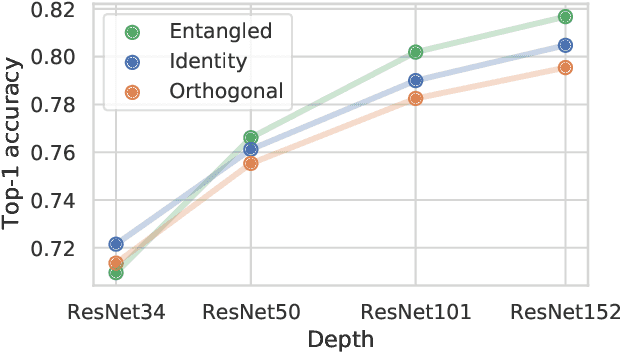

Residual mappings have been shown to perform representation learning in the first layers and iterative feature refinement in higher layers. This interplay, combined with their stabilizing effect on the gradient norms, enables them to train very deep networks. In this paper, we take a step further and introduce entangled residual mappings to generalize the structure of the residual connections and evaluate their role in iterative learning representations. An entangled residual mapping replaces the identity skip connections with specialized entangled mappings such as orthogonal, sparse, and structural correlation matrices that share key attributes (eigenvalues, structure, and Jacobian norm) with identity mappings. We show that while entangled mappings can preserve the iterative refinement of features across various deep models, they influence the representation learning process in convolutional networks differently than attention-based models and recurrent neural networks. In general, we find that for CNNs and Vision Transformers entangled sparse mapping can help generalization while orthogonal mappings hurt performance. For recurrent networks, orthogonal residual mappings form an inductive bias for time-variant sequences, which degrades accuracy on time-invariant tasks.