 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Fairness: A Runtime Perspective
Jul 28, 2025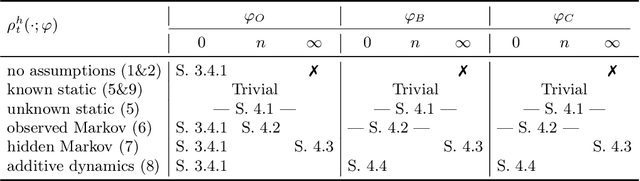

Fairness in AI is traditionally studied as a static property evaluated once, over a fixed dataset. However, real-world AI systems operate sequentially, with outcomes and environments evolving over time. This paper proposes a framework for analysing fairness as a runtime property. Using a minimal yet expressive model based on sequences of coin tosses with possibly evolving biases, we study the problems of monitoring and enforcing fairness expressed in either toss outcomes or coin biases. Since there is no one-size-fits-all solution for either problem, we provide a summary of monitoring and enforcement strategies, parametrised by environment dynamics, prediction horizon, and confidence thresholds. For both problems, we present general results under simple or minimal assumptions. We survey existing solutions for the monitoring problem for Markovian and additive dynamics, and existing solutions for the enforcement problem in static settings with known dynamics.
Formal Verification of Neural Certificates Done Dynamically
Jul 16, 2025Neural certificates have emerged as a powerful tool in cyber-physical systems control, providing witnesses of correctness. These certificates, such as barrier functions, often learned alongside control policies, once verified, serve as mathematical proofs of system safety. However, traditional formal verification of their defining conditions typically faces scalability challenges due to exhaustive state-space exploration. To address this challenge, we propose a lightweight runtime monitoring framework that integrates real-time verification and does not require access to the underlying control policy. Our monitor observes the system during deployment and performs on-the-fly verification of the certificate over a lookahead region to ensure safety within a finite prediction horizon. We instantiate this framework for ReLU-based control barrier functions and demonstrate its practical effectiveness in a case study. Our approach enables timely detection of safety violations and incorrect certificates with minimal overhead, providing an effective but lightweight alternative to the static verification of the certificates.
Logic Gate Neural Networks are Good for Verification
May 26, 2025Learning-based systems are increasingly deployed across various domains, yet the complexity of traditional neural networks poses significant challenges for formal verification. Unlike conventional neural networks, learned Logic Gate Networks (LGNs) replace multiplications with Boolean logic gates, yielding a sparse, netlist-like architecture that is inherently more amenable to symbolic verification, while still delivering promising performance. In this paper, we introduce a SAT encoding for verifying global robustness and fairness in LGNs. We evaluate our method on five benchmark datasets, including a newly constructed 5-class variant, and find that LGNs are both verification-friendly and maintain strong predictive performance.
Predictive Monitoring of Black-Box Dynamical Systems
Dec 21, 2024



We study the problem of predictive runtime monitoring of black-box dynamical systems with quantitative safety properties. The black-box setting stipulates that the exact semantics of the dynamical system and the controller are unknown, and that we are only able to observe the state of the controlled (aka, closed-loop) system at finitely many time points. We present a novel framework for predicting future states of the system based on the states observed in the past. The numbers of past states and of predicted future states are parameters provided by the user. Our method is based on a combination of Taylor's expansion and the backward difference operator for numerical differentiation. We also derive an upper bound on the prediction error under the assumption that the system dynamics and the controller are smooth. The predicted states are then used to predict safety violations ahead in time. Our experiments demonstrate practical applicability of our method for complex black-box systems, showing that it is computationally lightweight and yet significantly more accurate than the state-of-the-art predictive safety monitoring techniques.
Neural Control and Certificate Repair via Runtime Monitoring
Dec 17, 2024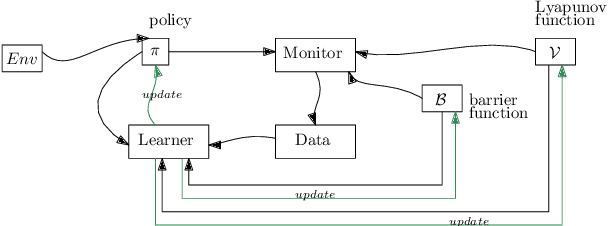

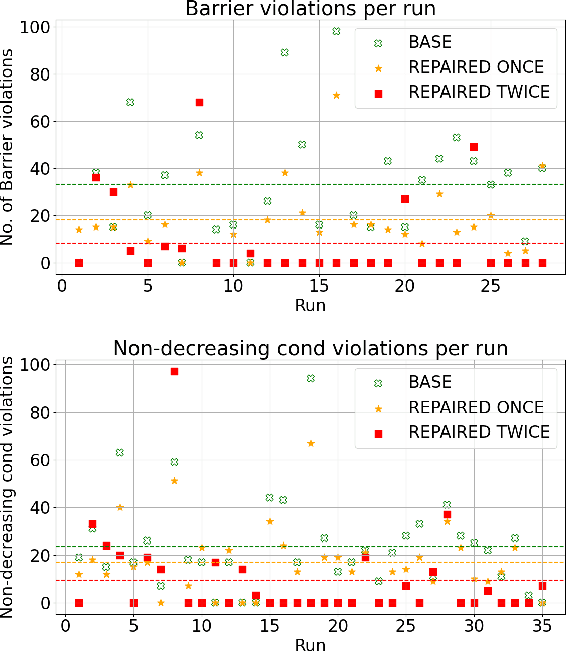

Learning-based methods provide a promising approach to solving highly non-linear control tasks that are often challenging for classical control methods. To ensure the satisfaction of a safety property, learning-based methods jointly learn a control policy together with a certificate function for the property. Popular examples include barrier functions for safety and Lyapunov functions for asymptotic stability. While there has been significant progress on learning-based control with certificate functions in the white-box setting, where the correctness of the certificate function can be formally verified, there has been little work on ensuring their reliability in the black-box setting where the system dynamics are unknown. In this work, we consider the problems of certifying and repairing neural network control policies and certificate functions in the black-box setting. We propose a novel framework that utilizes runtime monitoring to detect system behaviors that violate the property of interest under some initially trained neural network policy and certificate. These violating behaviors are used to extract new training data, that is used to re-train the neural network policy and the certificate function and to ultimately repair them. We demonstrate the effectiveness of our approach empirically by using it to repair and to boost the safety rate of neural network policies learned by a state-of-the-art method for learning-based control on two autonomous system control tasks.
Fairness Shields: Safeguarding against Biased Decision Makers
Dec 16, 2024



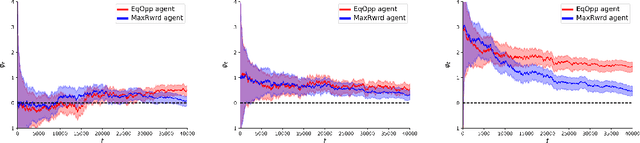
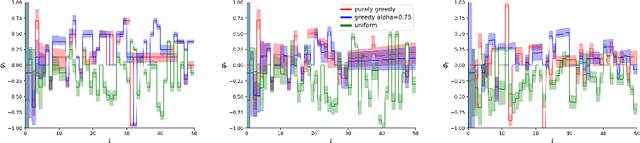
As AI-based decision-makers increasingly influence human lives, it is a growing concern that their decisions are often unfair or biased with respect to people's sensitive attributes, such as gender and race. Most existing bias prevention measures provide probabilistic fairness guarantees in the long run, and it is possible that the decisions are biased on specific instances of short decision sequences. We introduce fairness shielding, where a symbolic decision-maker -- the fairness shield -- continuously monitors the sequence of decisions of another deployed black-box decision-maker, and makes interventions so that a given fairness criterion is met while the total intervention costs are minimized. We present four different algorithms for computing fairness shields, among which one guarantees fairness over fixed horizons, and three guarantee fairness periodically after fixed intervals. Given a distribution over future decisions and their intervention costs, our algorithms solve different instances of bounded-horizon optimal control problems with different levels of computational costs and optimality guarantees. Our empirical evaluation demonstrates the effectiveness of these shields in ensuring fairness while maintaining cost efficiency across various scenarios.
Compositional Policy Learning in Stochastic Control Systems with Formal Guarantees
Dec 03, 2023



Reinforcement learning has shown promising results in learning neural network policies for complicated control tasks. However, the lack of formal guarantees about the behavior of such policies remains an impediment to their deployment. We propose a novel method for learning a composition of neural network policies in stochastic environments, along with a formal certificate which guarantees that a specification over the policy's behavior is satisfied with the desired probability. Unlike prior work on verifiable RL, our approach leverages the compositional nature of logical specifications provided in SpectRL, to learn over graphs of probabilistic reach-avoid specifications. The formal guarantees are provided by learning neural network policies together with reach-avoid supermartingales (RASM) for the graph's sub-tasks and then composing them into a global policy. We also derive a tighter lower bound compared to previous work on the probability of reach-avoidance implied by a RASM, which is required to find a compositional policy with an acceptable probabilistic threshold for complex tasks with multiple edge policies. We implement a prototype of our approach and evaluate it on a Stochastic Nine Rooms environment.
Monitoring Algorithmic Fairness under Partial Observations
Aug 01, 2023As AI and machine-learned software are used increasingly for making decisions that affect humans, it is imperative that they remain fair and unbiased in their decisions. To complement design-time bias mitigation measures, runtime verification techniques have been introduced recently to monitor the algorithmic fairness of deployed systems. Previous monitoring techniques assume full observability of the states of the (unknown) monitored system. Moreover, they can monitor only fairness properties that are specified as arithmetic expressions over the probabilities of different events. In this work, we extend fairness monitoring to systems modeled as partially observed Markov chains (POMC), and to specifications containing arithmetic expressions over the expected values of numerical functions on event sequences. The only assumptions we make are that the underlying POMC is aperiodic and starts in the stationary distribution, with a bound on its mixing time being known. These assumptions enable us to estimate a given property for the entire distribution of possible executions of the monitored POMC, by observing only a single execution. Our monitors observe a long run of the system and, after each new observation, output updated PAC-estimates of how fair or biased the system is. The monitors are computationally lightweight and, using a prototype implementation, we demonstrate their effectiveness on several real-world examples.
Monitoring Algorithmic Fairness
May 25, 2023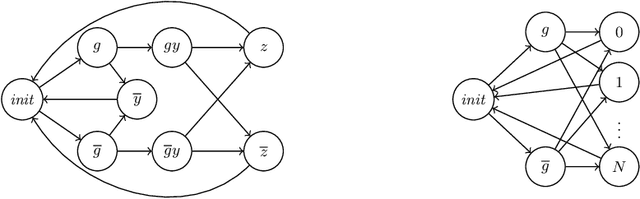
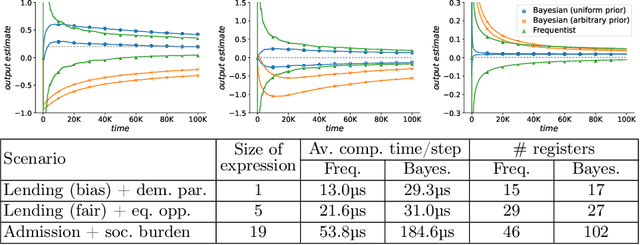
Machine-learned systems are in widespread use for making decisions about humans, and it is important that they are fair, i.e., not biased against individuals based on sensitive attributes. We present runtime verification of algorithmic fairness for systems whose models are unknown, but are assumed to have a Markov chain structure. We introduce a specification language that can model many common algorithmic fairness properties, such as demographic parity, equal opportunity, and social burden. We build monitors that observe a long sequence of events as generated by a given system, and output, after each observation, a quantitative estimate of how fair or biased the system was on that run until that point in time. The estimate is proven to be correct modulo a variable error bound and a given confidence level, where the error bound gets tighter as the observed sequence gets longer. Our monitors are of two types, and use, respectively, frequentist and Bayesian statistical inference techniques. While the frequentist monitors compute estimates that are objectively correct with respect to the ground truth, the Bayesian monitors compute estimates that are correct subject to a given prior belief about the system's model. Using a prototype implementation, we show how we can monitor if a bank is fair in giving loans to applicants from different social backgrounds, and if a college is fair in admitting students while maintaining a reasonable financial burden on the society. Although they exhibit different theoretical complexities in certain cases, in our experiments, both frequentist and Bayesian monitors took less than a millisecond to update their verdicts after each observation.
Runtime Monitoring of Dynamic Fairness Properties
May 08, 2023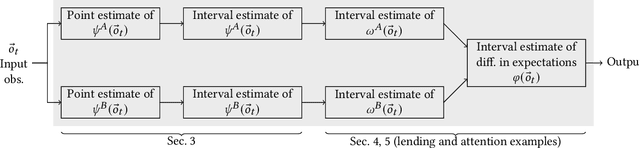
A machine-learned system that is fair in static decision-making tasks may have biased societal impacts in the long-run. This may happen when the system interacts with humans and feedback patterns emerge, reinforcing old biases in the system and creating new biases. While existing works try to identify and mitigate long-run biases through smart system design, we introduce techniques for monitoring fairness in real time. Our goal is to build and deploy a monitor that will continuously observe a long sequence of events generated by the system in the wild, and will output, with each event, a verdict on how fair the system is at the current point in time. The advantages of monitoring are two-fold. Firstly, fairness is evaluated at run-time, which is important because unfair behaviors may not be eliminated a priori, at design-time, due to partial knowledge about the system and the environment, as well as uncertainties and dynamic changes in the system and the environment, such as the unpredictability of human behavior. Secondly, monitors are by design oblivious to how the monitored system is constructed, which makes them suitable to be used as trusted third-party fairness watchdogs. They function as computationally lightweight statistical estimators, and their correctness proofs rely on the rigorous analysis of the stochastic process that models the assumptions about the underlying dynamics of the system. We show, both in theory and experiments, how monitors can warn us (1) if a bank's credit policy over time has created an unfair distribution of credit scores among the population, and (2) if a resource allocator's allocation policy over time has made unfair allocations. Our experiments demonstrate that the monitors introduce very low overhead. We believe that runtime monitoring is an important and mathematically rigorous new addition to the fairness toolbox.