 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Fairness: A Runtime Perspective
Jul 28, 2025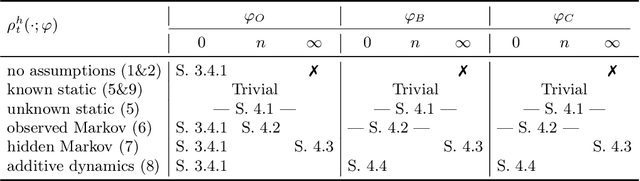

Fairness in AI is traditionally studied as a static property evaluated once, over a fixed dataset. However, real-world AI systems operate sequentially, with outcomes and environments evolving over time. This paper proposes a framework for analysing fairness as a runtime property. Using a minimal yet expressive model based on sequences of coin tosses with possibly evolving biases, we study the problems of monitoring and enforcing fairness expressed in either toss outcomes or coin biases. Since there is no one-size-fits-all solution for either problem, we provide a summary of monitoring and enforcement strategies, parametrised by environment dynamics, prediction horizon, and confidence thresholds. For both problems, we present general results under simple or minimal assumptions. We survey existing solutions for the monitoring problem for Markovian and additive dynamics, and existing solutions for the enforcement problem in static settings with known dynamics.
Towards Responsible AI: Advances in Safety, Fairness, and Accountability of Autonomous Systems
Jun 11, 2025
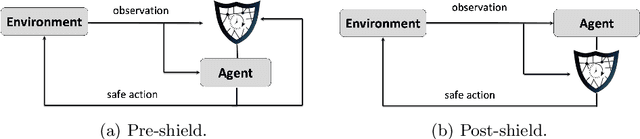
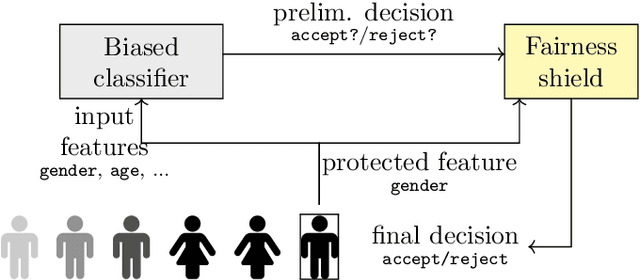
Ensuring responsible use of artificial intelligence (AI) has become imperative as autonomous systems increasingly influence critical societal domains. However, the concept of trustworthy AI remains broad and multi-faceted. This thesis advances knowledge in the safety, fairness, transparency, and accountability of AI systems. In safety, we extend classical deterministic shielding techniques to become resilient against delayed observations, enabling practical deployment in real-world conditions. We also implement both deterministic and probabilistic safety shields into simulated autonomous vehicles to prevent collisions with road users, validating the use of these techniques in realistic driving simulators. We introduce fairness shields, a novel post-processing approach to enforce group fairness in sequential decision-making settings over finite and periodic time horizons. By optimizing intervention costs while strictly ensuring fairness constraints, this method efficiently balances fairness with minimal interference. For transparency and accountability, we propose a formal framework for assessing intentional behaviour in probabilistic decision-making agents, introducing quantitative metrics of agency and intention quotient. We use these metrics to propose a retrospective analysis of intention, useful for determining responsibility when autonomous systems cause unintended harm. Finally, we unify these contributions through the ``reactive decision-making'' framework, providing a general formalization that consolidates previous approaches. Collectively, the advancements presented contribute practically to the realization of safer, fairer, and more accountable AI systems, laying the foundations for future research in trustworthy AI.
Fairness Shields: Safeguarding against Biased Decision Makers
Dec 16, 2024



As AI-based decision-makers increasingly influence human lives, it is a growing concern that their decisions are often unfair or biased with respect to people's sensitive attributes, such as gender and race. Most existing bias prevention measures provide probabilistic fairness guarantees in the long run, and it is possible that the decisions are biased on specific instances of short decision sequences. We introduce fairness shielding, where a symbolic decision-maker -- the fairness shield -- continuously monitors the sequence of decisions of another deployed black-box decision-maker, and makes interventions so that a given fairness criterion is met while the total intervention costs are minimized. We present four different algorithms for computing fairness shields, among which one guarantees fairness over fixed horizons, and three guarantee fairness periodically after fixed intervals. Given a distribution over future decisions and their intervention costs, our algorithms solve different instances of bounded-horizon optimal control problems with different levels of computational costs and optimality guarantees. Our empirical evaluation demonstrates the effectiveness of these shields in ensuring fairness while maintaining cost efficiency across various scenarios.
Machine Unlearning using Forgetting Neural Networks
Oct 29, 2024Modern computer systems store vast amounts of personal data, enabling advances in AI and ML but risking user privacy and trust. For privacy reasons, it is desired sometimes for an ML model to forget part of the data it was trained on. This paper presents a new approach to machine unlearning using forgetting neural networks (FNN). FNNs are neural networks with specific forgetting layers, that take inspiration from the processes involved when a human brain forgets. While FNNs had been proposed as a theoretical construct, they have not been previously used as a machine unlearning method. We describe four different types of forgetting layers and study their properties. In our experimental evaluation, we report our results on the MNIST handwritten digit recognition and fashion datasets. The effectiveness of the unlearned models was tested using Membership Inference Attacks (MIA). Successful experimental results demonstrate the great potential of our proposed method for dealing with the machine unlearning problem.