 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDYMAPIA: A Multi-Domain Framework for Detecting AI-based Video Manipulation
Apr 27, 2026AI-generated media are advancing rapidly, raising pressing concerns for content authenticity and digital trust. We introduce DYMAPIA, a multi-domain Deepfake detection framework that fuses spatial, spectral, and temporal cues to capture subtle traces of manipulation in visual data. The system builds dynamic anomaly masks by combining evidence from Fourier spectra, local texture descriptors, edge irregularities, and optical flow consistency, which highlight tampered regions with fine spatial accuracy. These masks guide DistXCNet, a lightweight classifier distilled from Xception and optimized with depthwise separable convolutions for fast, region-focused classification. This joint design achieves state-of-the-art results, with accuracy and F1-scores exceeding 99\% on FF++, Celeb-DF, and VDFD benchmarks, while keeping the model compact enough for real-time use. Beyond outperforming existing full-frame and multidomain detectors, DYMAPIA demonstrates deployment readiness for time-critical forensic tasks, including media verification, misinformation defense, and secure content filtering.
Machine Unlearning using Forgetting Neural Networks
Oct 29, 2024Modern computer systems store vast amounts of personal data, enabling advances in AI and ML but risking user privacy and trust. For privacy reasons, it is desired sometimes for an ML model to forget part of the data it was trained on. This paper presents a new approach to machine unlearning using forgetting neural networks (FNN). FNNs are neural networks with specific forgetting layers, that take inspiration from the processes involved when a human brain forgets. While FNNs had been proposed as a theoretical construct, they have not been previously used as a machine unlearning method. We describe four different types of forgetting layers and study their properties. In our experimental evaluation, we report our results on the MNIST handwritten digit recognition and fashion datasets. The effectiveness of the unlearned models was tested using Membership Inference Attacks (MIA). Successful experimental results demonstrate the great potential of our proposed method for dealing with the machine unlearning problem.
Machine Unlearning using a Multi-GAN based Model
Jul 26, 2024This article presents a new machine unlearning approach that utilizes multiple Generative Adversarial Network (GAN) based models. The proposed method comprises two phases: i) data reorganization in which synthetic data using the GAN model is introduced with inverted class labels of the forget datasets, and ii) fine-tuning the pre-trained model. The GAN models consist of two pairs of generators and discriminators. The generator discriminator pairs generate synthetic data for the retain and forget datasets. Then, a pre-trained model is utilized to get the class labels of the synthetic datasets. The class labels of synthetic and original forget datasets are inverted. Finally, all combined datasets are used to fine-tune the pre-trained model to get the unlearned model. We have performed the experiments on the CIFAR-10 dataset and tested the unlearned models using Membership Inference Attacks (MIA). The inverted class labels procedure and synthetically generated data help to acquire valuable information that enables the model to outperform state-of-the-art models and other standard unlearning classifiers.
Enhancing Machine Learning Performance with Continuous In-Session Ground Truth Scores: Pilot Study on Objective Skeletal Muscle Pain Intensity Prediction
Aug 02, 2023Machine learning (ML) models trained on subjective self-report scores struggle to objectively classify pain accurately due to the significant variance between real-time pain experiences and recorded scores afterwards. This study developed two devices for acquisition of real-time, continuous in-session pain scores and gathering of ANS-modulated endodermal activity (EDA).The experiment recruited N = 24 subjects who underwent a post-exercise circulatory occlusion (PECO) with stretch, inducing discomfort. Subject data were stored in a custom pain platform, facilitating extraction of time-domain EDA features and in-session ground truth scores. Moreover, post-experiment visual analog scale (VAS) scores were collected from each subject. Machine learning models, namely Multi-layer Perceptron (MLP) and Random Forest (RF), were trained using corresponding objective EDA features combined with in-session scores and post-session scores, respectively. Over a 10-fold cross-validation, the macro-averaged geometric mean score revealed MLP and RF models trained with objective EDA features and in-session scores achieved superior performance (75.9% and 78.3%) compared to models trained with post-session scores (70.3% and 74.6%) respectively. This pioneering study demonstrates that using continuous in-session ground truth scores significantly enhances ML performance in pain intensity characterization, overcoming ground truth sparsity-related issues, data imbalance, and high variance. This study informs future objective-based ML pain system training.
Intrusion Detection Systems Using Adaptive Regression Splines
May 05, 2004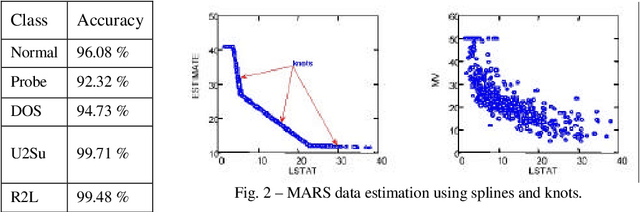
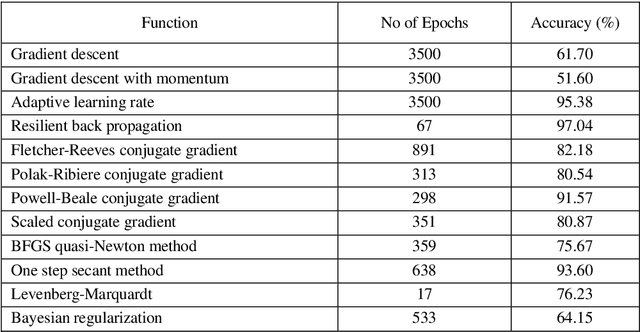
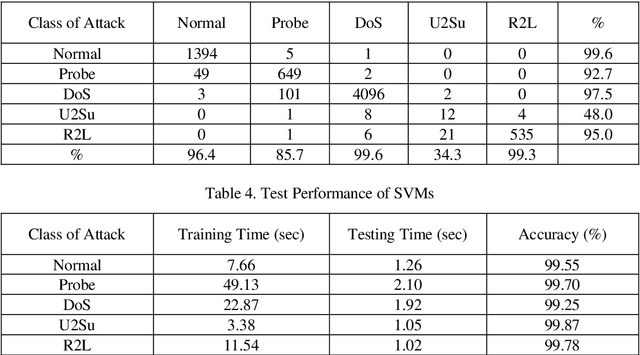
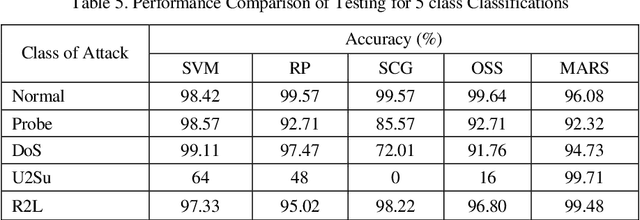
Past few years have witnessed a growing recognition of intelligent techniques for the construction of efficient and reliable intrusion detection systems. Due to increasing incidents of cyber attacks, building effective intrusion detection systems (IDS) are essential for protecting information systems security, and yet it remains an elusive goal and a great challenge. In this paper, we report a performance analysis between Multivariate Adaptive Regression Splines (MARS), neural networks and support vector machines. The MARS procedure builds flexible regression models by fitting separate splines to distinct intervals of the predictor variables. A brief comparison of different neural network learning algorithms is also given.