 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Machine Learning Performance with Continuous In-Session Ground Truth Scores: Pilot Study on Objective Skeletal Muscle Pain Intensity Prediction
Aug 02, 2023Machine learning (ML) models trained on subjective self-report scores struggle to objectively classify pain accurately due to the significant variance between real-time pain experiences and recorded scores afterwards. This study developed two devices for acquisition of real-time, continuous in-session pain scores and gathering of ANS-modulated endodermal activity (EDA).The experiment recruited N = 24 subjects who underwent a post-exercise circulatory occlusion (PECO) with stretch, inducing discomfort. Subject data were stored in a custom pain platform, facilitating extraction of time-domain EDA features and in-session ground truth scores. Moreover, post-experiment visual analog scale (VAS) scores were collected from each subject. Machine learning models, namely Multi-layer Perceptron (MLP) and Random Forest (RF), were trained using corresponding objective EDA features combined with in-session scores and post-session scores, respectively. Over a 10-fold cross-validation, the macro-averaged geometric mean score revealed MLP and RF models trained with objective EDA features and in-session scores achieved superior performance (75.9% and 78.3%) compared to models trained with post-session scores (70.3% and 74.6%) respectively. This pioneering study demonstrates that using continuous in-session ground truth scores significantly enhances ML performance in pain intensity characterization, overcoming ground truth sparsity-related issues, data imbalance, and high variance. This study informs future objective-based ML pain system training.
A Simulation Study of Functional Electrical Stimulation for An Upper Limb Rehabilitation Robot using Iterative Learning Control (ILC) and Linear models
Jul 15, 2022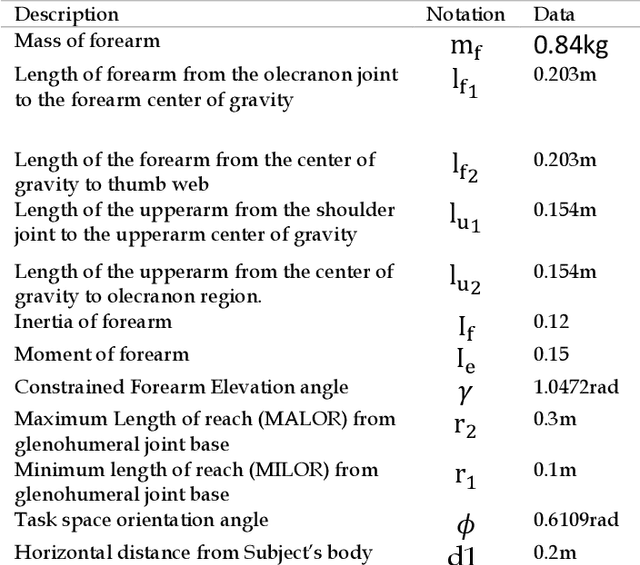

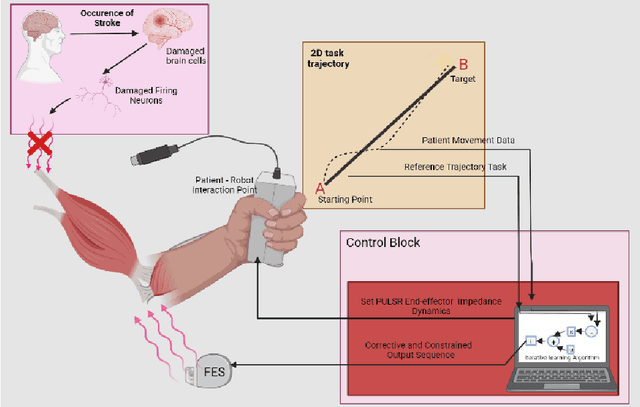
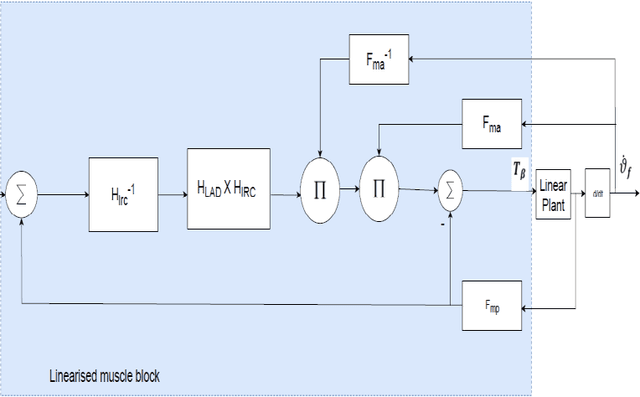
A proportional iterative learning control (P-ILC) for linear models of an existing hybrid stroke rehabilitation scheme is implemented for elbow extension/flexion during a rehabilitative task. Owing to transient error growth problem of P-ILC, a learning derivative constraint controller was included to ensure that the controlled system does not exceed a predefined velocity limit at every trial. To achieve this, linear transfer function models of the robot end-effector interaction with a stroke subject (plant) and muscle response to stimulation controllers were developed. A straight-line point-point trajectory of 0 - 0.3 m range served as the reference task space trajectory for the plant, feedforward, and feedback stimulation controllers. At each trial, a SAT-based bounded error derivative ILC algorithm served as the learning constraint controller. Three control configurations were developed and simulated. The system performance was evaluated using the root means square error (RMSE) and normalized RMSE. At different ILC gains over 16 iterations, a displacement error of 0.0060 m was obtained when control configurations were combined.