 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
WikiMixQA: A Multimodal Benchmark for Question Answering over Tables and Charts
Jun 18, 2025Documents are fundamental to preserving and disseminating information, often incorporating complex layouts, tables, and charts that pose significant challenges for automatic document understanding (DU). While vision-language large models (VLLMs) have demonstrated improvements across various tasks, their effectiveness in processing long-context vision inputs remains unclear. This paper introduces WikiMixQA, a benchmark comprising 1,000 multiple-choice questions (MCQs) designed to evaluate cross-modal reasoning over tables and charts extracted from 4,000 Wikipedia pages spanning seven distinct topics. Unlike existing benchmarks, WikiMixQA emphasizes complex reasoning by requiring models to synthesize information from multiple modalities. We evaluate 12 state-of-the-art vision-language models, revealing that while proprietary models achieve ~70% accuracy when provided with direct context, their performance deteriorates significantly when retrieval from long documents is required. Among these, GPT-4-o is the only model exceeding 50% accuracy in this setting, whereas open-source models perform considerably worse, with a maximum accuracy of 27%. These findings underscore the challenges of long-context, multi-modal reasoning and establish WikiMixQA as a crucial benchmark for advancing document understanding research.
Can Performant LLMs Be Ethical? Quantifying the Impact of Web Crawling Opt-Outs
Apr 08, 2025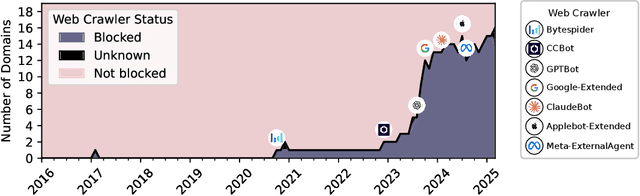



The increasing adoption of web crawling opt-outs by copyright holders of online content raises critical questions about the impact of data compliance on large language model (LLM) performance. However, little is known about how these restrictions (and the resultant filtering of pretraining datasets) affect the capabilities of models trained using these corpora. In this work, we conceptualize this effect as the $\textit{data compliance gap}$ (DCG), which quantifies the performance difference between models trained on datasets that comply with web crawling opt-outs, and those that do not. We measure the data compliance gap in two settings: pretraining models from scratch and continual pretraining from existing compliant models (simulating a setting where copyrighted data could be integrated later in pretraining). Our experiments with 1.5B models show that, as of January 2025, compliance with web data opt-outs does not degrade general knowledge acquisition (close to 0\% DCG). However, in specialized domains such as biomedical research, excluding major publishers leads to performance declines. These findings suggest that while general-purpose LLMs can be trained to perform equally well using fully open data, performance in specialized domains may benefit from access to high-quality copyrighted sources later in training. Our study provides empirical insights into the long-debated trade-off between data compliance and downstream model performance, informing future discussions on AI training practices and policy decisions.
LLaMa-SciQ: An Educational Chatbot for Answering Science MCQ
Sep 25, 2024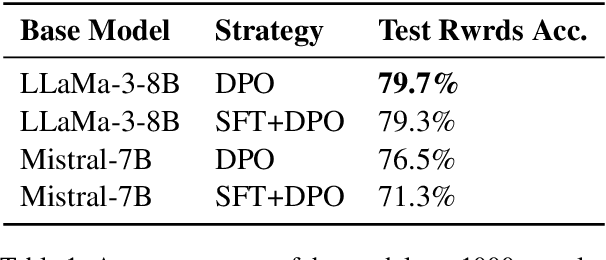
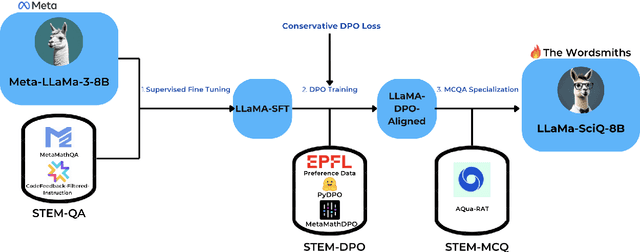
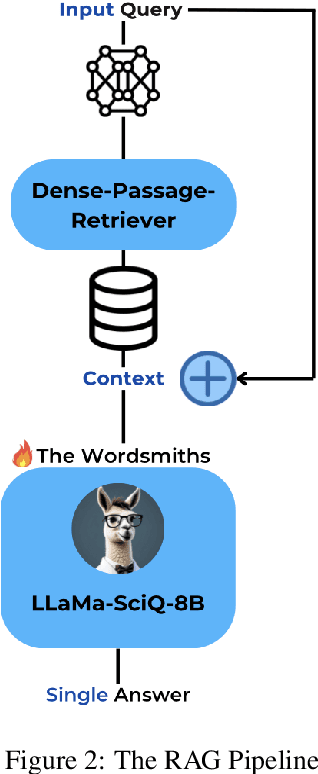
Large Language Models (LLMs) often struggle with tasks requiring mathematical reasoning, particularly multiple-choice questions (MCQs). To address this issue, we developed LLaMa-SciQ, an educational chatbot designed to assist college students in solving and understanding MCQs in STEM fields. We begin by fine-tuning and aligning the models to human preferences. After comparing the performance of Mistral-7B and LLaMa-8B, we selected the latter as the base model due to its higher evaluation accuracy. To further enhance accuracy, we implement Retrieval-Augmented Generation (RAG) and apply quantization to compress the model, reducing inference time and increasing accessibility for students. For mathematical reasoning, LLaMa-SciQ achieved 74.5% accuracy on the GSM8k dataset and 30% on the MATH dataset. However, RAG does not improve performance and even reduces it, likely due to retriever issues or the model's unfamiliarity with context. Despite this, the quantized model shows only a 5% loss in performance, demonstrating significant efficiency improvements.
Learning Control Policies for Region Stabilization in Stochastic Systems
Oct 11, 2022
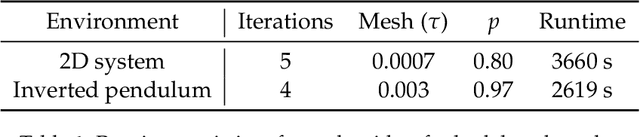
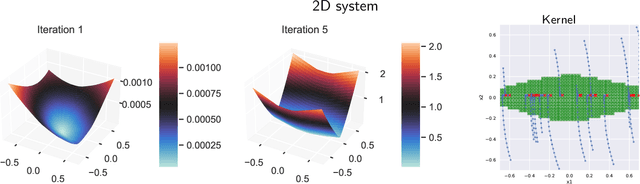
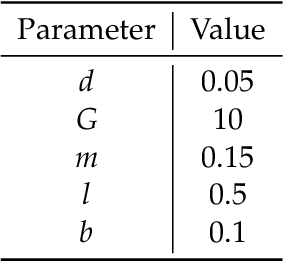
We consider the problem of learning control policies in stochastic systems which guarantee that the system stabilizes within some specified stabilization region with probability $1$. Our approach is based on the novel notion of stabilizing ranking supermartingales (sRSMs) that we introduce in this work. Our sRSMs overcome the limitation of methods proposed in previous works whose applicability is restricted to systems in which the stabilizing region cannot be left once entered under any control policy. We present a learning procedure that learns a control policy together with an sRSM that formally certifies probability-$1$ stability, both learned as neural networks. Our experimental evaluation shows that our learning procedure can successfully learn provably stabilizing policies in practice.