 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalluHard: A Hard Multi-Turn Hallucination Benchmark
Feb 01, 2026Large language models (LLMs) still produce plausible-sounding but ungrounded factual claims, a problem that worsens in multi-turn dialogue as context grows and early errors cascade. We introduce $\textbf{HalluHard}$, a challenging multi-turn hallucination benchmark with 950 seed questions spanning four high-stakes domains: legal cases, research questions, medical guidelines, and coding. We operationalize groundedness by requiring inline citations for factual assertions. To support reliable evaluation in open-ended settings, we propose a judging pipeline that iteratively retrieves evidence via web search. It can fetch, filter, and parse full-text sources (including PDFs) to assess whether cited material actually supports the generated content. Across a diverse set of frontier proprietary and open-weight models, hallucinations remain substantial even with web search ($\approx 30\%$ for the strongest configuration, Opus-4.5 with web search), with content-grounding errors persisting at high rates. Finally, we show that hallucination behavior is shaped by model capacity, turn position, effective reasoning, and the type of knowledge required.
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
TiMoE: Time-Aware Mixture of Language Experts
Aug 12, 2025



Large language models (LLMs) are typically trained on fixed snapshots of the web, which means that their knowledge becomes stale and their predictions risk temporal leakage: relying on information that lies in the future relative to a query. We tackle this problem by pre-training from scratch a set of GPT-style experts on disjoint two-year slices of a 2013-2024 corpus and combining them through TiMoE, a Time-aware Mixture of Language Experts. At inference time, TiMoE masks all experts whose training window ends after the query timestamp and merges the remaining log-probabilities in a shared space, guaranteeing strict causal validity while retaining the breadth of multi-period knowledge. We also release TSQA, a 10k-question benchmark whose alternatives are explicitly labelled as past, future or irrelevant, allowing fine-grained measurement of temporal hallucinations. Experiments on eight standard NLP tasks plus TSQA show that a co-adapted TiMoE variant matches or exceeds the best single-period expert and cuts future-knowledge errors by up to 15%. Our results demonstrate that modular, time-segmented pre-training paired with causal routing is a simple yet effective path toward LLMs that stay chronologically grounded without sacrificing general performance much. We open source our code at TiMoE (Github): https://github.com/epfml/TiMoE
URLs Help, Topics Guide: Understanding Metadata Utility in LLM Training
May 22, 2025Large Language Models (LLMs) are commonly pretrained on vast corpora of text without utilizing contextual metadata such as source, quality, or topic, leading to a context-free learning paradigm. While recent studies suggest that adding metadata like URL information as context (i.e., auxiliary inputs not used in the loss calculation) can improve training efficiency and downstream performance, they offer limited understanding of which types of metadata are truly effective and under what conditions. In this work, we conduct a systematic evaluation and find that not all metadata types contribute equally. Only URL context speeds up training, whereas quality scores and topic/format domain information offer no clear benefit. Furthermore, the improved downstream performances of URL conditioning emerge only when longer prompts are used at inference time. In addition, we demonstrate that context-aware pretraining enables more controllable generation than context-free pretraining, in a classifier-free guidance fashion. Although topic and format metadata do not accelerate training, they are effective for steering outputs, offering human-interpretable control over generation.
Can Performant LLMs Be Ethical? Quantifying the Impact of Web Crawling Opt-Outs
Apr 08, 2025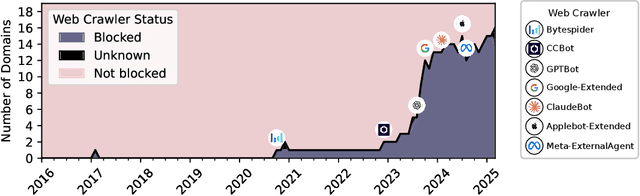



The increasing adoption of web crawling opt-outs by copyright holders of online content raises critical questions about the impact of data compliance on large language model (LLM) performance. However, little is known about how these restrictions (and the resultant filtering of pretraining datasets) affect the capabilities of models trained using these corpora. In this work, we conceptualize this effect as the $\textit{data compliance gap}$ (DCG), which quantifies the performance difference between models trained on datasets that comply with web crawling opt-outs, and those that do not. We measure the data compliance gap in two settings: pretraining models from scratch and continual pretraining from existing compliant models (simulating a setting where copyrighted data could be integrated later in pretraining). Our experiments with 1.5B models show that, as of January 2025, compliance with web data opt-outs does not degrade general knowledge acquisition (close to 0\% DCG). However, in specialized domains such as biomedical research, excluding major publishers leads to performance declines. These findings suggest that while general-purpose LLMs can be trained to perform equally well using fully open data, performance in specialized domains may benefit from access to high-quality copyrighted sources later in training. Our study provides empirical insights into the long-debated trade-off between data compliance and downstream model performance, informing future discussions on AI training practices and policy decisions.
From Fairness to Truthfulness: Rethinking Data Valuation Design
Apr 07, 2025

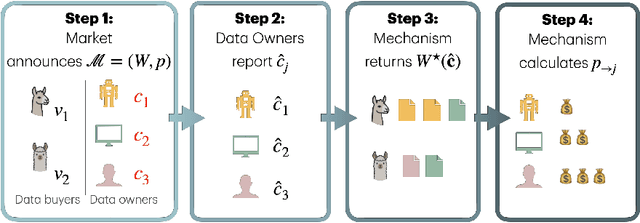

As large language models increasingly rely on external data sources, fairly compensating data contributors has become a central concern. In this paper, we revisit the design of data markets through a game-theoretic lens, where data owners face private, heterogeneous costs for data sharing. We show that commonly used valuation methods--such as Leave-One-Out and Data Shapley--fail to ensure truthful reporting of these costs, leading to inefficient market outcomes. To address this, we adapt well-established payment rules from mechanism design, namely Myerson and Vickrey-Clarke-Groves (VCG), to the data market setting. We demonstrate that the Myerson payment is the minimal truthful payment mechanism, optimal from the buyer's perspective, and that VCG and Myerson payments coincide in unconstrained allocation settings. Our findings highlight the importance of incorporating incentive compatibility into data valuation, paving the way for more robust and efficient data markets.
On-device Collaborative Language Modeling via a Mixture of Generalists and Specialists
Sep 20, 2024We target on-device collaborative fine-tuning of Large Language Models (LLMs) by adapting a Mixture of Experts (MoE) architecture, where experts are Low-Rank Adaptation (LoRA) modules. In conventional MoE approaches, experts develop into specialists throughout training. In contrast, we propose a novel $\textbf{Co}$llaborative learning approach via a $\textbf{Mi}$xture of $\textbf{G}$eneralists and $\textbf{S}$pecialists (CoMiGS). Diversifying into the two roles is achieved by aggregating certain experts globally while keeping others localized to specialize in user-specific datasets. Central to our work is a learnable routing network that routes at a token level, balancing collaboration and personalization at the finest granularity. Our method consistently demonstrates superior performance in scenarios with high data heterogeneity across various datasets. By design, our approach accommodates varying computational resource constraints among users as shown in different numbers of LoRA experts. We further showcase that low-resourced users can benefit from high-resourced users with high data quantity.
Personalized Collaborative Fine-Tuning for On-Device Large Language Models
Apr 15, 2024



We explore on-device self-supervised collaborative fine-tuning of large language models with limited local data availability. Taking inspiration from the collaborative learning community, we introduce three distinct trust-weighted gradient aggregation schemes: weight similarity-based, prediction similarity-based and validation performance-based. To minimize communication overhead, we integrate Low-Rank Adaptation (LoRA) and only exchange LoRA weight updates. Our protocols, driven by prediction and performance metrics, surpass both FedAvg and local fine-tuning methods, which is particularly evident in realistic scenarios with more diverse local data distributions. The results underscore the effectiveness of our approach in addressing heterogeneity and scarcity within local datasets.
Towards an empirical understanding of MoE design choices
Feb 20, 2024In this study, we systematically evaluate the impact of common design choices in Mixture of Experts (MoEs) on validation performance, uncovering distinct influences at token and sequence levels. We also present empirical evidence showing comparable performance between a learned router and a frozen, randomly initialized router, suggesting that learned routing may not be essential. Our study further reveals that Sequence-level routing can result in topic-specific weak expert specialization, in contrast to syntax specialization observed with Token-level routing.
Collaborative Learning via Prediction Consensus
May 29, 2023We consider a collaborative learning setting where each agent's goal is to improve their own model by leveraging the expertise of collaborators, in addition to their own training data. To facilitate the exchange of expertise among agents, we propose a distillation-based method leveraging unlabeled auxiliary data, which is pseudo-labeled by the collective. Central to our method is a trust weighting scheme which serves to adaptively weigh the influence of each collaborator on the pseudo-labels until a consensus on how to label the auxiliary data is reached. We demonstrate that our collaboration scheme is able to significantly boost individual model's performance with respect to the global distribution, compared to local training. At the same time, the adaptive trust weights can effectively identify and mitigate the negative impact of bad models on the collective. We find that our method is particularly effective in the presence of heterogeneity among individual agents, both in terms of training data as well as model architectures.