 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Concept-Spilling Across Languages in LLMs
Jan 18, 2026Multilingual Large Language Models (LLMs) exhibit remarkable cross-lingual abilities, yet often exhibit a systematic bias toward the representations from other languages, resulting in semantic interference when generating content in non-English languages$-$a phenomenon we define as language spilling. This paper presents a novel comparative framework for evaluating multilingual semantic robustness by systematically measuring how models handle polysemous words across languages. Our methodology provides a relative measure of model performance: when required to generate exactly five meanings, both strong and weak models may resort to meanings from dominant languages, but semantically stronger models do so later in the generation sequence, producing more true meanings from the target language before failing, while weaker models resort to dominant-language meanings earlier in the sequence. We evaluate a diverse set of open and closed multilingual LLMs using a structured meaning generation task across nine languages, employing a carefully curated benchmark of 100 high-polysemy English words. Our findings reveal significant variation in semantic robustness across both models and languages, providing a principled ranking system for model comparison without requiring definitive causal attribution of error sources. We contribute both a scalable comparative benchmark for multilingual semantic evaluation and a rigorous validation pipeline$-$critical tools for developing more linguistically balanced AI systems.
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
Towards Fully FP8 GEMM LLM Training at Scale
May 26, 2025Despite the significant potential of FP8 data formats for large language model (LLM) pre-training, their adoption has been limited due to challenges in maintaining stability at scale. Existing approaches often rely on suboptimal fine-grained FP8 kernels or fall back to higher-precision matrix multiplications (GEMMs) in sensitive components, such as attention projections, compromising potential throughput gains. We introduce a new class of LLM architectures that, for the first time, support FP8 computation for all GEMMs within transformer blocks during both forward and backward passes. This enables unprecedented throughput gains, particularly at scale, while matching the downstream performance of standard BF16 training. Our architecture design reduces large outlier activations, promoting stable long-term FP8 training. In addition, we identify key metrics to monitor low-precision training and predict potential future divergences.
Positional Fragility in LLMs: How Offset Effects Reshape Our Understanding of Memorization Risks
May 19, 2025Large language models are known to memorize parts of their training data, posing risk of copyright violations. To systematically examine this risk, we pretrain language models (1B/3B/8B) from scratch on 83B tokens, mixing web-scale data with public domain books used to simulate copyrighted content at controlled frequencies at lengths at least ten times longer than prior work. We thereby identified the offset effect, a phenomenon characterized by two key findings: (1) verbatim memorization is most strongly triggered by short prefixes drawn from the beginning of the context window, with memorization decreasing counterintuitively as prefix length increases; and (2) a sharp decline in verbatim recall when prefix begins offset from the initial tokens of the context window. We attribute this to positional fragility: models rely disproportionately on the earliest tokens in their context window as retrieval anchors, making them sensitive to even slight shifts. We further observe that when the model fails to retrieve memorized content, it often produces degenerated text. Leveraging these findings, we show that shifting sensitive data deeper into the context window suppresses both extractable memorization and degeneration. Our results suggest that positional offset is a critical and previously overlooked axis for evaluating memorization risks, since prior work implicitly assumed uniformity by probing only from the beginning of training sequences.
Can Performant LLMs Be Ethical? Quantifying the Impact of Web Crawling Opt-Outs
Apr 08, 2025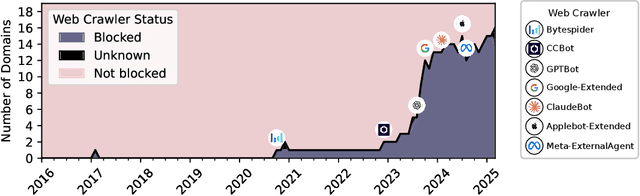



The increasing adoption of web crawling opt-outs by copyright holders of online content raises critical questions about the impact of data compliance on large language model (LLM) performance. However, little is known about how these restrictions (and the resultant filtering of pretraining datasets) affect the capabilities of models trained using these corpora. In this work, we conceptualize this effect as the $\textit{data compliance gap}$ (DCG), which quantifies the performance difference between models trained on datasets that comply with web crawling opt-outs, and those that do not. We measure the data compliance gap in two settings: pretraining models from scratch and continual pretraining from existing compliant models (simulating a setting where copyrighted data could be integrated later in pretraining). Our experiments with 1.5B models show that, as of January 2025, compliance with web data opt-outs does not degrade general knowledge acquisition (close to 0\% DCG). However, in specialized domains such as biomedical research, excluding major publishers leads to performance declines. These findings suggest that while general-purpose LLMs can be trained to perform equally well using fully open data, performance in specialized domains may benefit from access to high-quality copyrighted sources later in training. Our study provides empirical insights into the long-debated trade-off between data compliance and downstream model performance, informing future discussions on AI training practices and policy decisions.
INCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
Nov 29, 2024



The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
Understanding and Minimising Outlier Features in Neural Network Training
May 29, 2024Outlier Features (OF) are neurons whose activation magnitudes significantly exceed the average over a neural network's (NN) width. They are well known to emerge during standard transformer training and have the undesirable effect of hindering quantisation in afflicted models. Despite their practical importance, little is known behind why OFs emerge during training, nor how one can minimise them. Our work focuses on the above questions, first identifying several quantitative metrics, such as the kurtosis over neuron activation norms, to measure OFs. With these metrics, we study how architectural and optimisation choices influence OFs, and provide practical insights to minimise OFs during training. As highlights, we emphasise the importance of controlling signal propagation throughout training, and propose the Outlier Protected transformer block, which removes standard Pre-Norm layers to mitigate OFs, without loss of convergence speed or training stability. Overall, our findings shed new light on our understanding of, our ability to prevent, and the complexity of this important facet in NN training dynamics.
Language Imbalance Can Boost Cross-lingual Generalisation
Apr 11, 2024Multilinguality is crucial for extending recent advancements in language modelling to diverse linguistic communities. To maintain high performance while representing multiple languages, multilingual models ideally align representations, allowing what is learned in one language to generalise to others. Prior research has emphasised the importance of parallel data and shared vocabulary elements as key factors for such alignment. In this study, we investigate an unintuitive novel driver of cross-lingual generalisation: language imbalance. In controlled experiments on perfectly equivalent cloned languages, we observe that the existence of a predominant language during training boosts the performance of less frequent languages and leads to stronger alignment of model representations across languages. Furthermore, we find that this trend is amplified with scale: with large enough models or long enough training, we observe that bilingual training data with a 90/10 language split yields better performance on both languages than a balanced 50/50 split. Building on these insights, we design training schemes that can improve performance in all cloned languages, even without altering the training data. As we extend our analysis to real languages, we find that infrequent languages still benefit from frequent ones, yet whether language imbalance causes cross-lingual generalisation there is not conclusive.
On the Effect of Duplicate Subwords in Language Modelling
Apr 09, 2024



Tokenisation is a core part of language models (LMs). It involves splitting a character sequence into subwords which are assigned arbitrary indices before being served to the LM. While typically lossless, however, this process may lead to less sample efficient LM training: as it removes character-level information, it could make it harder for LMs to generalise across similar subwords, such as now and Now. We refer to such subwords as near duplicates. In this paper, we study the impact of near duplicate subwords on LM training efficiency. First, we design an experiment that gives us an upper bound to how much we should expect a model to improve if we could perfectly generalise across near duplicates. We do this by duplicating each subword in our LM's vocabulary, creating perfectly equivalent classes of subwords. Experimentally, we find that LMs need roughly 17% more data when trained in a fully duplicated setting. Second, we investigate the impact of naturally occurring near duplicates on LMs. Here, we see that merging them considerably hurts LM performance. Therefore, although subword duplication negatively impacts LM training efficiency, naturally occurring near duplicates may not be as similar as anticipated, limiting the potential for performance improvements.
The Languini Kitchen: Enabling Language Modelling Research at Different Scales of Compute
Sep 20, 2023



The Languini Kitchen serves as both a research collective and codebase designed to empower researchers with limited computational resources to contribute meaningfully to the field of language modelling. We introduce an experimental protocol that enables model comparisons based on equivalent compute, measured in accelerator hours. The number of tokens on which a model is trained is defined by the model's throughput and the chosen compute class. Notably, this approach avoids constraints on critical hyperparameters which affect total parameters or floating-point operations. For evaluation, we pre-process an existing large, diverse, and high-quality dataset of books that surpasses existing academic benchmarks in quality, diversity, and document length. On it, we compare methods based on their empirical scaling trends which are estimated through experiments at various levels of compute. This work also provides two baseline models: a feed-forward model derived from the GPT-2 architecture and a recurrent model in the form of a novel LSTM with ten-fold throughput. While the GPT baseline achieves better perplexity throughout all our levels of compute, our LSTM baseline exhibits a predictable and more favourable scaling law. This is due to the improved throughput and the need for fewer training tokens to achieve the same decrease in test perplexity. Extrapolating the scaling laws leads of both models results in an intersection at roughly 50,000 accelerator hours. We hope this work can serve as the foundation for meaningful and reproducible language modelling research.