 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Complex-Weighted Autoencoders for Unsupervised Object Discovery
May 28, 2024


Current state-of-the-art synchrony-based models encode object bindings with complex-valued activations and compute with real-valued weights in feedforward architectures. We argue for the computational advantages of a recurrent architecture with complex-valued weights. We propose a fully convolutional autoencoder, SynCx, that performs iterative constraint satisfaction: at each iteration, a hidden layer bottleneck encodes statistically regular configurations of features in particular phase relationships; over iterations, local constraints propagate and the model converges to a globally consistent configuration of phase assignments. Binding is achieved simply by the matrix-vector product operation between complex-valued weights and activations, without the need for additional mechanisms that have been incorporated into current synchrony-based models. SynCx outperforms or is strongly competitive with current models for unsupervised object discovery. SynCx also avoids certain systematic grouping errors of current models, such as the inability to separate similarly colored objects without additional supervision.
Towards Truly Zero-shot Compositional Visual Reasoning with LLMs as Programmers
Jan 03, 2024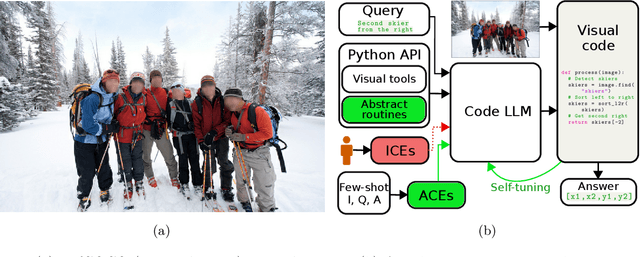
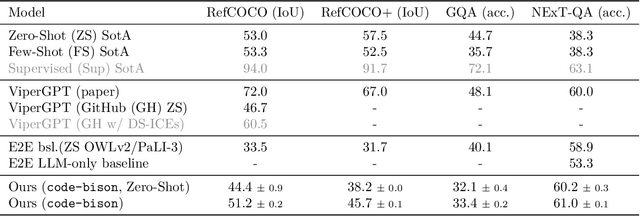
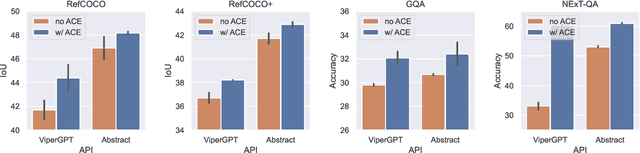

Visual reasoning is dominated by end-to-end neural networks scaled to billions of model parameters and training examples. However, even the largest models struggle with compositional reasoning, generalization, fine-grained spatial and temporal reasoning, and counting. Visual reasoning with large language models (LLMs) as controllers can, in principle, address these limitations by decomposing the task and solving subtasks by orchestrating a set of (visual) tools. Recently, these models achieved great performance on tasks such as compositional visual question answering, visual grounding, and video temporal reasoning. Nevertheless, in their current form, these models heavily rely on human engineering of in-context examples in the prompt, which are often dataset- and task-specific and require significant labor by highly skilled programmers. In this work, we present a framework that mitigates these issues by introducing spatially and temporally abstract routines and by leveraging a small number of labeled examples to automatically generate in-context examples, thereby avoiding human-created in-context examples. On a number of visual reasoning tasks, we show that our framework leads to consistent gains in performance, makes LLMs as controllers setup more robust, and removes the need for human engineering of in-context examples.
The Languini Kitchen: Enabling Language Modelling Research at Different Scales of Compute
Sep 20, 2023



The Languini Kitchen serves as both a research collective and codebase designed to empower researchers with limited computational resources to contribute meaningfully to the field of language modelling. We introduce an experimental protocol that enables model comparisons based on equivalent compute, measured in accelerator hours. The number of tokens on which a model is trained is defined by the model's throughput and the chosen compute class. Notably, this approach avoids constraints on critical hyperparameters which affect total parameters or floating-point operations. For evaluation, we pre-process an existing large, diverse, and high-quality dataset of books that surpasses existing academic benchmarks in quality, diversity, and document length. On it, we compare methods based on their empirical scaling trends which are estimated through experiments at various levels of compute. This work also provides two baseline models: a feed-forward model derived from the GPT-2 architecture and a recurrent model in the form of a novel LSTM with ten-fold throughput. While the GPT baseline achieves better perplexity throughout all our levels of compute, our LSTM baseline exhibits a predictable and more favourable scaling law. This is due to the improved throughput and the need for fewer training tokens to achieve the same decrease in test perplexity. Extrapolating the scaling laws leads of both models results in an intersection at roughly 50,000 accelerator hours. We hope this work can serve as the foundation for meaningful and reproducible language modelling research.
Mindstorms in Natural Language-Based Societies of Mind
May 26, 2023



Both Minsky's "society of mind" and Schmidhuber's "learning to think" inspire diverse societies of large multimodal neural networks (NNs) that solve problems by interviewing each other in a "mindstorm." Recent implementations of NN-based societies of minds consist of large language models (LLMs) and other NN-based experts communicating through a natural language interface. In doing so, they overcome the limitations of single LLMs, improving multimodal zero-shot reasoning. In these natural language-based societies of mind (NLSOMs), new agents -- all communicating through the same universal symbolic language -- are easily added in a modular fashion. To demonstrate the power of NLSOMs, we assemble and experiment with several of them (having up to 129 members), leveraging mindstorms in them to solve some practical AI tasks: visual question answering, image captioning, text-to-image synthesis, 3D generation, egocentric retrieval, embodied AI, and general language-based task solving. We view this as a starting point towards much larger NLSOMs with billions of agents-some of which may be humans. And with this emergence of great societies of heterogeneous minds, many new research questions have suddenly become paramount to the future of artificial intelligence. What should be the social structure of an NLSOM? What would be the (dis)advantages of having a monarchical rather than a democratic structure? How can principles of NN economies be used to maximize the total reward of a reinforcement learning NLSOM? In this work, we identify, discuss, and try to answer some of these questions.
Contrastive Training of Complex-Valued Autoencoders for Object Discovery
May 25, 2023



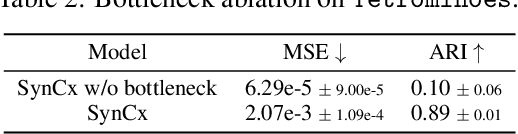
Current state-of-the-art object-centric models use slots and attention-based routing for binding. However, this class of models has several conceptual limitations: the number of slots is hardwired; all slots have equal capacity; training has high computational cost; there are no object-level relational factors within slots. Synchrony-based models in principle can address these limitations by using complex-valued activations which store binding information in their phase components. However, working examples of such synchrony-based models have been developed only very recently, and are still limited to toy grayscale datasets and simultaneous storage of less than three objects in practice. Here we introduce architectural modifications and a novel contrastive learning method that greatly improve the state-of-the-art synchrony-based model. For the first time, we obtain a class of synchrony-based models capable of discovering objects in an unsupervised manner in multi-object color datasets and simultaneously representing more than three objects
Learning to Generalize with Object-centric Agents in the Open World Survival Game Crafter
Aug 05, 2022
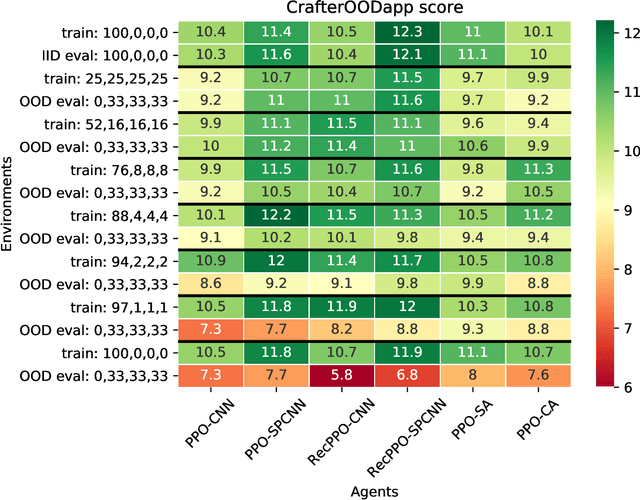
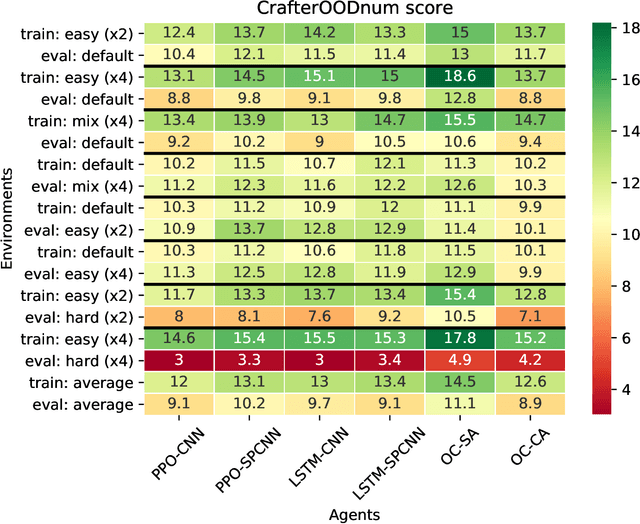
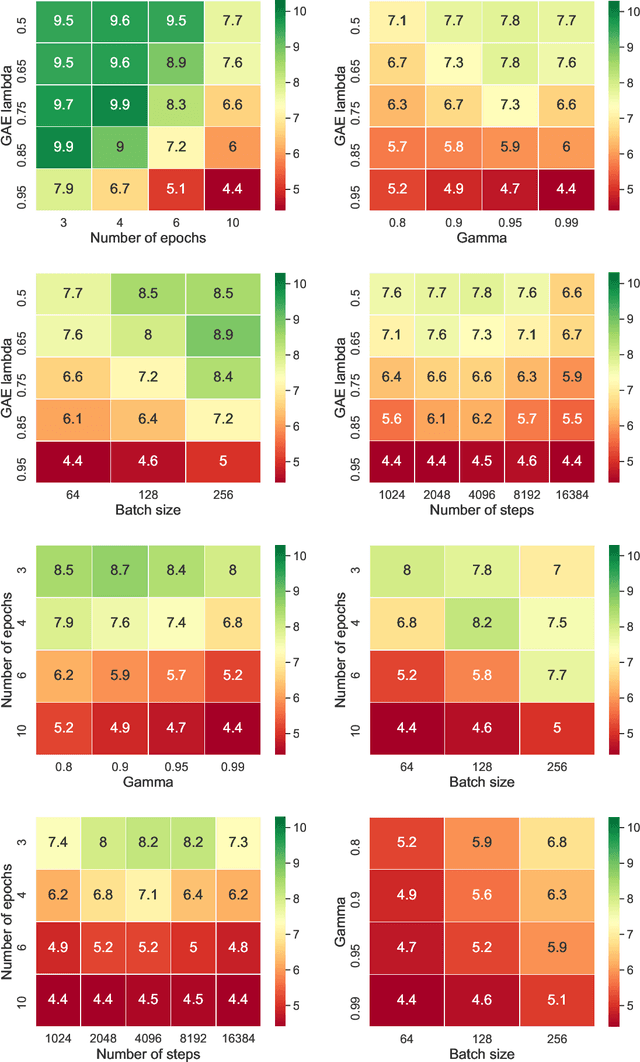
Reinforcement learning agents must generalize beyond their training experience. Prior work has focused mostly on identical training and evaluation environments. Starting from the recently introduced Crafter benchmark, a 2D open world survival game, we introduce a new set of environments suitable for evaluating some agent's ability to generalize on previously unseen (numbers of) objects and to adapt quickly (meta-learning). In Crafter, the agents are evaluated by the number of unlocked achievements (such as collecting resources) when trained for 1M steps. We show that current agents struggle to generalize, and introduce novel object-centric agents that improve over strong baselines. We also provide critical insights of general interest for future work on Crafter through several experiments. We show that careful hyper-parameter tuning improves the PPO baseline agent by a large margin and that even feedforward agents can unlock almost all achievements by relying on the inventory display. We achieve new state-of-the-art performance on the original Crafter environment. Additionally, when trained beyond 1M steps, our tuned agents can unlock almost all achievements. We show that the recurrent PPO agents improve over feedforward ones, even with the inventory information removed. We introduce CrafterOOD, a set of 15 new environments that evaluate OOD generalization. On CrafterOOD, we show that the current agents fail to generalize, whereas our novel object-centric agents achieve state-of-the-art OOD generalization while also being interpretable. Our code is public.
Spatial Dependency Networks: Neural Layers for Improved Generative Image Modeling
Mar 16, 2021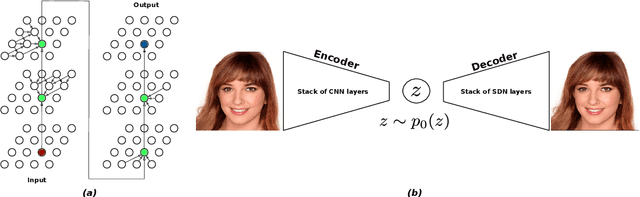
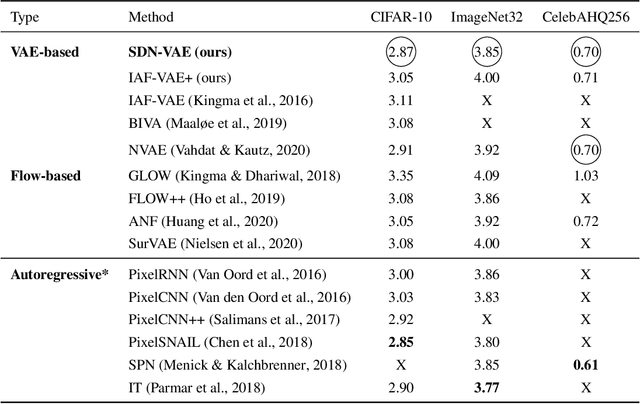
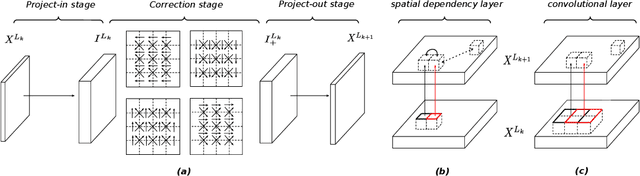
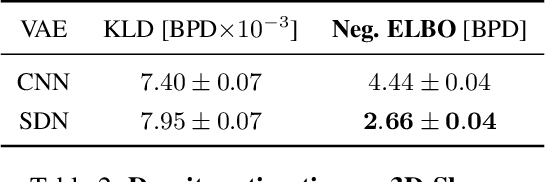
How to improve generative modeling by better exploiting spatial regularities and coherence in images? We introduce a novel neural network for building image generators (decoders) and apply it to variational autoencoders (VAEs). In our spatial dependency networks (SDNs), feature maps at each level of a deep neural net are computed in a spatially coherent way, using a sequential gating-based mechanism that distributes contextual information across 2-D space. We show that augmenting the decoder of a hierarchical VAE by spatial dependency layers considerably improves density estimation over baseline convolutional architectures and the state-of-the-art among the models within the same class. Furthermore, we demonstrate that SDN can be applied to large images by synthesizing samples of high quality and coherence. In a vanilla VAE setting, we find that a powerful SDN decoder also improves learning disentangled representations, indicating that neural architectures play an important role in this task. Our results suggest favoring spatial dependency over convolutional layers in various VAE settings. The accompanying source code is given at https://github.com/djordjemila/sdn.
Hierarchical Relational Inference
Oct 07, 2020

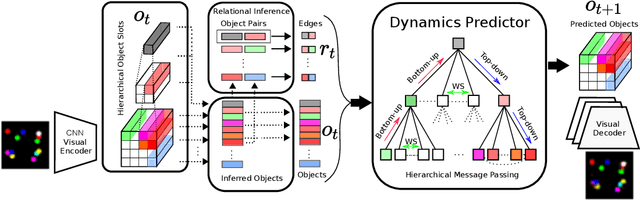

Common-sense physical reasoning in the real world requires learning about the interactions of objects and their dynamics. The notion of an abstract object, however, encompasses a wide variety of physical objects that differ greatly in terms of the complex behaviors they support. To address this, we propose a novel approach to physical reasoning that models objects as hierarchies of parts that may locally behave separately, but also act more globally as a single whole. Unlike prior approaches, our method learns in an unsupervised fashion directly from raw visual images to discover objects, parts, and their relations. It explicitly distinguishes multiple levels of abstraction and improves over a strong baseline at modeling synthetic and real-world videos.
R-SQAIR: Relational Sequential Attend, Infer, Repeat
Oct 11, 2019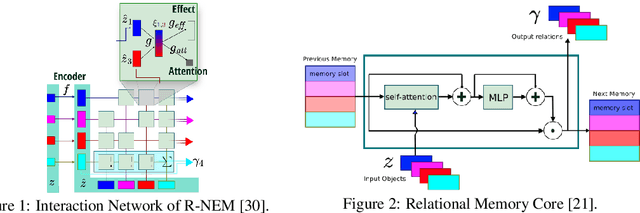

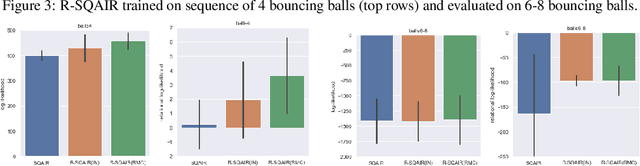
Traditional sequential multi-object attention models rely on a recurrent mechanism to infer object relations. We propose a relational extension (R-SQAIR) of one such attention model (SQAIR) by endowing it with a module with strong relational inductive bias that computes in parallel pairwise interactions between inferred objects. Two recently proposed relational modules are studied on tasks of unsupervised learning from videos. We demonstrate gains over sequential relational mechanisms, also in terms of combinatorial generalization.
Discrete Deep Feature Extraction: A Theory and New Architectures
May 26, 2016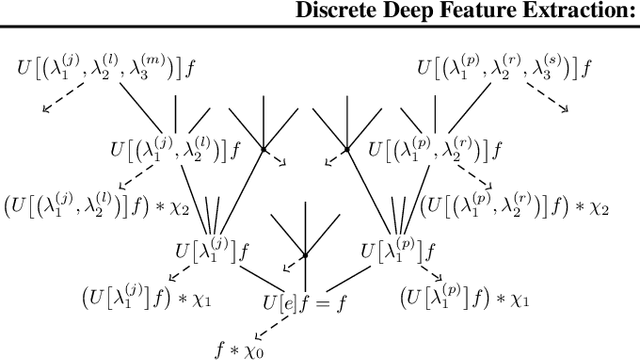


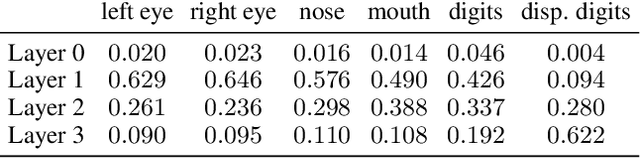
First steps towards a mathematical theory of deep convolutional neural networks for feature extraction were made---for the continuous-time case---in Mallat, 2012, and Wiatowski and B\"olcskei, 2015. This paper considers the discrete case, introduces new convolutional neural network architectures, and proposes a mathematical framework for their analysis. Specifically, we establish deformation and translation sensitivity results of local and global nature, and we investigate how certain structural properties of the input signal are reflected in the corresponding feature vectors. Our theory applies to general filters and general Lipschitz-continuous non-linearities and pooling operators. Experiments on handwritten digit classification and facial landmark detection---including feature importance evaluation---complement the theoretical findings.
* Proc. of International Conference on Machine Learning (ICML), New York, USA, June 2016, to appear