 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOrigami: An AI Pipeline for Co-Designing Flat-Foldable Visually Recognisable Origami
Jun 24, 2026While generative AI has achieved remarkable success in solving problems with verifiable solutions, generating physical art that satisfies both strict geometric constraints and subjective visual aesthetics remains a challenge. This paper presents an approach to tackle these difficulties in the domain of computational origami, a mathematically rigid environment that grounds artistic design within the equations of flat foldability. We present COrigami, an end-to-end AI-driven pipeline that assists the design cycle by generating crease patterns from natural language. Our pipeline involves generating a semantic stick figure, computing a base packing, solving for a flat-foldable crease pattern, shaping the flat-folded crease pattern, and refining the generated model using reinforcement learning driven by an autonomous aesthetic evaluation loop. Our system acts as a highly effective collaborative assistant, generating structural starting points that human artists can further expand and shape. By integrating algorithmic optimisation with autonomous aesthetic critique, this work demonstrates how AI systems can satisfy multi-objective physical constraints to enable reliable, mathematically grounded co-creativity.
On the Convergence and Stability of Upside-Down Reinforcement Learning, Goal-Conditioned Supervised Learning, and Online Decision Transformers
Feb 08, 2025This article provides a rigorous analysis of convergence and stability of Episodic Upside-Down Reinforcement Learning, Goal-Conditioned Supervised Learning and Online Decision Transformers. These algorithms performed competitively across various benchmarks, from games to robotic tasks, but their theoretical understanding is limited to specific environmental conditions. This work initiates a theoretical foundation for algorithms that build on the broad paradigm of approaching reinforcement learning through supervised learning or sequence modeling. At the core of this investigation lies the analysis of conditions on the underlying environment, under which the algorithms can identify optimal solutions. We also assess whether emerging solutions remain stable in situations where the environment is subject to tiny levels of noise. Specifically, we study the continuity and asymptotic convergence of command-conditioned policies, values and the goal-reaching objective depending on the transition kernel of the underlying Markov Decision Process. We demonstrate that near-optimal behavior is achieved if the transition kernel is located in a sufficiently small neighborhood of a deterministic kernel. The mentioned quantities are continuous (with respect to a specific topology) at deterministic kernels, both asymptotically and after a finite number of learning cycles. The developed methods allow us to present the first explicit estimates on the convergence and stability of policies and values in terms of the underlying transition kernels. On the theoretical side we introduce a number of new concepts to reinforcement learning, like working in segment spaces, studying continuity in quotient topologies and the application of the fixed-point theory of dynamical systems. The theoretical study is accompanied by a detailed investigation of example environments and numerical experiments.
Upside Down Reinforcement Learning with Policy Generators
Jan 27, 2025Upside Down Reinforcement Learning (UDRL) is a promising framework for solving reinforcement learning problems which focuses on learning command-conditioned policies. In this work, we extend UDRL to the task of learning a command-conditioned generator of deep neural network policies. We accomplish this using Hypernetworks - a variant of Fast Weight Programmers, which learn to decode input commands representing a desired expected return into command-specific weight matrices. Our method, dubbed Upside Down Reinforcement Learning with Policy Generators (UDRLPG), streamlines comparable techniques by removing the need for an evaluator or critic to update the weights of the generator. To counteract the increased variance in last returns caused by not having an evaluator, we decouple the sampling probability of the buffer from the absolute number of policies in it, which, together with a simple weighting strategy, improves the empirical convergence of the algorithm. Compared with existing algorithms, UDRLPG achieves competitive performance and high returns, sometimes outperforming more complex architectures. Our experiments show that a trained generator can generalize to create policies that achieve unseen returns zero-shot. The proposed method appears to be effective in mitigating some of the challenges associated with learning highly multimodal functions. Altogether, we believe that UDRLPG represents a promising step forward in achieving greater empirical sample efficiency in RL. A full implementation of UDRLPG is publicly available at https://github.com/JacopoD/udrlpg_
How to Correctly do Semantic Backpropagation on Language-based Agentic Systems
Dec 04, 2024Language-based agentic systems have shown great promise in recent years, transitioning from solving small-scale research problems to being deployed in challenging real-world tasks. However, optimizing these systems often requires substantial manual labor. Recent studies have demonstrated that these systems can be represented as computational graphs, enabling automatic optimization. Despite these advancements, most current efforts in Graph-based Agentic System Optimization (GASO) fail to properly assign feedback to the system's components given feedback on the system's output. To address this challenge, we formalize the concept of semantic backpropagation with semantic gradients -- a generalization that aligns several key optimization techniques, including reverse-mode automatic differentiation and the more recent TextGrad by exploiting the relationship among nodes with a common successor. This serves as a method for computing directional information about how changes to each component of an agentic system might improve the system's output. To use these gradients, we propose a method called semantic gradient descent which enables us to solve GASO effectively. Our results on both BIG-Bench Hard and GSM8K show that our approach outperforms existing state-of-the-art methods for solving GASO problems. A detailed ablation study on the LIAR dataset demonstrates the parsimonious nature of our method. A full copy of our implementation is publicly available at https://github.com/HishamAlyahya/semantic_backprop
Scaling Value Iteration Networks to 5000 Layers for Extreme Long-Term Planning
Jun 12, 2024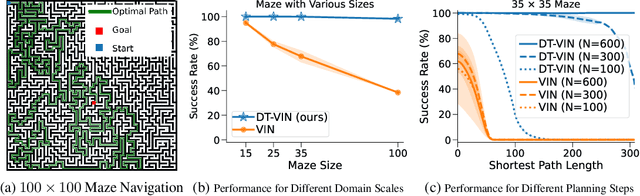

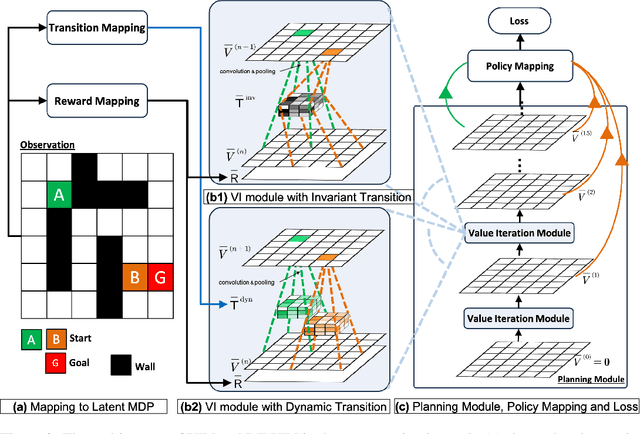

The Value Iteration Network (VIN) is an end-to-end differentiable architecture that performs value iteration on a latent MDP for planning in reinforcement learning (RL). However, VINs struggle to scale to long-term and large-scale planning tasks, such as navigating a $100\times 100$ maze -- a task which typically requires thousands of planning steps to solve. We observe that this deficiency is due to two issues: the representation capacity of the latent MDP and the planning module's depth. We address these by augmenting the latent MDP with a dynamic transition kernel, dramatically improving its representational capacity, and, to mitigate the vanishing gradient problem, introducing an "adaptive highway loss" that constructs skip connections to improve gradient flow. We evaluate our method on both 2D maze navigation environments and the ViZDoom 3D navigation benchmark. We find that our new method, named Dynamic Transition VIN (DT-VIN), easily scales to 5000 layers and casually solves challenging versions of the above tasks. Altogether, we believe that DT-VIN represents a concrete step forward in performing long-term large-scale planning in RL environments.
Highway Value Iteration Networks
Jun 05, 2024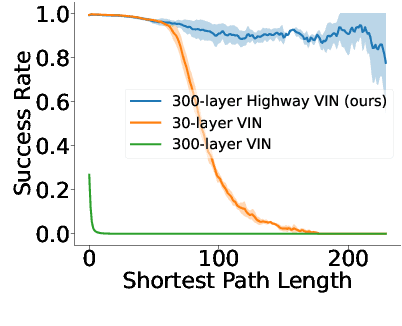



Value iteration networks (VINs) enable end-to-end learning for planning tasks by employing a differentiable "planning module" that approximates the value iteration algorithm. However, long-term planning remains a challenge because training very deep VINs is difficult. To address this problem, we embed highway value iteration -- a recent algorithm designed to facilitate long-term credit assignment -- into the structure of VINs. This improvement augments the "planning module" of the VIN with three additional components: 1) an "aggregate gate," which constructs skip connections to improve information flow across many layers; 2) an "exploration module," crafted to increase the diversity of information and gradient flow in spatial dimensions; 3) a "filter gate" designed to ensure safe exploration. The resulting novel highway VIN can be trained effectively with hundreds of layers using standard backpropagation. In long-term planning tasks requiring hundreds of planning steps, deep highway VINs outperform both traditional VINs and several advanced, very deep NNs.
Highway Reinforcement Learning
May 28, 2024



Learning from multi-step off-policy data collected by a set of policies is a core problem of reinforcement learning (RL). Approaches based on importance sampling (IS) often suffer from large variances due to products of IS ratios. Typical IS-free methods, such as $n$-step Q-learning, look ahead for $n$ time steps along the trajectory of actions (where $n$ is called the lookahead depth) and utilize off-policy data directly without any additional adjustment. They work well for proper choices of $n$. We show, however, that such IS-free methods underestimate the optimal value function (VF), especially for large $n$, restricting their capacity to efficiently utilize information from distant future time steps. To overcome this problem, we introduce a novel, IS-free, multi-step off-policy method that avoids the underestimation issue and converges to the optimal VF. At its core lies a simple but non-trivial \emph{highway gate}, which controls the information flow from the distant future by comparing it to a threshold. The highway gate guarantees convergence to the optimal VF for arbitrary $n$ and arbitrary behavioral policies. It gives rise to a novel family of off-policy RL algorithms that safely learn even when $n$ is very large, facilitating rapid credit assignment from the far future to the past. On tasks with greatly delayed rewards, including video games where the reward is given only at the end of the game, our new methods outperform many existing multi-step off-policy algorithms.
Towards a Robust Soft Baby Robot With Rich Interaction Ability for Advanced Machine Learning Algorithms
Apr 11, 2024Artificial intelligence has made great strides in many areas lately, yet it has had comparatively little success in general-use robotics. We believe one of the reasons for this is the disconnect between traditional robotic design and the properties needed for open-ended, creativity-based AI systems. To that end, we, taking selective inspiration from nature, build a robust, partially soft robotic limb with a large action space, rich sensory data stream from multiple cameras, and the ability to connect with others to enhance the action space and data stream. As a proof of concept, we train two contemporary machine learning algorithms to perform a simple target-finding task. Altogether, we believe that this design serves as a first step to building a robot tailor-made for achieving artificial general intelligence.
Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models
Apr 03, 2024This study explores the role of cross-attention during inference in text-conditional diffusion models. We find that cross-attention outputs converge to a fixed point after few inference steps. Accordingly, the time point of convergence naturally divides the entire inference process into two stages: an initial semantics-planning stage, during which, the model relies on cross-attention to plan text-oriented visual semantics, and a subsequent fidelity-improving stage, during which the model tries to generate images from previously planned semantics. Surprisingly, ignoring text conditions in the fidelity-improving stage not only reduces computation complexity, but also maintains model performance. This yields a simple and training-free method called TGATE for efficient generation, which caches the cross-attention output once it converges and keeps it fixed during the remaining inference steps. Our empirical study on the MS-COCO validation set confirms its effectiveness. The source code of TGATE is available at https://github.com/HaozheLiu-ST/T-GATE.
Learning Useful Representations of Recurrent Neural Network Weight Matrices
Mar 18, 2024Recurrent Neural Networks (RNNs) are general-purpose parallel-sequential computers. The program of an RNN is its weight matrix. How to learn useful representations of RNN weights that facilitate RNN analysis as well as downstream tasks? While the mechanistic approach directly looks at some RNN's weights to predict its behavior, the functionalist approach analyzes its overall functionality -- specifically, its input-output mapping. We consider several mechanistic approaches for RNN weights and adapt the permutation equivariant Deep Weight Space layer for RNNs. Our two novel functionalist approaches extract information from RNN weights by 'interrogating' the RNN through probing inputs. We develop a theoretical framework that demonstrates conditions under which the functionalist approach can generate rich representations that help determine RNN behavior. We create and release the first two 'model zoo' datasets for RNN weight representation learning. One consists of generative models of a class of formal languages, and the other one of classifiers of sequentially processed MNIST digits. With the help of an emulation-based self-supervised learning technique we compare and evaluate the different RNN weight encoding techniques on multiple downstream applications. On the most challenging one, namely predicting which exact task the RNN was trained on, functionalist approaches show clear superiority.