 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroSumEval: Scaling LLM Evaluation with Inter-Model Competition
Apr 17, 2025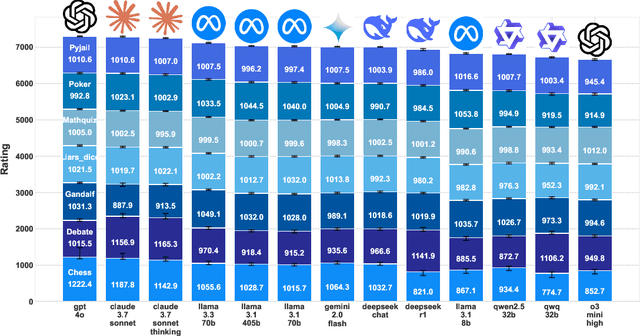



Evaluating the capabilities of Large Language Models (LLMs) has traditionally relied on static benchmark datasets, human assessments, or model-based evaluations - methods that often suffer from overfitting, high costs, and biases. ZeroSumEval is a novel competition-based evaluation protocol that leverages zero-sum games to assess LLMs with dynamic benchmarks that resist saturation. ZeroSumEval encompasses a diverse suite of games, including security challenges (PyJail), classic games (Chess, Liar's Dice, Poker), knowledge tests (MathQuiz), and persuasion challenges (Gandalf, Debate). These games are designed to evaluate a range of AI capabilities such as strategic reasoning, planning, knowledge application, and creativity. Building upon recent studies that highlight the effectiveness of game-based evaluations for LLMs, ZeroSumEval enhances these approaches by providing a standardized and extensible framework. To demonstrate this, we conduct extensive experiments with >7000 simulations across 7 games and 13 models. Our results show that while frontier models from the GPT and Claude families can play common games and answer questions, they struggle to play games that require creating novel and challenging questions. We also observe that models cannot reliably jailbreak each other and fail generally at tasks requiring creativity. We release our code at https://github.com/facebookresearch/ZeroSumEval.
How to Correctly do Semantic Backpropagation on Language-based Agentic Systems
Dec 04, 2024Language-based agentic systems have shown great promise in recent years, transitioning from solving small-scale research problems to being deployed in challenging real-world tasks. However, optimizing these systems often requires substantial manual labor. Recent studies have demonstrated that these systems can be represented as computational graphs, enabling automatic optimization. Despite these advancements, most current efforts in Graph-based Agentic System Optimization (GASO) fail to properly assign feedback to the system's components given feedback on the system's output. To address this challenge, we formalize the concept of semantic backpropagation with semantic gradients -- a generalization that aligns several key optimization techniques, including reverse-mode automatic differentiation and the more recent TextGrad by exploiting the relationship among nodes with a common successor. This serves as a method for computing directional information about how changes to each component of an agentic system might improve the system's output. To use these gradients, we propose a method called semantic gradient descent which enables us to solve GASO effectively. Our results on both BIG-Bench Hard and GSM8K show that our approach outperforms existing state-of-the-art methods for solving GASO problems. A detailed ablation study on the LIAR dataset demonstrates the parsimonious nature of our method. A full copy of our implementation is publicly available at https://github.com/HishamAlyahya/semantic_backprop
ALLaM: Large Language Models for Arabic and English
Jul 22, 2024



We present ALLaM: Arabic Large Language Model, a series of large language models to support the ecosystem of Arabic Language Technologies (ALT). ALLaM is carefully trained considering the values of language alignment and knowledge transfer at scale. Our autoregressive decoder-only architecture models demonstrate how second-language acquisition via vocabulary expansion and pretraining on a mixture of Arabic and English text can steer a model towards a new language (Arabic) without any catastrophic forgetting in the original language (English). Furthermore, we highlight the effectiveness of using parallel/translated data to aid the process of knowledge alignment between languages. Finally, we show that extensive alignment with human preferences can significantly enhance the performance of a language model compared to models of a larger scale with lower quality alignment. ALLaM achieves state-of-the-art performance in various Arabic benchmarks, including MMLU Arabic, ACVA, and Arabic Exams. Our aligned models improve both in Arabic and English from their base aligned models.