 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroSumEval: Scaling LLM Evaluation with Inter-Model Competition
Apr 17, 2025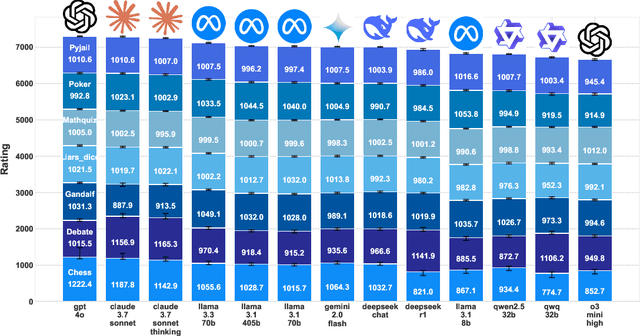



Evaluating the capabilities of Large Language Models (LLMs) has traditionally relied on static benchmark datasets, human assessments, or model-based evaluations - methods that often suffer from overfitting, high costs, and biases. ZeroSumEval is a novel competition-based evaluation protocol that leverages zero-sum games to assess LLMs with dynamic benchmarks that resist saturation. ZeroSumEval encompasses a diverse suite of games, including security challenges (PyJail), classic games (Chess, Liar's Dice, Poker), knowledge tests (MathQuiz), and persuasion challenges (Gandalf, Debate). These games are designed to evaluate a range of AI capabilities such as strategic reasoning, planning, knowledge application, and creativity. Building upon recent studies that highlight the effectiveness of game-based evaluations for LLMs, ZeroSumEval enhances these approaches by providing a standardized and extensible framework. To demonstrate this, we conduct extensive experiments with >7000 simulations across 7 games and 13 models. Our results show that while frontier models from the GPT and Claude families can play common games and answer questions, they struggle to play games that require creating novel and challenging questions. We also observe that models cannot reliably jailbreak each other and fail generally at tasks requiring creativity. We release our code at https://github.com/facebookresearch/ZeroSumEval.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Command R7B Arabic: A Small, Enterprise Focused, Multilingual, and Culturally Aware Arabic LLM
Mar 18, 2025Building high-quality large language models (LLMs) for enterprise Arabic applications remains challenging due to the limited availability of digitized Arabic data. In this work, we present a data synthesis and refinement strategy to help address this problem, namely, by leveraging synthetic data generation and human-in-the-loop annotation to expand our Arabic training corpus. We further present our iterative post training recipe that is essential to achieving state-of-the-art performance in aligning the model with human preferences, a critical aspect to enterprise use cases. The culmination of this effort is the release of a small, 7B, open-weight model that outperforms similarly sized peers in head-to-head comparisons and on Arabic-focused benchmarks covering cultural knowledge, instruction following, RAG, and contextual faithfulness.
ALLaM: Large Language Models for Arabic and English
Jul 22, 2024



We present ALLaM: Arabic Large Language Model, a series of large language models to support the ecosystem of Arabic Language Technologies (ALT). ALLaM is carefully trained considering the values of language alignment and knowledge transfer at scale. Our autoregressive decoder-only architecture models demonstrate how second-language acquisition via vocabulary expansion and pretraining on a mixture of Arabic and English text can steer a model towards a new language (Arabic) without any catastrophic forgetting in the original language (English). Furthermore, we highlight the effectiveness of using parallel/translated data to aid the process of knowledge alignment between languages. Finally, we show that extensive alignment with human preferences can significantly enhance the performance of a language model compared to models of a larger scale with lower quality alignment. ALLaM achieves state-of-the-art performance in various Arabic benchmarks, including MMLU Arabic, ACVA, and Arabic Exams. Our aligned models improve both in Arabic and English from their base aligned models.
When Benchmarks are Targets: Revealing the Sensitivity of Large Language Model Leaderboards
Feb 01, 2024



Large Language Model (LLM) leaderboards based on benchmark rankings are regularly used to guide practitioners in model selection. Often, the published leaderboard rankings are taken at face value - we show this is a (potentially costly) mistake. Under existing leaderboards, the relative performance of LLMs is highly sensitive to (often minute) details. We show that for popular multiple choice question benchmarks (e.g. MMLU) minor perturbations to the benchmark, such as changing the order of choices or the method of answer selection, result in changes in rankings up to 8 positions. We explain this phenomenon by conducting systematic experiments over three broad categories of benchmark perturbations and identifying the sources of this behavior. Our analysis results in several best-practice recommendations, including the advantage of a hybrid scoring method for answer selection. Our study highlights the dangers of relying on simple benchmark evaluations and charts the path for more robust evaluation schemes on the existing benchmarks.
Learning to Read Analog Gauges from Synthetic Data
Aug 28, 2023Manually reading and logging gauge data is time inefficient, and the effort increases according to the number of gauges available. We present a computer vision pipeline that automates the reading of analog gauges. We propose a two-stage CNN pipeline that identifies the key structural components of an analog gauge and outputs an angular reading. To facilitate the training of our approach, a synthetic dataset is generated thus obtaining a set of realistic analog gauges with their corresponding annotation. To validate our proposal, an additional real-world dataset was collected with 4.813 manually curated images. When compared against state-of-the-art methodologies, our method shows a significant improvement of 4.55 in the average error, which is a 52% relative improvement. The resources for this project will be made available at: https://github.com/fuankarion/automatic-gauge-reading.