 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Command R7B Arabic: A Small, Enterprise Focused, Multilingual, and Culturally Aware Arabic LLM
Mar 18, 2025Building high-quality large language models (LLMs) for enterprise Arabic applications remains challenging due to the limited availability of digitized Arabic data. In this work, we present a data synthesis and refinement strategy to help address this problem, namely, by leveraging synthetic data generation and human-in-the-loop annotation to expand our Arabic training corpus. We further present our iterative post training recipe that is essential to achieving state-of-the-art performance in aligning the model with human preferences, a critical aspect to enterprise use cases. The culmination of this effort is the release of a small, 7B, open-weight model that outperforms similarly sized peers in head-to-head comparisons and on Arabic-focused benchmarks covering cultural knowledge, instruction following, RAG, and contextual faithfulness.
Scalable Object Detection for Stylized Objects
Nov 29, 2017
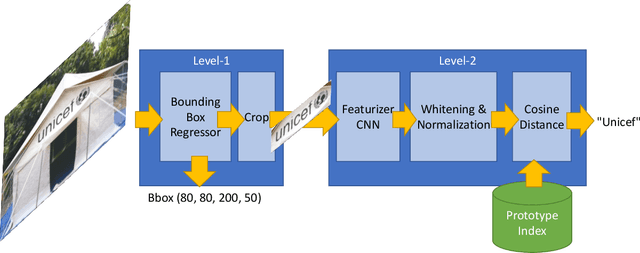


Following recent breakthroughs in convolutional neural networks and monolithic model architectures, state-of-the-art object detection models can reliably and accurately scale into the realm of up to thousands of classes. Things quickly break down, however, when scaling into the tens of thousands, or, eventually, to millions or billions of unique objects. Further, bounding box-trained end-to-end models require extensive training data. Even though - with some tricks using hierarchies - one can sometimes scale up to thousands of classes, the labor requirements for clean image annotations quickly get out of control. In this paper, we present a two-layer object detection method for brand logos and other stylized objects for which prototypical images exist. It can scale to large numbers of unique classes. Our first layer is a CNN from the Single Shot Multibox Detector family of models that learns to propose regions where some stylized object is likely to appear. The contents of a proposed bounding box is then run against an image index that is targeted for the retrieval task at hand. The proposed architecture scales to a large number of object classes, allows to continously add new classes without retraining, and exhibits state-of-the-art quality on a stylized object detection task such as logo recognition.