 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxaAdapter: Vision Taxonomy Models are Key to Fine-grained Image Generation over the Tree of Life
Mar 27, 2026Accurately generating images across the Tree of Life is difficult: there are over 10M distinct species on Earth, many of which differ only by subtle visual traits. Despite the remarkable progress in text-to-image synthesis, existing models often fail to capture the fine-grained visual cues that define species identity, even when their outputs appear photo-realistic. To this end, we propose TaxaAdapter, a simple and lightweight approach that incorporates Vision Taxonomy Models (VTMs) such as BioCLIP to guide fine-grained species generation. Our method injects VTM embeddings into a frozen text-to-image diffusion model, improving species-level fidelity while preserving flexible text control over attributes such as pose, style, and background. Extensive experiments demonstrate that TaxaAdapter consistently improves morphology fidelity and species-identity accuracy over strong baselines, with a cleaner architecture and training recipe. To better evaluate these improvements, we also introduce a multimodal Large Language Model-based metric that summarizes trait-level descriptions from generated and real images, providing a more interpretable measure of morphological consistency. Beyond this, we observe that TaxaAdapter exhibits strong generalization capabilities, enabling species synthesis in challenging regimes such as few-shot species with only a handful of training images and even species unseen during training. Overall, our results highlight that VTMs are a key ingredient for scalable, fine-grained species generation.
Continual Unlearning for Text-to-Image Diffusion Models: A Regularization Perspective
Nov 11, 2025Machine unlearning--the ability to remove designated concepts from a pre-trained model--has advanced rapidly, particularly for text-to-image diffusion models. However, existing methods typically assume that unlearning requests arrive all at once, whereas in practice they often arrive sequentially. We present the first systematic study of continual unlearning in text-to-image diffusion models and show that popular unlearning methods suffer from rapid utility collapse: after only a few requests, models forget retained knowledge and generate degraded images. We trace this failure to cumulative parameter drift from the pre-training weights and argue that regularization is crucial to addressing it. To this end, we study a suite of add-on regularizers that (1) mitigate drift and (2) remain compatible with existing unlearning methods. Beyond generic regularizers, we show that semantic awareness is essential for preserving concepts close to the unlearning target, and propose a gradient-projection method that constrains parameter drift orthogonal to their subspace. This substantially improves continual unlearning performance and is complementary to other regularizers for further gains. Taken together, our study establishes continual unlearning as a fundamental challenge in text-to-image generation and provides insights, baselines, and open directions for advancing safe and accountable generative AI.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Command R7B Arabic: A Small, Enterprise Focused, Multilingual, and Culturally Aware Arabic LLM
Mar 18, 2025Building high-quality large language models (LLMs) for enterprise Arabic applications remains challenging due to the limited availability of digitized Arabic data. In this work, we present a data synthesis and refinement strategy to help address this problem, namely, by leveraging synthetic data generation and human-in-the-loop annotation to expand our Arabic training corpus. We further present our iterative post training recipe that is essential to achieving state-of-the-art performance in aligning the model with human preferences, a critical aspect to enterprise use cases. The culmination of this effort is the release of a small, 7B, open-weight model that outperforms similarly sized peers in head-to-head comparisons and on Arabic-focused benchmarks covering cultural knowledge, instruction following, RAG, and contextual faithfulness.
CompBench: A Comparative Reasoning Benchmark for Multimodal LLMs
Jul 23, 2024
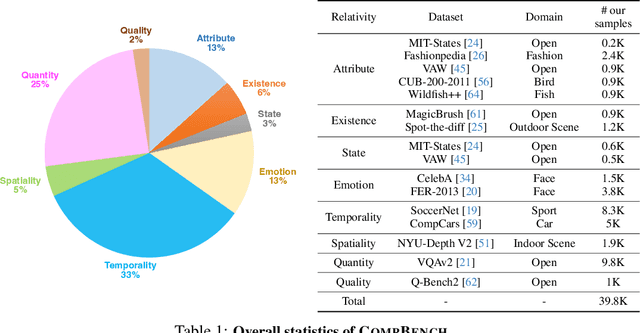
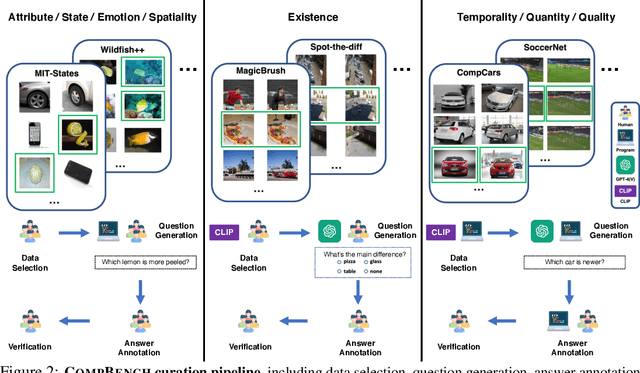
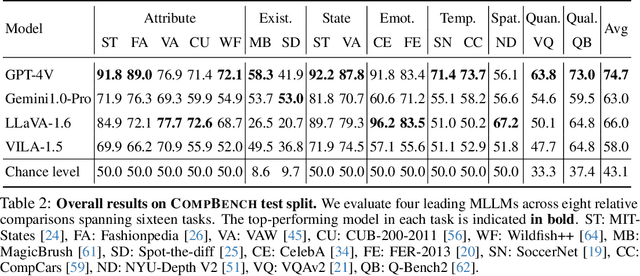
The ability to compare objects, scenes, or situations is crucial for effective decision-making and problem-solving in everyday life. For instance, comparing the freshness of apples enables better choices during grocery shopping, while comparing sofa designs helps optimize the aesthetics of our living space. Despite its significance, the comparative capability is largely unexplored in artificial general intelligence (AGI). In this paper, we introduce CompBench, a benchmark designed to evaluate the comparative reasoning capability of multimodal large language models (MLLMs). CompBench mines and pairs images through visually oriented questions covering eight dimensions of relative comparison: visual attribute, existence, state, emotion, temporality, spatiality, quantity, and quality. We curate a collection of around 40K image pairs using metadata from diverse vision datasets and CLIP similarity scores. These image pairs span a broad array of visual domains, including animals, fashion, sports, and both outdoor and indoor scenes. The questions are carefully crafted to discern relative characteristics between two images and are labeled by human annotators for accuracy and relevance. We use CompBench to evaluate recent MLLMs, including GPT-4V(ision), Gemini-Pro, and LLaVA-1.6. Our results reveal notable shortcomings in their comparative abilities. We believe CompBench not only sheds light on these limitations but also establishes a solid foundation for future enhancements in the comparative capability of MLLMs.
The Importance of Prompt Tuning for Automated Neuron Explanations
Oct 11, 2023Recent advances have greatly increased the capabilities of large language models (LLMs), but our understanding of the models and their safety has not progressed as fast. In this paper we aim to understand LLMs deeper by studying their individual neurons. We build upon previous work showing large language models such as GPT-4 can be useful in explaining what each neuron in a language model does. Specifically, we analyze the effect of the prompt used to generate explanations and show that reformatting the explanation prompt in a more natural way can significantly improve neuron explanation quality and greatly reduce computational cost. We demonstrate the effects of our new prompts in three different ways, incorporating both automated and human evaluations.
Robust Open-Set Spoken Language Identification and the CU MultiLang Dataset
Aug 29, 2023Most state-of-the-art spoken language identification models are closed-set; in other words, they can only output a language label from the set of classes they were trained on. Open-set spoken language identification systems, however, gain the ability to detect when an input exhibits none of the original languages. In this paper, we implement a novel approach to open-set spoken language identification that uses MFCC and pitch features, a TDNN model to extract meaningful feature embeddings, confidence thresholding on softmax outputs, and LDA and pLDA for learning to classify new unknown languages. We present a spoken language identification system that achieves 91.76% accuracy on trained languages and has the capability to adapt to unknown languages on the fly. To that end, we also built the CU MultiLang Dataset, a large and diverse multilingual speech corpus which was used to train and evaluate our system.
* 6pages, 1 table, 6 figures
ContriMix: Unsupervised disentanglement of content and attribute for domain generalization in microscopy image analysis
Jul 03, 2023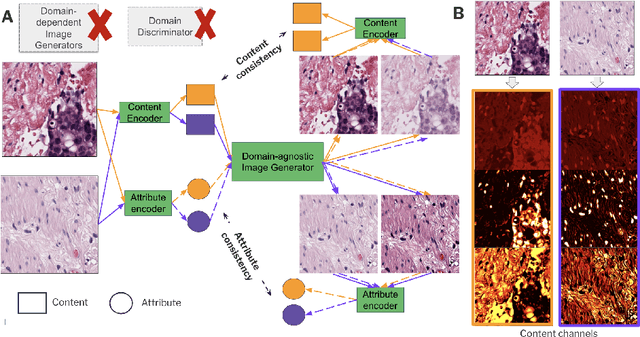


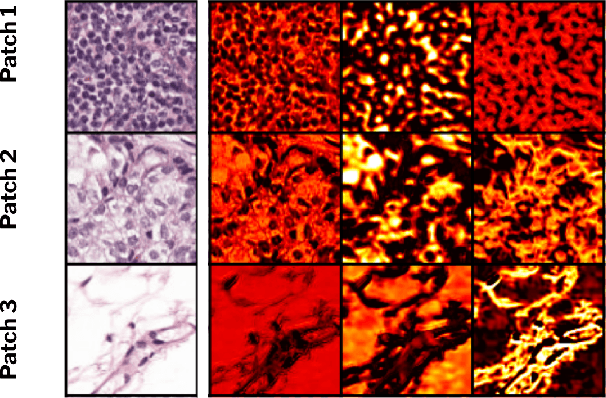
Domain generalization is critical for real-world applications of machine learning models to microscopy images, including histopathology and fluorescence imaging. Artifacts in histopathology arise through a complex combination of factors relating to tissue collection and laboratory processing, as well as factors intrinsic to patient samples. In fluorescence imaging, these artifacts stem from variations across experimental batches. The complexity and subtlety of these artifacts make the enumeration of data domains intractable. Therefore, augmentation-based methods of domain generalization that require domain identifiers and manual fine-tuning are inadequate in this setting. To overcome this challenge, we introduce ContriMix, a domain generalization technique that learns to generate synthetic images by disentangling and permuting the biological content ("content") and technical variations ("attributes") in microscopy images. ContriMix does not rely on domain identifiers or handcrafted augmentations and makes no assumptions about the input characteristics of images. We assess the performance of ContriMix on two pathology datasets (Camelyon17-WILDS and a prostate cell classification dataset) and one fluorescence microscopy dataset (RxRx1-WILDS). ContriMix outperforms current state-of-the-art methods in all datasets, motivating its usage for microscopy image analysis in real-world settings where domain information is hard to come by.
Boundary Attention Mapping (BAM): Fine-grained saliency maps for segmentation of Burn Injuries
May 24, 2023Burn injuries can result from mechanisms such as thermal, chemical, and electrical insults. A prompt and accurate assessment of burns is essential for deciding definitive clinical treatments. Currently, the primary approach for burn assessments, via visual and tactile observations, is approximately 60%-80% accurate. The gold standard is biopsy and a close second would be non-invasive methods like Laser Doppler Imaging (LDI) assessments, which have up to 97% accuracy in predicting burn severity and the required healing time. In this paper, we introduce a machine learning pipeline for assessing burn severities and segmenting the regions of skin that are affected by burn. Segmenting 2D colour images of burns allows for the injured versus non-injured skin to be delineated, clearly marking the extent and boundaries of the localized burn/region-of-interest, even during remote monitoring of a burn patient. We trained a convolutional neural network (CNN) to classify four severities of burns. We built a saliency mapping method, Boundary Attention Mapping (BAM), that utilises this trained CNN for the purpose of accurately localizing and segmenting the burn regions from skin burn images. We demonstrated the effectiveness of our proposed pipeline through extensive experiments and evaluations using two datasets; 1) A larger skin burn image dataset consisting of 1684 skin burn images of four burn severities, 2) An LDI dataset that consists of a total of 184 skin burn images with their associated LDI scans. The CNN trained using the first dataset achieved an average F1-Score of 78% and micro/macro- average ROC of 85% in classifying the four burn severities. Moreover, a comparison between the BAM results and LDI results for measuring injury boundary showed that the segmentations generated by our method achieved 91.60% accuracy, 78.17% sensitivity, and 93.37% specificity.
Synthetic DOmain-Targeted Augmentation (S-DOTA) Improves Model Generalization in Digital Pathology
May 03, 2023Machine learning algorithms have the potential to improve patient outcomes in digital pathology. However, generalization of these tools is currently limited by sensitivity to variations in tissue preparation, staining procedures and scanning equipment that lead to domain shift in digitized slides. To overcome this limitation and improve model generalization, we studied the effectiveness of two Synthetic DOmain-Targeted Augmentation (S-DOTA) methods, namely CycleGAN-enabled Scanner Transform (ST) and targeted Stain Vector Augmentation (SVA), and compared them against the International Color Consortium (ICC) profile-based color calibration (ICC Cal) method and a baseline method using traditional brightness, color and noise augmentations. We evaluated the ability of these techniques to improve model generalization to various tasks and settings: four models, two model types (tissue segmentation and cell classification), two loss functions, six labs, six scanners, and three indications (hepatocellular carcinoma (HCC), nonalcoholic steatohepatitis (NASH), prostate adenocarcinoma). We compared these methods based on the macro-averaged F1 scores on in-distribution (ID) and out-of-distribution (OOD) test sets across multiple domains, and found that S-DOTA methods (i.e., ST and SVA) led to significant improvements over ICC Cal and baseline on OOD data while maintaining comparable performance on ID data. Thus, we demonstrate that S-DOTA may help address generalization due to domain shift in real world applications.