 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Selection and Particle Resampling for Inference-Time Scaling Beyond Domain Verifiability
Jun 07, 2026Inference-Time Scaling (ITS) has largely succeeded in verifiable domains like math and coding, where cheap verification enables scalable output selection. However, extending ITS to tasks prone to systematic failure - driven by faulty initial assumptions or unmet multidimensional constraints - typically relies on costly external solvers or brittle, model-based verifiers. Our key insight is that the intrinsic statistics of parallel sample sets, specifically length-adjusted tail entropy, provide a robust discriminative signal for solution quality without access to ground truth. Crucially, these statistics serve as a difficulty gate for adaptive compute allocation, dynamically routing problems across scaling regimes. First, Intrinsic Selection (iS) ranks candidates post-hoc, matching consensus-based algorithms across three domains and improving engineering design selection by 20% over pass@1 baselines. Second, Intrinsic Particle Filtering (iPF) generalizes this to step-level resampling, guiding generation toward high-confidence reasoning trajectories to improve pass@1 by 6.1 points on average on hard math problems. Finally, Particle Distillation (dPF) injects privileged guidance via early logit blending and KL-guided resampling, steering generation past systematic reasoning errors to satisfy expert rubrics, yielding up to 26.5% gains on complex clinical responses. Our pipeline applies seamlessly across broad-purpose, domain-specialized, and multimodal architectures, successfully extending ITS to open-ended domains without requiring trained reward models or exact ground-truth verification.
Sculpting Subspaces: Constrained Full Fine-Tuning in LLMs for Continual Learning
Apr 09, 2025Continual learning in large language models (LLMs) is prone to catastrophic forgetting, where adapting to new tasks significantly degrades performance on previously learned ones. Existing methods typically rely on low-rank, parameter-efficient updates that limit the model's expressivity and introduce additional parameters per task, leading to scalability issues. To address these limitations, we propose a novel continual full fine-tuning approach leveraging adaptive singular value decomposition (SVD). Our method dynamically identifies task-specific low-rank parameter subspaces and constrains updates to be orthogonal to critical directions associated with prior tasks, thus effectively minimizing interference without additional parameter overhead or storing previous task gradients. We evaluate our approach extensively on standard continual learning benchmarks using both encoder-decoder (T5-Large) and decoder-only (LLaMA-2 7B) models, spanning diverse tasks including classification, generation, and reasoning. Empirically, our method achieves state-of-the-art results, up to 7% higher average accuracy than recent baselines like O-LoRA, and notably maintains the model's general linguistic capabilities, instruction-following accuracy, and safety throughout the continual learning process by reducing forgetting to near-negligible levels. Our adaptive SVD framework effectively balances model plasticity and knowledge retention, providing a practical, theoretically grounded, and computationally scalable solution for continual learning scenarios in large language models.
Robust Open-Set Spoken Language Identification and the CU MultiLang Dataset
Aug 29, 2023Most state-of-the-art spoken language identification models are closed-set; in other words, they can only output a language label from the set of classes they were trained on. Open-set spoken language identification systems, however, gain the ability to detect when an input exhibits none of the original languages. In this paper, we implement a novel approach to open-set spoken language identification that uses MFCC and pitch features, a TDNN model to extract meaningful feature embeddings, confidence thresholding on softmax outputs, and LDA and pLDA for learning to classify new unknown languages. We present a spoken language identification system that achieves 91.76% accuracy on trained languages and has the capability to adapt to unknown languages on the fly. To that end, we also built the CU MultiLang Dataset, a large and diverse multilingual speech corpus which was used to train and evaluate our system.
* 6pages, 1 table, 6 figures
Modernizing Open-Set Speech Language Identification
May 20, 2022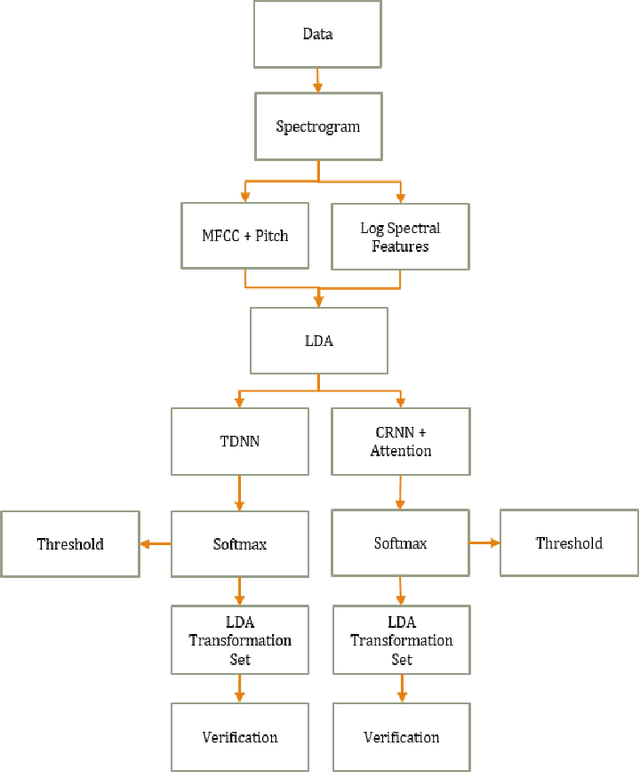
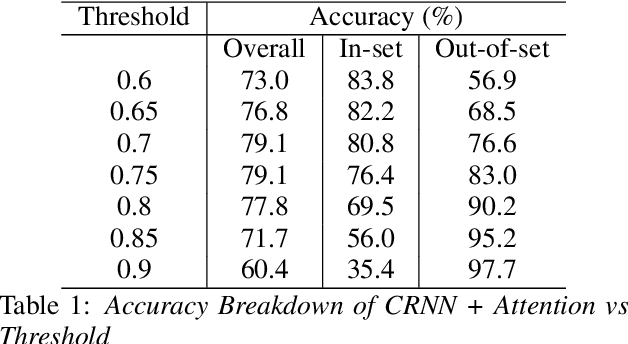
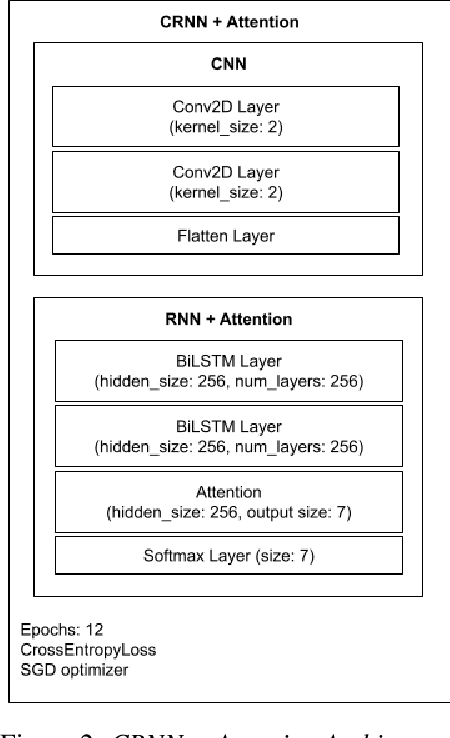

While most modern speech Language Identification methods are closed-set, we want to see if they can be modified and adapted for the open-set problem. When switching to the open-set problem, the solution gains the ability to reject an audio input when it fails to match any of our known language options. We tackle the open-set task by adapting two modern-day state-of-the-art approaches to closed-set language identification: the first using a CRNN with attention and the second using a TDNN. In addition to enhancing our input feature embeddings using MFCCs, log spectral features, and pitch, we will be attempting two approaches to out-of-set language detection: one using thresholds, and the other essentially performing a verification task. We will compare both the performance of the TDNN and the CRNN, as well as our detection approaches.