 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSculpting Subspaces: Constrained Full Fine-Tuning in LLMs for Continual Learning
Apr 09, 2025Continual learning in large language models (LLMs) is prone to catastrophic forgetting, where adapting to new tasks significantly degrades performance on previously learned ones. Existing methods typically rely on low-rank, parameter-efficient updates that limit the model's expressivity and introduce additional parameters per task, leading to scalability issues. To address these limitations, we propose a novel continual full fine-tuning approach leveraging adaptive singular value decomposition (SVD). Our method dynamically identifies task-specific low-rank parameter subspaces and constrains updates to be orthogonal to critical directions associated with prior tasks, thus effectively minimizing interference without additional parameter overhead or storing previous task gradients. We evaluate our approach extensively on standard continual learning benchmarks using both encoder-decoder (T5-Large) and decoder-only (LLaMA-2 7B) models, spanning diverse tasks including classification, generation, and reasoning. Empirically, our method achieves state-of-the-art results, up to 7% higher average accuracy than recent baselines like O-LoRA, and notably maintains the model's general linguistic capabilities, instruction-following accuracy, and safety throughout the continual learning process by reducing forgetting to near-negligible levels. Our adaptive SVD framework effectively balances model plasticity and knowledge retention, providing a practical, theoretically grounded, and computationally scalable solution for continual learning scenarios in large language models.
Mathematical Modeling of Option Pricing with an Extended Black-Scholes Framework
Apr 04, 2025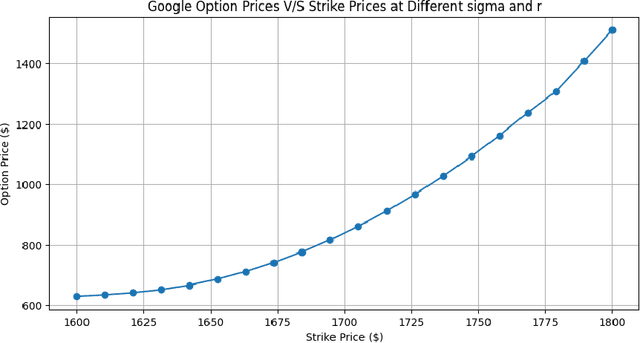
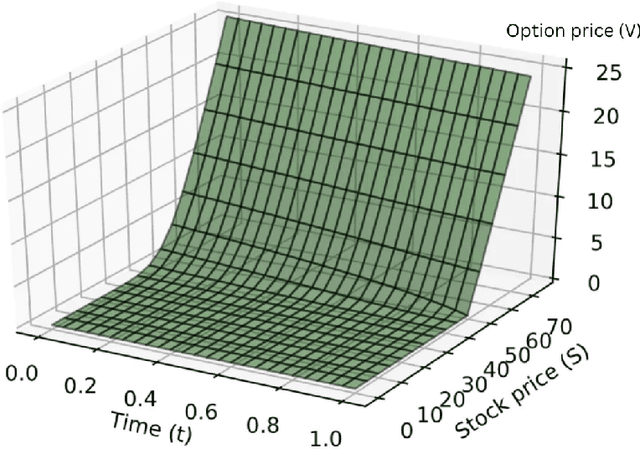
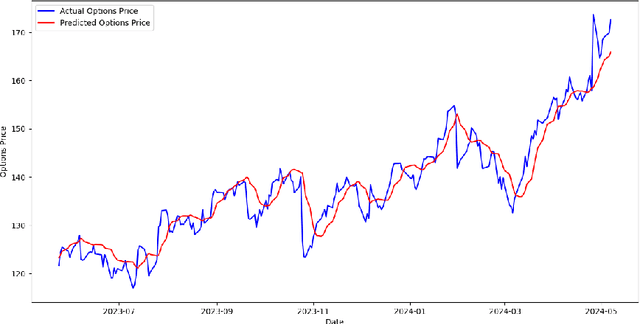
This study investigates enhancing option pricing by extending the Black-Scholes model to include stochastic volatility and interest rate variability within the Partial Differential Equation (PDE). The PDE is solved using the finite difference method. The extended Black-Scholes model and a machine learning-based LSTM model are developed and evaluated for pricing Google stock options. Both models were backtested using historical market data. While the LSTM model exhibited higher predictive accuracy, the finite difference method demonstrated superior computational efficiency. This work provides insights into model performance under varying market conditions and emphasizes the potential of hybrid approaches for robust financial modeling.
Towards Interpretable Soft Prompts
Apr 02, 2025Soft prompts have been popularized as a cheap and easy way to improve task-specific LLM performance beyond few-shot prompts. Despite their origin as an automated prompting method, however, soft prompts and other trainable prompts remain a black-box method with no immediately interpretable connections to prompting. We create a novel theoretical framework for evaluating the interpretability of trainable prompts based on two desiderata: faithfulness and scrutability. We find that existing methods do not naturally satisfy our proposed interpretability criterion. Instead, our framework inspires a new direction of trainable prompting methods that explicitly optimizes for interpretability. To this end, we formulate and test new interpretability-oriented objective functions for two state-of-the-art prompt tuners: Hard Prompts Made Easy (PEZ) and RLPrompt. Our experiments with GPT-2 demonstrate a fundamental trade-off between interpretability and the task-performance of the trainable prompt, explicating the hardness of the soft prompt interpretability problem and revealing odd behavior that arises when one optimizes for an interpretability proxy.
Unveiling the Secret Recipe: A Guide For Supervised Fine-Tuning Small LLMs
Dec 17, 2024The rise of large language models (LLMs) has created a significant disparity: industrial research labs with their computational resources, expert teams, and advanced infrastructures, can effectively fine-tune LLMs, while individual developers and small organizations face barriers due to limited resources. In this paper, we aim to bridge this gap by presenting a comprehensive study on supervised fine-tuning of LLMs using instruction-tuning datasets spanning diverse knowledge domains and skills. We focus on small-sized LLMs (3B to 7B parameters) for their cost-efficiency and accessibility. We explore various training configurations and strategies across four open-source pre-trained models. We provide detailed documentation of these configurations, revealing findings that challenge several common training practices, including hyperparameter recommendations from TULU and phased training recommended by Orca. Key insights from our work include: (i) larger batch sizes paired with lower learning rates lead to improved model performance on benchmarks such as MMLU, MTBench, and Open LLM Leaderboard; (ii) early-stage training dynamics, such as lower gradient norms and higher loss values, are strong indicators of better final model performance, enabling early termination of sub-optimal runs and significant computational savings; (iii) through a thorough exploration of hyperparameters like warmup steps and learning rate schedules, we provide guidance for practitioners and find that certain simplifications do not compromise performance; and (iv) we observed no significant difference in performance between phased and stacked training strategies, but stacked training is simpler and more sample efficient. With these findings holding robustly across datasets and models, we hope this study serves as a guide for practitioners fine-tuning small LLMs and promotes a more inclusive environment for LLM research.