 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Probabilistic Inference Approach to Inference-Time Scaling of LLMs using Particle-Based Monte Carlo Methods
Feb 04, 2025Large language models (LLMs) have achieved significant performance gains via scaling up model sizes and/or data. However, recent evidence suggests diminishing returns from such approaches, motivating scaling the computation spent at inference time. Existing inference-time scaling methods, usually with reward models, cast the task as a search problem, which tends to be vulnerable to reward hacking as a consequence of approximation errors in reward models. In this paper, we instead cast inference-time scaling as a probabilistic inference task and leverage sampling-based techniques to explore the typical set of the state distribution of a state-space model with an approximate likelihood, rather than optimize for its mode directly. We propose a novel inference-time scaling approach by adapting particle-based Monte Carlo methods to this task. Our empirical evaluation demonstrates that our methods have a 4-16x better scaling rate over our deterministic search counterparts on various challenging mathematical reasoning tasks. Using our approach, we show that Qwen2.5-Math-1.5B-Instruct can surpass GPT-4o accuracy in only 4 rollouts, while Qwen2.5-Math-7B-Instruct scales to o1 level accuracy in only 32 rollouts. Our work not only presents an effective method to inference-time scaling, but also connects the rich literature in probabilistic inference with inference-time scaling of LLMs to develop more robust algorithms in future work. Code and further information is available at https://probabilistic-inference-scaling.github.io.
Unveiling the Secret Recipe: A Guide For Supervised Fine-Tuning Small LLMs
Dec 17, 2024The rise of large language models (LLMs) has created a significant disparity: industrial research labs with their computational resources, expert teams, and advanced infrastructures, can effectively fine-tune LLMs, while individual developers and small organizations face barriers due to limited resources. In this paper, we aim to bridge this gap by presenting a comprehensive study on supervised fine-tuning of LLMs using instruction-tuning datasets spanning diverse knowledge domains and skills. We focus on small-sized LLMs (3B to 7B parameters) for their cost-efficiency and accessibility. We explore various training configurations and strategies across four open-source pre-trained models. We provide detailed documentation of these configurations, revealing findings that challenge several common training practices, including hyperparameter recommendations from TULU and phased training recommended by Orca. Key insights from our work include: (i) larger batch sizes paired with lower learning rates lead to improved model performance on benchmarks such as MMLU, MTBench, and Open LLM Leaderboard; (ii) early-stage training dynamics, such as lower gradient norms and higher loss values, are strong indicators of better final model performance, enabling early termination of sub-optimal runs and significant computational savings; (iii) through a thorough exploration of hyperparameters like warmup steps and learning rate schedules, we provide guidance for practitioners and find that certain simplifications do not compromise performance; and (iv) we observed no significant difference in performance between phased and stacked training strategies, but stacked training is simpler and more sample efficient. With these findings holding robustly across datasets and models, we hope this study serves as a guide for practitioners fine-tuning small LLMs and promotes a more inclusive environment for LLM research.
Fantastic LLMs for Preference Data Annotation and How to (not) Find Them
Nov 04, 2024Preference tuning of large language models (LLMs) relies on high-quality human preference data, which is often expensive and time-consuming to gather. While existing methods can use trained reward models or proprietary model as judges for preference annotation, they have notable drawbacks: training reward models remain dependent on initial human data, and using proprietary model imposes license restrictions that inhibits commercial usage. In this paper, we introduce customized density ratio (CDR) that leverages open-source LLMs for data annotation, offering an accessible and effective solution. Our approach uses the log-density ratio between a well-aligned LLM and a less aligned LLM as a reward signal. We explores 221 different LLMs pairs and empirically demonstrate that increasing the performance gap between paired LLMs correlates with better reward generalization. Furthermore, we show that tailoring the density ratio reward function with specific criteria and preference exemplars enhances performance across domains and within target areas. In our experiment using density ratio from a pair of Mistral-7B models, CDR achieves a RewardBench score of 82.6, outperforming the best in-class trained reward functions and demonstrating competitive performance against SoTA models in Safety (91.0) and Reasoning (88.0) domains. We use CDR to annotate an on-policy preference dataset with which we preference tune Llama-3-8B-Instruct with SimPO. The final model achieves a 37.4% (+15.1%) win rate on ArenaHard and a 40.7% (+17.8%) win rate on Length-Controlled AlpacaEval 2.0, along with a score of 8.0 on MT-Bench.
LAB: Large-Scale Alignment for ChatBots
Mar 06, 2024



This work introduces LAB (Large-scale Alignment for chatBots), a novel methodology designed to overcome the scalability challenges in the instruction-tuning phase of large language model (LLM) training. Leveraging a taxonomy-guided synthetic data generation process and a multi-phase tuning framework, LAB significantly reduces reliance on expensive human annotations and proprietary models like GPT-4. We demonstrate that LAB-trained models can achieve competitive performance across several benchmarks compared to models trained with traditional human-annotated or GPT-4 generated synthetic data. Thus offering a scalable, cost-effective solution for enhancing LLM capabilities and instruction-following behaviors without the drawbacks of catastrophic forgetting, marking a step forward in the efficient training of LLMs for a wide range of applications.
Post-processing Private Synthetic Data for Improving Utility on Selected Measures
May 24, 2023



Existing private synthetic data generation algorithms are agnostic to downstream tasks. However, end users may have specific requirements that the synthetic data must satisfy. Failure to meet these requirements could significantly reduce the utility of the data for downstream use. We introduce a post-processing technique that improves the utility of the synthetic data with respect to measures selected by the end user, while preserving strong privacy guarantees and dataset quality. Our technique involves resampling from the synthetic data to filter out samples that do not meet the selected utility measures, using an efficient stochastic first-order algorithm to find optimal resampling weights. Through comprehensive numerical experiments, we demonstrate that our approach consistently improves the utility of synthetic data across multiple benchmark datasets and state-of-the-art synthetic data generation algorithms.
Constructive Assimilation: Boosting Contrastive Learning Performance through View Generation Strategies
Apr 08, 2023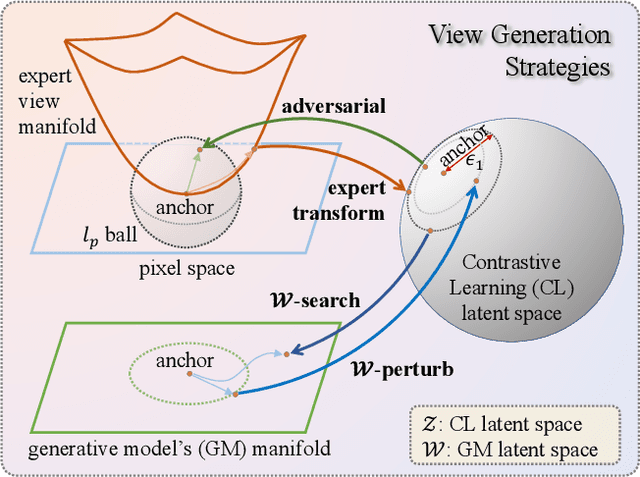
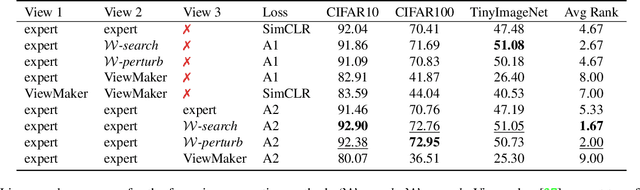
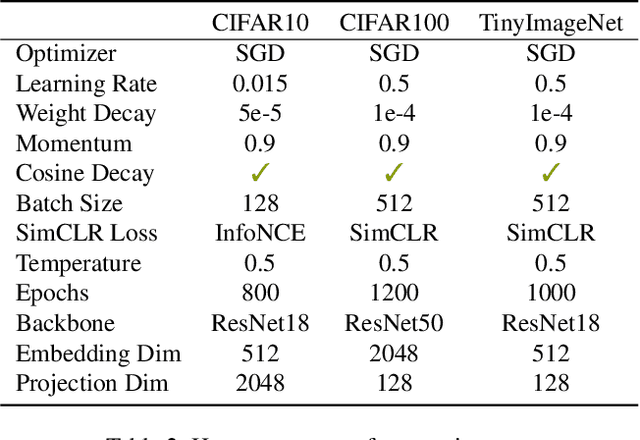
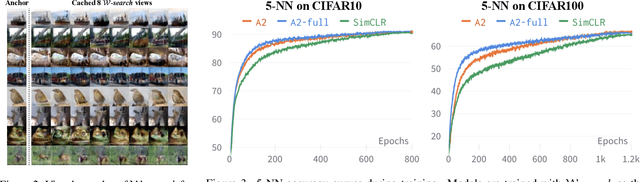
Transformations based on domain expertise (expert transformations), such as random-resized-crop and color-jitter, have proven critical to the success of contrastive learning techniques such as SimCLR. Recently, several attempts have been made to replace such domain-specific, human-designed transformations with generated views that are learned. However for imagery data, so far none of these view-generation methods has been able to outperform expert transformations. In this work, we tackle a different question: instead of replacing expert transformations with generated views, can we constructively assimilate generated views with expert transformations? We answer this question in the affirmative and propose a view generation method and a simple, effective assimilation method that together improve the state-of-the-art by up to ~3.6% on three different datasets. Importantly, we conduct a detailed empirical study that systematically analyzes a range of view generation and assimilation methods and provides a holistic picture of the efficacy of learned views in contrastive representation learning.
Multi-Symmetry Ensembles: Improving Diversity and Generalization via Opposing Symmetries
Mar 04, 2023Deep ensembles (DE) have been successful in improving model performance by learning diverse members via the stochasticity of random initialization. While recent works have attempted to promote further diversity in DE via hyperparameters or regularizing loss functions, these methods primarily still rely on a stochastic approach to explore the hypothesis space. In this work, we present Multi-Symmetry Ensembles (MSE), a framework for constructing diverse ensembles by capturing the multiplicity of hypotheses along symmetry axes, which explore the hypothesis space beyond stochastic perturbations of model weights and hyperparameters. We leverage recent advances in contrastive representation learning to create models that separately capture opposing hypotheses of invariant and equivariant symmetries and present a simple ensembling approach to efficiently combine appropriate hypotheses for a given task. We show that MSE effectively captures the multiplicity of conflicting hypotheses that is often required in large, diverse datasets like ImageNet. As a result of their inherent diversity, MSE improves classification performance, uncertainty quantification, and generalization across a series of transfer tasks.
Grafting Vision Transformers
Oct 28, 2022



Vision Transformers (ViTs) have recently become the state-of-the-art across many computer vision tasks. In contrast to convolutional networks (CNNs), ViTs enable global information sharing even within shallow layers of a network, i.e., among high-resolution features. However, this perk was later overlooked with the success of pyramid architectures such as Swin Transformer, which show better performance-complexity trade-offs. In this paper, we present a simple and efficient add-on component (termed GrafT) that considers global dependencies and multi-scale information throughout the network, in both high- and low-resolution features alike. GrafT can be easily adopted in both homogeneous and pyramid Transformers while showing consistent gains. It has the flexibility of branching-out at arbitrary depths, widening a network with multiple scales. This grafting operation enables us to share most of the parameters and computations of the backbone, adding only minimal complexity, but with a higher yield. In fact, the process of progressively compounding multi-scale receptive fields in GrafT enables communications between local regions. We show the benefits of the proposed method on multiple benchmarks, including image classification (ImageNet-1K), semantic segmentation (ADE20K), object detection and instance segmentation (COCO2017). Our code and models will be made available.
On the Importance of Calibration in Semi-supervised Learning
Oct 10, 2022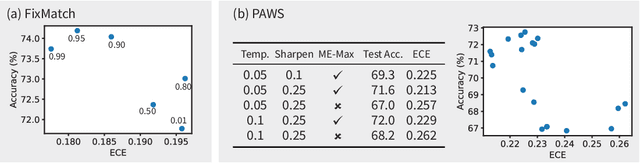
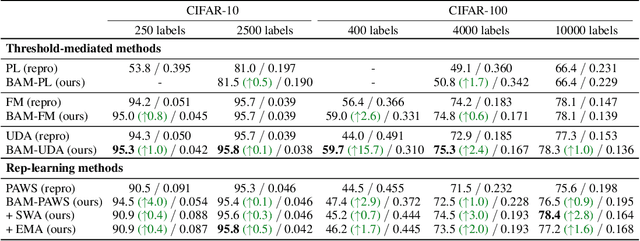
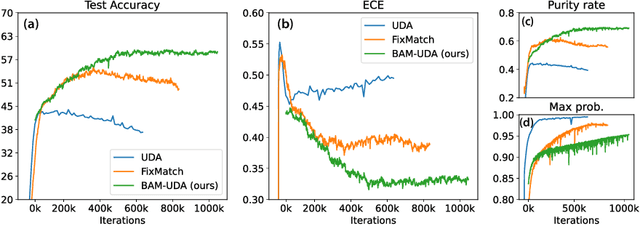
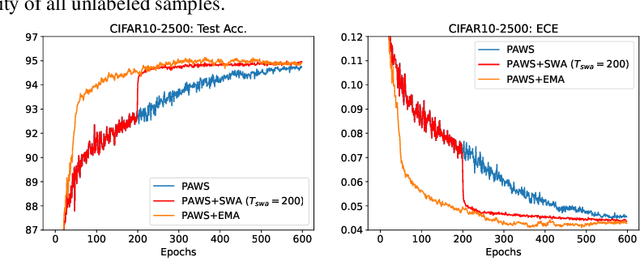
State-of-the-art (SOTA) semi-supervised learning (SSL) methods have been highly successful in leveraging a mix of labeled and unlabeled data by combining techniques of consistency regularization and pseudo-labeling. During pseudo-labeling, the model's predictions on unlabeled data are used for training and thus, model calibration is important in mitigating confirmation bias. Yet, many SOTA methods are optimized for model performance, with little focus directed to improve model calibration. In this work, we empirically demonstrate that model calibration is strongly correlated with model performance and propose to improve calibration via approximate Bayesian techniques. We introduce a family of new SSL models that optimizes for calibration and demonstrate their effectiveness across standard vision benchmarks of CIFAR-10, CIFAR-100 and ImageNet, giving up to 15.9% improvement in test accuracy. Furthermore, we also demonstrate their effectiveness in additional realistic and challenging problems, such as class-imbalanced datasets and in photonics science.