 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive learning for photonics
Jan 22, 2026Active learning for photonic crystals explores the integration of analytic approximate Bayesian last layer neural networks (LL-BNNs) with uncertainty-driven sample selection to accelerate photonic band gap prediction. We employ an analytic LL-BNN formulation, corresponding to the infinite Monte Carlo sample limit, to obtain uncertainty estimates that are strongly correlated with the true predictive error on unlabeled candidate structures. These uncertainty scores drive an active learning strategy that prioritizes the most informative simulations during training. Applied to the task of predicting band gap sizes in two-dimensional, two-tone photonic crystals, our approach achieves up to a 2.6x reduction in required training data compared to a random sampling baseline while maintaining predictive accuracy. The efficiency gains arise from concentrating computational resources on high uncertainty regions of the design space rather than sampling uniformly. Given the substantial cost of full band structure simulations, especially in three dimensions, this data efficiency enables rapid and scalable surrogate modeling. Our results suggest that analytic LL-BNN based active learning can substantially accelerate topological optimization and inverse design workflows for photonic crystals, and more broadly, offers a general framework for data efficient regression across scientific machine learning domains.
OccamLLM: Fast and Exact Language Model Arithmetic in a Single Step
Jun 04, 2024



Despite significant advancements in text generation and reasoning, Large Language Models (LLMs) still face challenges in accurately performing complex arithmetic operations. To achieve accurate calculations, language model systems often enable LLMs to generate code for arithmetic operations. However, this approach compromises speed and security and, if finetuning is involved, risks the language model losing prior capabilities. We propose a framework that enables exact arithmetic in \textit{a single autoregressive step}, providing faster, more secure, and more interpretable LLM systems with arithmetic capabilities. We use the hidden states of an LLM to control a symbolic architecture which performs arithmetic. Our implementation using Llama 3 8B Instruct with OccamNet as a symbolic model (OccamLlama) achieves 100\% accuracy on single arithmetic operations ($+,-,\times,\div,\sin{},\cos{},\log{},\exp{},\sqrt{}$), outperforming GPT 4o and on par with GPT 4o using a code interpreter. OccamLlama also outperforms both Llama 3 8B Instruct and GPT 3.5 Turbo on multistep reasoning problems involving challenging arithmetic, thus enabling small LLMs to match the arithmetic performance of even much larger models. We will make our code public shortly.
QuanTA: Efficient High-Rank Fine-Tuning of LLMs with Quantum-Informed Tensor Adaptation
May 31, 2024



We propose Quantum-informed Tensor Adaptation (QuanTA), a novel, easy-to-implement, fine-tuning method with no inference overhead for large-scale pre-trained language models. By leveraging quantum-inspired methods derived from quantum circuit structures, QuanTA enables efficient high-rank fine-tuning, surpassing the limitations of Low-Rank Adaptation (LoRA)--low-rank approximation may fail for complicated downstream tasks. Our approach is theoretically supported by the universality theorem and the rank representation theorem to achieve efficient high-rank adaptations. Experiments demonstrate that QuanTA significantly enhances commonsense reasoning, arithmetic reasoning, and scalability compared to traditional methods. Furthermore, QuanTA shows superior performance with fewer trainable parameters compared to other approaches and can be designed to integrate with existing fine-tuning algorithms for further improvement, providing a scalable and efficient solution for fine-tuning large language models and advancing state-of-the-art in natural language processing.
Multimodal Learning for Crystalline Materials
Nov 30, 2023



Artificial intelligence (AI) has revolutionized the field of materials science by improving the prediction of properties and accelerating the discovery of novel materials. In recent years, publicly available material data repositories containing data for various material properties have grown rapidly. In this work, we introduce Multimodal Learning for Crystalline Materials (MLCM), a new method for training a foundation model for crystalline materials via multimodal alignment, where high-dimensional material properties (i.e. modalities) are connected in a shared latent space to produce highly useful material representations. We show the utility of MLCM on multiple axes: (i) MLCM achieves state-of-the-art performance for material property prediction on the challenging Materials Project database; (ii) MLCM enables a novel, highly accurate method for inverse design, allowing one to screen for stable material with desired properties; and (iii) MLCM allows the extraction of interpretable emergent features that may provide insight to material scientists. Further, we explore several novel methods for aligning an arbitrary number of modalities, improving upon prior art in multimodal learning that focuses on bimodal alignment. Our work brings innovations from the ongoing AI revolution into the domain of materials science and identifies materials as a testbed for the next generation of AI.
Constructive Assimilation: Boosting Contrastive Learning Performance through View Generation Strategies
Apr 08, 2023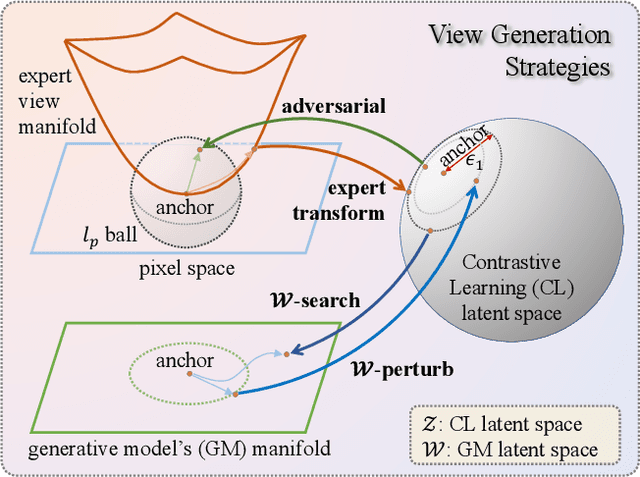
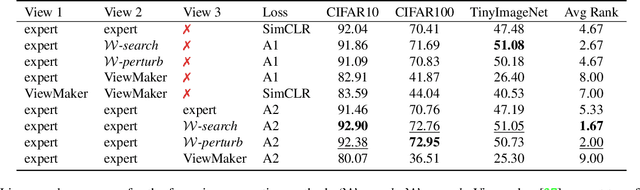
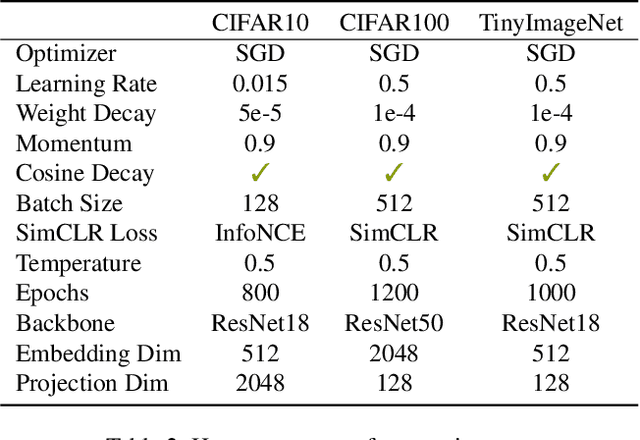
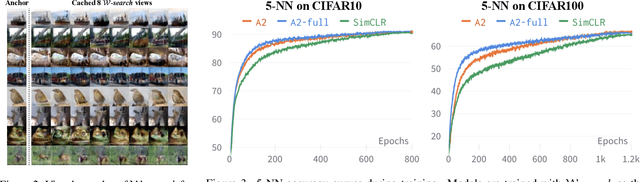
Transformations based on domain expertise (expert transformations), such as random-resized-crop and color-jitter, have proven critical to the success of contrastive learning techniques such as SimCLR. Recently, several attempts have been made to replace such domain-specific, human-designed transformations with generated views that are learned. However for imagery data, so far none of these view-generation methods has been able to outperform expert transformations. In this work, we tackle a different question: instead of replacing expert transformations with generated views, can we constructively assimilate generated views with expert transformations? We answer this question in the affirmative and propose a view generation method and a simple, effective assimilation method that together improve the state-of-the-art by up to ~3.6% on three different datasets. Importantly, we conduct a detailed empirical study that systematically analyzes a range of view generation and assimilation methods and provides a holistic picture of the efficacy of learned views in contrastive representation learning.
Multi-Symmetry Ensembles: Improving Diversity and Generalization via Opposing Symmetries
Mar 04, 2023



Deep ensembles (DE) have been successful in improving model performance by learning diverse members via the stochasticity of random initialization. While recent works have attempted to promote further diversity in DE via hyperparameters or regularizing loss functions, these methods primarily still rely on a stochastic approach to explore the hypothesis space. In this work, we present Multi-Symmetry Ensembles (MSE), a framework for constructing diverse ensembles by capturing the multiplicity of hypotheses along symmetry axes, which explore the hypothesis space beyond stochastic perturbations of model weights and hyperparameters. We leverage recent advances in contrastive representation learning to create models that separately capture opposing hypotheses of invariant and equivariant symmetries and present a simple ensembling approach to efficiently combine appropriate hypotheses for a given task. We show that MSE effectively captures the multiplicity of conflicting hypotheses that is often required in large, diverse datasets like ImageNet. As a result of their inherent diversity, MSE improves classification performance, uncertainty quantification, and generalization across a series of transfer tasks.
On the Importance of Calibration in Semi-supervised Learning
Oct 10, 2022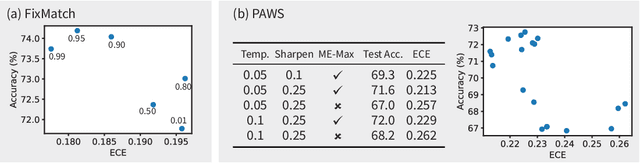
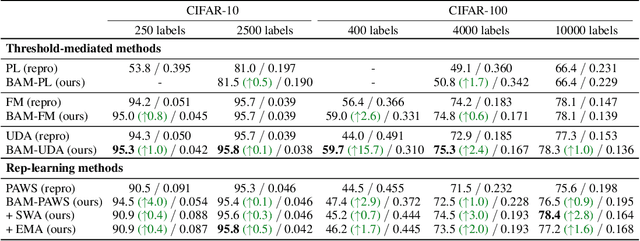
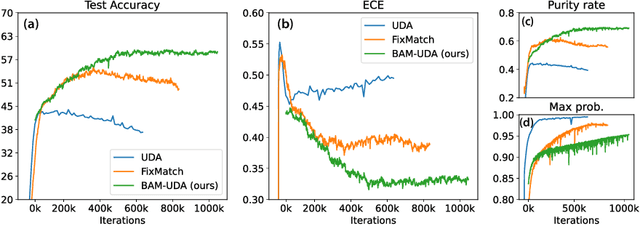
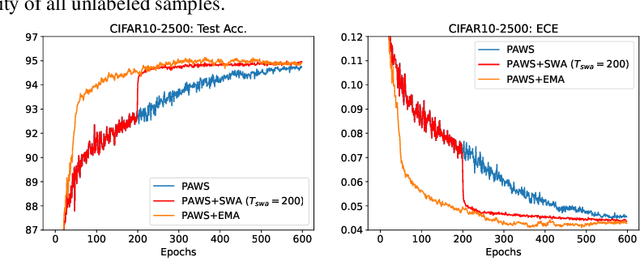
State-of-the-art (SOTA) semi-supervised learning (SSL) methods have been highly successful in leveraging a mix of labeled and unlabeled data by combining techniques of consistency regularization and pseudo-labeling. During pseudo-labeling, the model's predictions on unlabeled data are used for training and thus, model calibration is important in mitigating confirmation bias. Yet, many SOTA methods are optimized for model performance, with little focus directed to improve model calibration. In this work, we empirically demonstrate that model calibration is strongly correlated with model performance and propose to improve calibration via approximate Bayesian techniques. We introduce a family of new SSL models that optimizes for calibration and demonstrate their effectiveness across standard vision benchmarks of CIFAR-10, CIFAR-100 and ImageNet, giving up to 15.9% improvement in test accuracy. Furthermore, we also demonstrate their effectiveness in additional realistic and challenging problems, such as class-imbalanced datasets and in photonics science.
Equivariant Contrastive Learning
Oct 28, 2021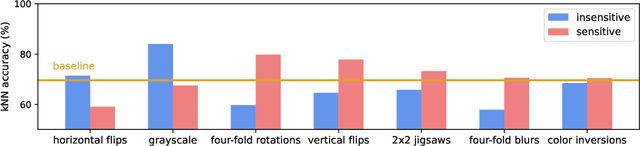
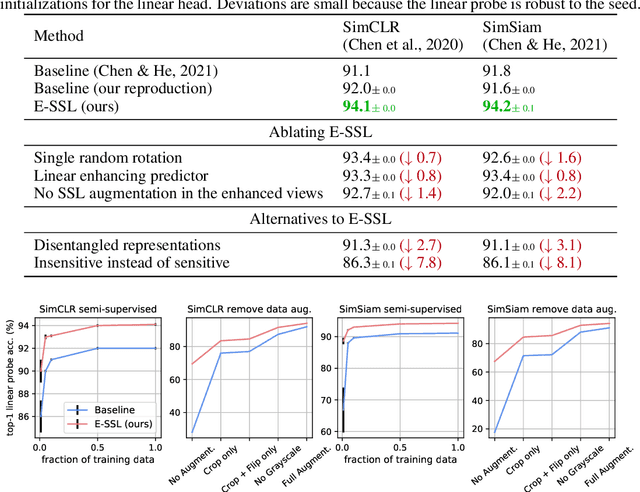


In state-of-the-art self-supervised learning (SSL) pre-training produces semantically good representations by encouraging them to be invariant under meaningful transformations prescribed from human knowledge. In fact, the property of invariance is a trivial instance of a broader class called equivariance, which can be intuitively understood as the property that representations transform according to the way the inputs transform. Here, we show that rather than using only invariance, pre-training that encourages non-trivial equivariance to some transformations, while maintaining invariance to other transformations, can be used to improve the semantic quality of representations. Specifically, we extend popular SSL methods to a more general framework which we name Equivariant Self-Supervised Learning (E-SSL). In E-SSL, a simple additional pre-training objective encourages equivariance by predicting the transformations applied to the input. We demonstrate E-SSL's effectiveness empirically on several popular computer vision benchmarks. Furthermore, we demonstrate usefulness of E-SSL for applications beyond computer vision; in particular, we show its utility on regression problems in photonics science. We will release our code.
Surrogate- and invariance-boosted contrastive learning for data-scarce applications in science
Oct 15, 2021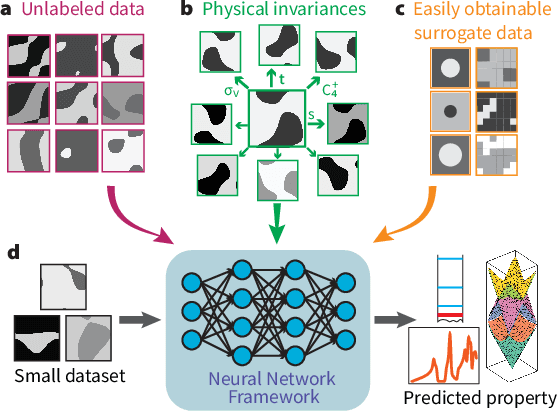
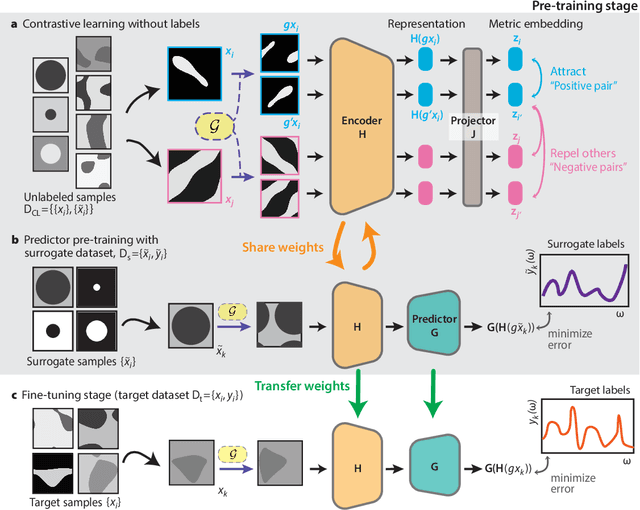
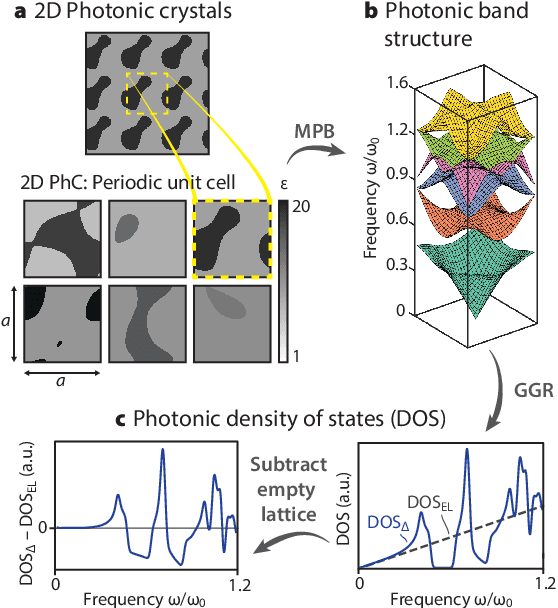
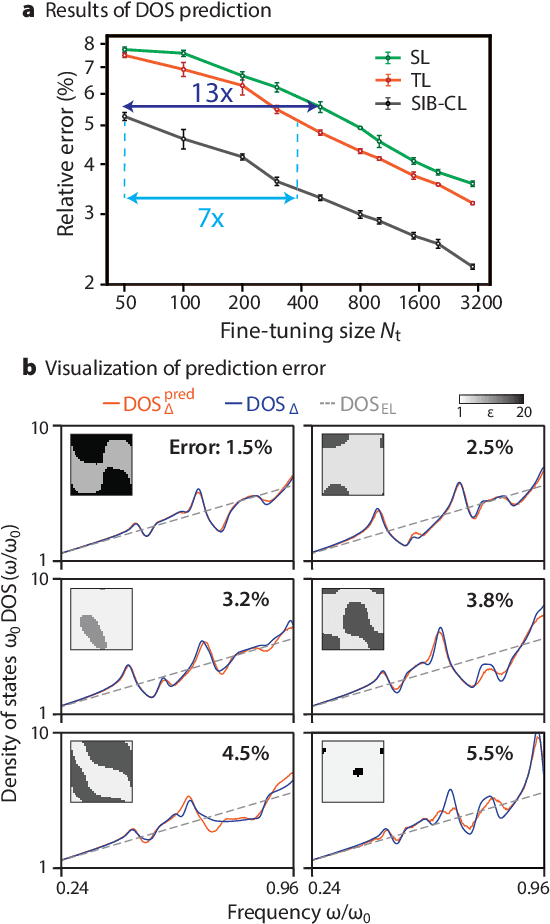
Deep learning techniques have been increasingly applied to the natural sciences, e.g., for property prediction and optimization or material discovery. A fundamental ingredient of such approaches is the vast quantity of labelled data needed to train the model; this poses severe challenges in data-scarce settings where obtaining labels requires substantial computational or labor resources. Here, we introduce surrogate- and invariance-boosted contrastive learning (SIB-CL), a deep learning framework which incorporates three ``inexpensive'' and easily obtainable auxiliary information sources to overcome data scarcity. Specifically, these are: 1)~abundant unlabeled data, 2)~prior knowledge of symmetries or invariances and 3)~surrogate data obtained at near-zero cost. We demonstrate SIB-CL's effectiveness and generality on various scientific problems, e.g., predicting the density-of-states of 2D photonic crystals and solving the 3D time-independent Schrodinger equation. SIB-CL consistently results in orders of magnitude reduction in the number of labels needed to achieve the same network accuracies.
Scalable and Flexible Deep Bayesian Optimization with Auxiliary Information for Scientific Problems
Apr 23, 2021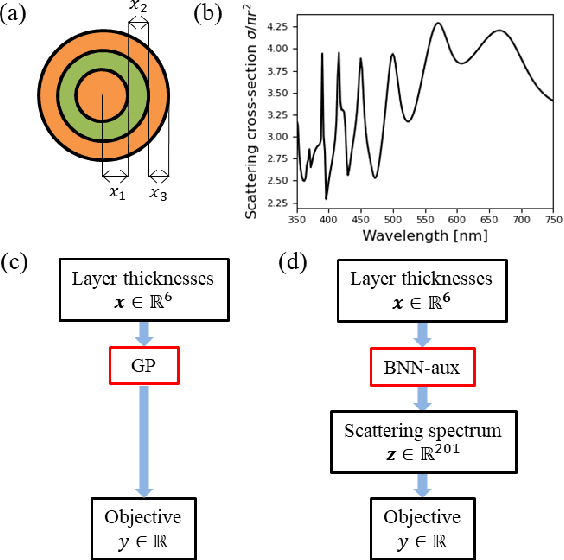
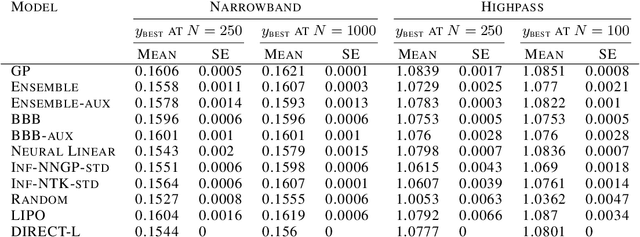

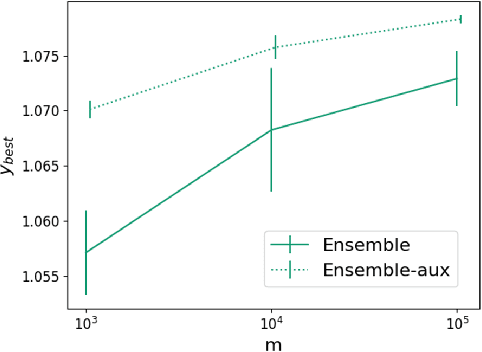
Bayesian optimization (BO) is a popular paradigm for global optimization of expensive black-box functions, but there are many domains where the function is not completely black-box. The data may have some known structure, e.g. symmetries, and the data generation process can yield useful intermediate or auxiliary information in addition to the value of the optimization objective. However, surrogate models traditionally employed in BO, such as Gaussian Processes (GPs), scale poorly with dataset size and struggle to incorporate known structure or auxiliary information. Instead, we propose performing BO on complex, structured problems by using Bayesian Neural Networks (BNNs), a class of scalable surrogate models that have the representation power and flexibility to handle structured data and exploit auxiliary information. We demonstrate BO on a number of realistic problems in physics and chemistry, including topology optimization of photonic crystal materials using convolutional neural networks, and chemical property optimization of molecules using graph neural networks. On these complex tasks, we show that BNNs often outperform GPs as surrogate models for BO in terms of both sampling efficiency and computational cost.