 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Language Models via Neural Cellular Automata
Mar 09, 2026Pre-training is crucial for large language models (LLMs), as it is when most representations and capabilities are acquired. However, natural language pre-training has problems: high-quality text is finite, it contains human biases, and it entangles knowledge with reasoning. This raises a fundamental question: is natural language the only path to intelligence? We propose using neural cellular automata (NCA) to generate synthetic, non-linguistic data for pre-pre-training LLMs--training on synthetic-then-natural language. NCA data exhibits rich spatiotemporal structure and statistics resembling natural language while being controllable and cheap to generate at scale. We find that pre-pre-training on only 164M NCA tokens improves downstream language modeling by up to 6% and accelerates convergence by up to 1.6x. Surprisingly, this even outperforms pre-pre-training on 1.6B tokens of natural language from Common Crawl with more compute. These gains also transfer to reasoning benchmarks, including GSM8K, HumanEval, and BigBench-Lite. Investigating what drives transfer, we find that attention layers are the most transferable, and that optimal NCA complexity varies by domain: code benefits from simpler dynamics, while math and web text favor more complex ones. These results enable systematic tuning of the synthetic distribution to target domains. More broadly, our work opens a path toward more efficient models with fully synthetic pre-training.
General Reasoning Requires Learning to Reason from the Get-go
Feb 26, 2025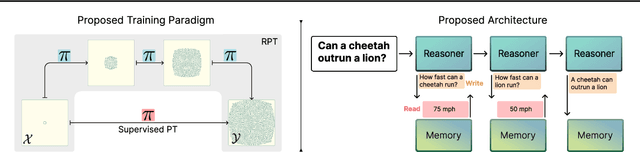
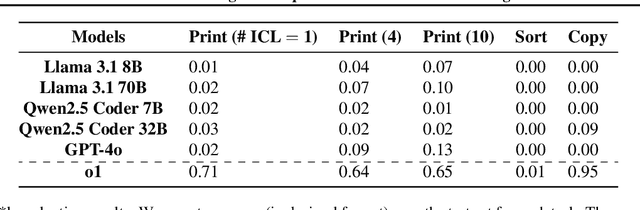
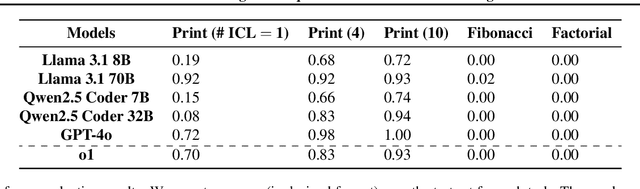
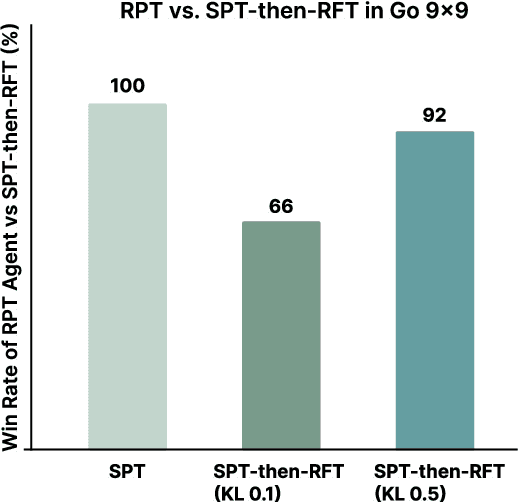
Large Language Models (LLMs) have demonstrated impressive real-world utility, exemplifying artificial useful intelligence (AUI). However, their ability to reason adaptively and robustly -- the hallmarks of artificial general intelligence (AGI) -- remains fragile. While LLMs seemingly succeed in commonsense reasoning, programming, and mathematics, they struggle to generalize algorithmic understanding across novel contexts. Our experiments with algorithmic tasks in esoteric programming languages reveal that LLM's reasoning overfits to the training data and is limited in its transferability. We hypothesize that the core issue underlying such limited transferability is the coupling of reasoning and knowledge in LLMs. To transition from AUI to AGI, we propose disentangling knowledge and reasoning through three key directions: (1) pretaining to reason using RL from scratch as an alternative to the widely used next-token prediction pretraining, (2) using a curriculum of synthetic tasks to ease the learning of a \textit{reasoning prior} for RL that can then be transferred to natural language tasks, and (3) learning more generalizable reasoning functions using a small context window to reduce exploiting spurious correlations between tokens. Such a reasoning system coupled with a trained retrieval system and a large external memory bank as a knowledge store can overcome several limitations of existing architectures at learning to reason in novel scenarios.
Unveiling the Secret Recipe: A Guide For Supervised Fine-Tuning Small LLMs
Dec 17, 2024The rise of large language models (LLMs) has created a significant disparity: industrial research labs with their computational resources, expert teams, and advanced infrastructures, can effectively fine-tune LLMs, while individual developers and small organizations face barriers due to limited resources. In this paper, we aim to bridge this gap by presenting a comprehensive study on supervised fine-tuning of LLMs using instruction-tuning datasets spanning diverse knowledge domains and skills. We focus on small-sized LLMs (3B to 7B parameters) for their cost-efficiency and accessibility. We explore various training configurations and strategies across four open-source pre-trained models. We provide detailed documentation of these configurations, revealing findings that challenge several common training practices, including hyperparameter recommendations from TULU and phased training recommended by Orca. Key insights from our work include: (i) larger batch sizes paired with lower learning rates lead to improved model performance on benchmarks such as MMLU, MTBench, and Open LLM Leaderboard; (ii) early-stage training dynamics, such as lower gradient norms and higher loss values, are strong indicators of better final model performance, enabling early termination of sub-optimal runs and significant computational savings; (iii) through a thorough exploration of hyperparameters like warmup steps and learning rate schedules, we provide guidance for practitioners and find that certain simplifications do not compromise performance; and (iv) we observed no significant difference in performance between phased and stacked training strategies, but stacked training is simpler and more sample efficient. With these findings holding robustly across datasets and models, we hope this study serves as a guide for practitioners fine-tuning small LLMs and promotes a more inclusive environment for LLM research.
Emergence of Abstractions: Concept Encoding and Decoding Mechanism for In-Context Learning in Transformers
Dec 16, 2024Humans distill complex experiences into fundamental abstractions that enable rapid learning and adaptation. Similarly, autoregressive transformers exhibit adaptive learning through in-context learning (ICL), which begs the question of how. In this paper, we propose \textbf{concept encoding-decoding mechanism} to explain ICL by studying how transformers form and use internal abstractions in their representations. On synthetic ICL tasks, we analyze the training dynamics of a small transformer and report the coupled emergence of concept encoding and decoding. As the model learns to encode different latent concepts (e.g., ``Finding the first noun in a sentence.") into distinct, separable representations, it concureently builds conditional decoding algorithms and improve its ICL performance. We validate the existence of this mechanism across pretrained models of varying scales (Gemma-2 2B/9B/27B, Llama-3.1 8B/70B). Further, through mechanistic interventions and controlled finetuning, we demonstrate that the quality of concept encoding is causally related and predictive of ICL performance. Our empirical insights shed light into better understanding the success and failure modes of large language models via their representations.
Value Augmented Sampling for Language Model Alignment and Personalization
May 10, 2024



Aligning Large Language Models (LLMs) to cater to different human preferences, learning new skills, and unlearning harmful behavior is an important problem. Search-based methods, such as Best-of-N or Monte-Carlo Tree Search, are performant, but impractical for LLM adaptation due to their high inference cost. On the other hand, using Reinforcement Learning (RL) for adaptation is computationally efficient, but performs worse due to the optimization challenges in co-training the value function and the policy. We present a new framework for reward optimization, Value Augmented Sampling (VAS), that can maximize different reward functions using data sampled from only the initial, frozen LLM. VAS solves for the optimal reward-maximizing policy without co-training the policy and the value function, making the optimization stable, outperforming established baselines, such as PPO and DPO, on standard benchmarks, and achieving comparable results to Best-of-128 with lower inference cost. Unlike existing RL methods that require changing the weights of the LLM, VAS does not require access to the weights of the pre-trained LLM. Thus, it can even adapt LLMs (e.g., ChatGPT), which are available only as APIs. In addition, our algorithm unlocks the new capability of composing several rewards and controlling the extent of each one during deployment time, paving the road ahead for the future of aligned, personalized LLMs.
Compositional Foundation Models for Hierarchical Planning
Sep 21, 2023



To make effective decisions in novel environments with long-horizon goals, it is crucial to engage in hierarchical reasoning across spatial and temporal scales. This entails planning abstract subgoal sequences, visually reasoning about the underlying plans, and executing actions in accordance with the devised plan through visual-motor control. We propose Compositional Foundation Models for Hierarchical Planning (HiP), a foundation model which leverages multiple expert foundation model trained on language, vision and action data individually jointly together to solve long-horizon tasks. We use a large language model to construct symbolic plans that are grounded in the environment through a large video diffusion model. Generated video plans are then grounded to visual-motor control, through an inverse dynamics model that infers actions from generated videos. To enable effective reasoning within this hierarchy, we enforce consistency between the models via iterative refinement. We illustrate the efficacy and adaptability of our approach in three different long-horizon table-top manipulation tasks.
Estimating the Density Ratio between Distributions with High Discrepancy using Multinomial Logistic Regression
May 01, 2023



Functions of the ratio of the densities $p/q$ are widely used in machine learning to quantify the discrepancy between the two distributions $p$ and $q$. For high-dimensional distributions, binary classification-based density ratio estimators have shown great promise. However, when densities are well separated, estimating the density ratio with a binary classifier is challenging. In this work, we show that the state-of-the-art density ratio estimators perform poorly on well-separated cases and demonstrate that this is due to distribution shifts between training and evaluation time. We present an alternative method that leverages multi-class classification for density ratio estimation and does not suffer from distribution shift issues. The method uses a set of auxiliary densities $\{m_k\}_{k=1}^K$ and trains a multi-class logistic regression to classify the samples from $p, q$, and $\{m_k\}_{k=1}^K$ into $K+2$ classes. We show that if these auxiliary densities are constructed such that they overlap with $p$ and $q$, then a multi-class logistic regression allows for estimating $\log p/q$ on the domain of any of the $K+2$ distributions and resolves the distribution shift problems of the current state-of-the-art methods. We compare our method to state-of-the-art density ratio estimators on both synthetic and real datasets and demonstrate its superior performance on the tasks of density ratio estimation, mutual information estimation, and representation learning. Code: https://www.blackswhan.com/mdre/
Constructive Assimilation: Boosting Contrastive Learning Performance through View Generation Strategies
Apr 08, 2023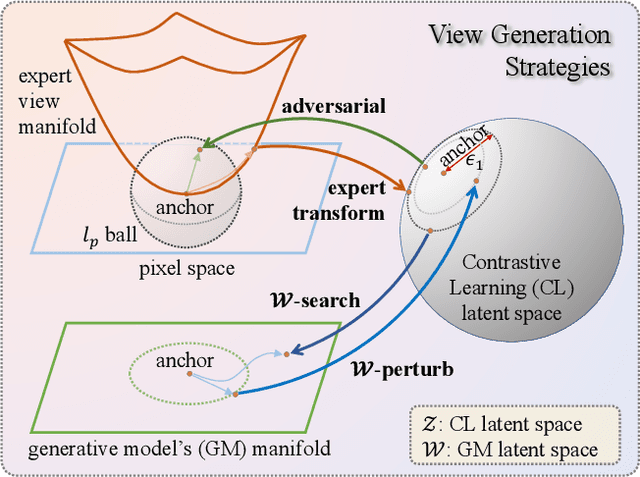
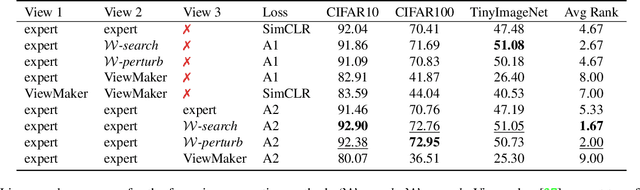
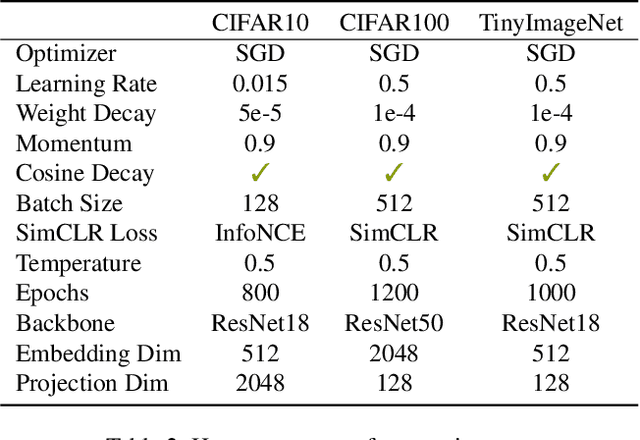
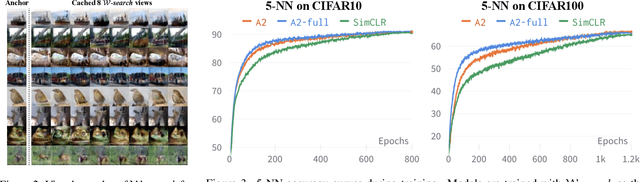
Transformations based on domain expertise (expert transformations), such as random-resized-crop and color-jitter, have proven critical to the success of contrastive learning techniques such as SimCLR. Recently, several attempts have been made to replace such domain-specific, human-designed transformations with generated views that are learned. However for imagery data, so far none of these view-generation methods has been able to outperform expert transformations. In this work, we tackle a different question: instead of replacing expert transformations with generated views, can we constructively assimilate generated views with expert transformations? We answer this question in the affirmative and propose a view generation method and a simple, effective assimilation method that together improve the state-of-the-art by up to ~3.6% on three different datasets. Importantly, we conduct a detailed empirical study that systematically analyzes a range of view generation and assimilation methods and provides a holistic picture of the efficacy of learned views in contrastive representation learning.
Multi-Symmetry Ensembles: Improving Diversity and Generalization via Opposing Symmetries
Mar 04, 2023



Deep ensembles (DE) have been successful in improving model performance by learning diverse members via the stochasticity of random initialization. While recent works have attempted to promote further diversity in DE via hyperparameters or regularizing loss functions, these methods primarily still rely on a stochastic approach to explore the hypothesis space. In this work, we present Multi-Symmetry Ensembles (MSE), a framework for constructing diverse ensembles by capturing the multiplicity of hypotheses along symmetry axes, which explore the hypothesis space beyond stochastic perturbations of model weights and hyperparameters. We leverage recent advances in contrastive representation learning to create models that separately capture opposing hypotheses of invariant and equivariant symmetries and present a simple ensembling approach to efficiently combine appropriate hypotheses for a given task. We show that MSE effectively captures the multiplicity of conflicting hypotheses that is often required in large, diverse datasets like ImageNet. As a result of their inherent diversity, MSE improves classification performance, uncertainty quantification, and generalization across a series of transfer tasks.
On the Importance of Calibration in Semi-supervised Learning
Oct 10, 2022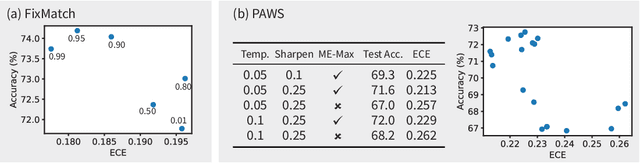
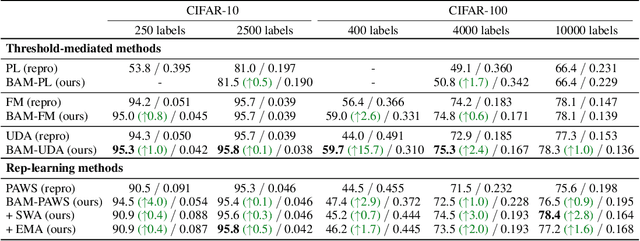
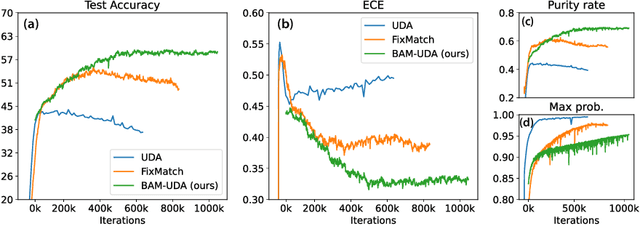
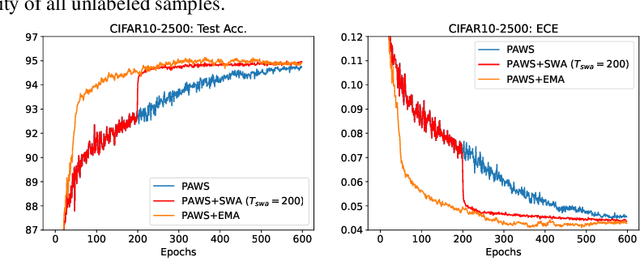
State-of-the-art (SOTA) semi-supervised learning (SSL) methods have been highly successful in leveraging a mix of labeled and unlabeled data by combining techniques of consistency regularization and pseudo-labeling. During pseudo-labeling, the model's predictions on unlabeled data are used for training and thus, model calibration is important in mitigating confirmation bias. Yet, many SOTA methods are optimized for model performance, with little focus directed to improve model calibration. In this work, we empirically demonstrate that model calibration is strongly correlated with model performance and propose to improve calibration via approximate Bayesian techniques. We introduce a family of new SSL models that optimizes for calibration and demonstrate their effectiveness across standard vision benchmarks of CIFAR-10, CIFAR-100 and ImageNet, giving up to 15.9% improvement in test accuracy. Furthermore, we also demonstrate their effectiveness in additional realistic and challenging problems, such as class-imbalanced datasets and in photonics science.