 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide-and-Denoise: A Game-Theoretic Method for Fairly Composing Diffusion Models
Jun 08, 2026The abundance of pre-trained diffusion models provides an opportunity for composition. Combining several models, however, runs the risk of one model dominating or models disagreeing with each other. Here, we propose Divide-and-Denoise, a method for coordinating multiple pre-trained diffusion models during sampling. Much like managing a specialized workforce, our method creates a fair but efficient division of labor across models. Central to our method is the notion of an allocation which defines the responsibility of each model to every region of the noisy sample. At every timestep, we then denoise by (i) updating the allocation by solving a fair division game, where we divide the sample into regions that maximize total utility under fairness constraints, and (ii) aligning the models with this allocation, where we guide each model to denoise within its assigned region. This leads to a new composite denoising process that evolves in tandem with a division process. We evaluate Divide-and-Denoise on conditional image generation. Across several quality metrics, including the GenEval benchmark, our method outperforms baselines and resolves common failures including missing objects and mismatched attributes. Experiments show that Divide-and-Denoise utilizes each model's expertise without neglecting any other model.
Compositional Foundation Models for Hierarchical Planning
Sep 21, 2023



To make effective decisions in novel environments with long-horizon goals, it is crucial to engage in hierarchical reasoning across spatial and temporal scales. This entails planning abstract subgoal sequences, visually reasoning about the underlying plans, and executing actions in accordance with the devised plan through visual-motor control. We propose Compositional Foundation Models for Hierarchical Planning (HiP), a foundation model which leverages multiple expert foundation model trained on language, vision and action data individually jointly together to solve long-horizon tasks. We use a large language model to construct symbolic plans that are grounded in the environment through a large video diffusion model. Generated video plans are then grounded to visual-motor control, through an inverse dynamics model that infers actions from generated videos. To enable effective reasoning within this hierarchy, we enforce consistency between the models via iterative refinement. We illustrate the efficacy and adaptability of our approach in three different long-horizon table-top manipulation tasks.
Is Conditional Generative Modeling all you need for Decision-Making?
Dec 07, 2022



Recent improvements in conditional generative modeling have made it possible to generate high-quality images from language descriptions alone. We investigate whether these methods can directly address the problem of sequential decision-making. We view decision-making not through the lens of reinforcement learning (RL), but rather through conditional generative modeling. To our surprise, we find that our formulation leads to policies that can outperform existing offline RL approaches across standard benchmarks. By modeling a policy as a return-conditional diffusion model, we illustrate how we may circumvent the need for dynamic programming and subsequently eliminate many of the complexities that come with traditional offline RL. We further demonstrate the advantages of modeling policies as conditional diffusion models by considering two other conditioning variables: constraints and skills. Conditioning on a single constraint or skill during training leads to behaviors at test-time that can satisfy several constraints together or demonstrate a composition of skills. Our results illustrate that conditional generative modeling is a powerful tool for decision-making.
Transfer RL via the Undo Maps Formalism
Nov 26, 2022Transferring knowledge across domains is one of the most fundamental problems in machine learning, but doing so effectively in the context of reinforcement learning remains largely an open problem. Current methods make strong assumptions on the specifics of the task, often lack principled objectives, and -- crucially -- modify individual policies, which might be sub-optimal when the domains differ due to a drift in the state space, i.e., it is intrinsic to the environment and therefore affects every agent interacting with it. To address these drawbacks, we propose TvD: transfer via distribution matching, a framework to transfer knowledge across interactive domains. We approach the problem from a data-centric perspective, characterizing the discrepancy in environments by means of (potentially complex) transformation between their state spaces, and thus posing the problem of transfer as learning to undo this transformation. To accomplish this, we introduce a novel optimization objective based on an optimal transport distance between two distributions over trajectories -- those generated by an already-learned policy in the source domain and a learnable pushforward policy in the target domain. We show this objective leads to a policy update scheme reminiscent of imitation learning, and derive an efficient algorithm to implement it. Our experiments in simple gridworlds show that this method yields successful transfer learning across a wide range of environment transformations.
SQUIRL: Robust and Efficient Learning from Video Demonstration of Long-Horizon Robotic Manipulation Tasks
Mar 10, 2020
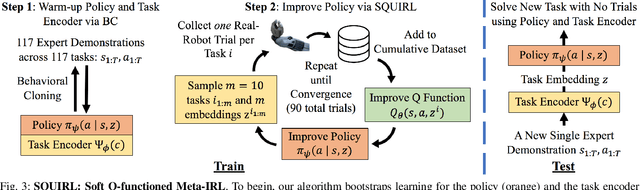


Recent advances in deep reinforcement learning (RL) have demonstrated its potential to learn complex robotic manipulation tasks. However, RL still requires the robot to collect a large amount of real-world experience. To address this problem, recent works have proposed learning from expert demonstrations (LfD), particularly via inverse reinforcement learning (IRL), given its ability to achieve robust performance with only a small number of expert demonstrations. Nevertheless, deploying IRL on real robots is still challenging due to the large number of robot experiences it requires. This paper aims to address this scalability challenge with a robust, sample-efficient, and general meta-IRL algorithm, SQUIRL, that performs a new but related long-horizon task robustly given only a single video demonstration. First, this algorithm bootstraps the learning of a task encoder and a task-conditioned policy using behavioral cloning (BC). It then collects real-robot experiences and bypasses reward learning by directly recovering a Q-function from the combined robot and expert trajectories. Next, this algorithm uses the Q-function to re-evaluate all cumulative experiences collected by the robot to improve the policy quickly. In the end, the policy performs more robustly (90%+ success) than BC on new tasks while requiring no trial-and-errors at test time. Finally, our real-robot and simulated experiments demonstrate our algorithm's generality across different state spaces, action spaces, and vision-based manipulation tasks, e.g., pick-pour-place and pick-carry-drop.