 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSculpting Subspaces: Constrained Full Fine-Tuning in LLMs for Continual Learning
Apr 09, 2025Continual learning in large language models (LLMs) is prone to catastrophic forgetting, where adapting to new tasks significantly degrades performance on previously learned ones. Existing methods typically rely on low-rank, parameter-efficient updates that limit the model's expressivity and introduce additional parameters per task, leading to scalability issues. To address these limitations, we propose a novel continual full fine-tuning approach leveraging adaptive singular value decomposition (SVD). Our method dynamically identifies task-specific low-rank parameter subspaces and constrains updates to be orthogonal to critical directions associated with prior tasks, thus effectively minimizing interference without additional parameter overhead or storing previous task gradients. We evaluate our approach extensively on standard continual learning benchmarks using both encoder-decoder (T5-Large) and decoder-only (LLaMA-2 7B) models, spanning diverse tasks including classification, generation, and reasoning. Empirically, our method achieves state-of-the-art results, up to 7% higher average accuracy than recent baselines like O-LoRA, and notably maintains the model's general linguistic capabilities, instruction-following accuracy, and safety throughout the continual learning process by reducing forgetting to near-negligible levels. Our adaptive SVD framework effectively balances model plasticity and knowledge retention, providing a practical, theoretically grounded, and computationally scalable solution for continual learning scenarios in large language models.
SQuat: Subspace-orthogonal KV Cache Quantization
Mar 31, 2025The key-value (KV) cache accelerates LLMs decoding by storing KV tensors from previously generated tokens. It reduces redundant computation at the cost of increased memory usage. To mitigate this overhead, existing approaches compress KV tensors into lower-bit representations; however, quantization errors can accumulate as more tokens are generated, potentially resulting in undesired outputs. In this paper, we introduce SQuat (Subspace-orthogonal KV cache quantization). It first constructs a subspace spanned by query tensors to capture the most critical task-related information. During key tensor quantization, it enforces that the difference between the (de)quantized and original keys remains orthogonal to this subspace, minimizing the impact of quantization errors on the attention mechanism's outputs. SQuat requires no model fine-tuning, no additional calibration dataset for offline learning, and is grounded in a theoretical framework we develop. Through numerical experiments, we show that our method reduces peak memory by 2.17 to 2.82, improves throughput by 2.45 to 3.60, and achieves more favorable benchmark scores than existing KV cache quantization algorithms.
Activation-Informed Merging of Large Language Models
Feb 04, 2025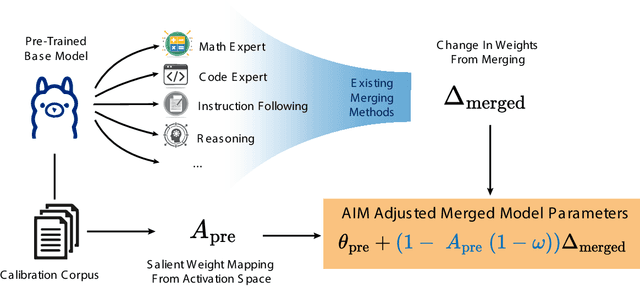
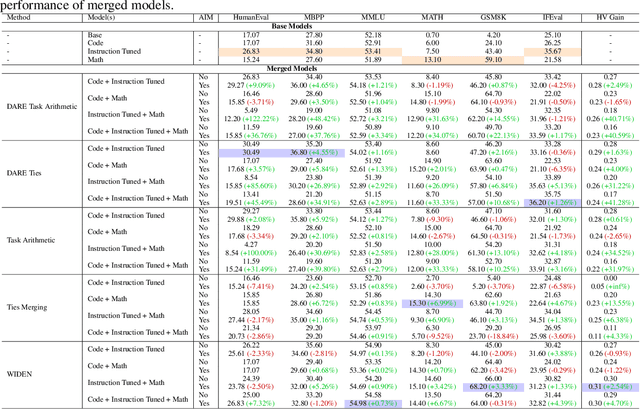
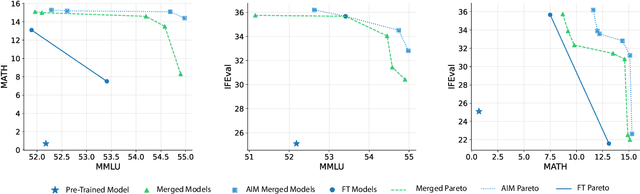
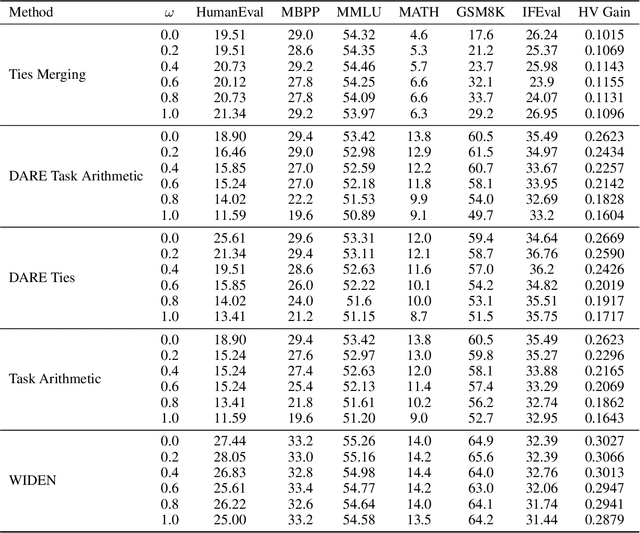
Model merging, a method that combines the parameters and embeddings of multiple fine-tuned large language models (LLMs), offers a promising approach to enhance model performance across various tasks while maintaining computational efficiency. This paper introduces Activation-Informed Merging (AIM), a technique that integrates the information from the activation space of LLMs into the merging process to improve performance and robustness. AIM is designed as a flexible, complementary solution that is applicable to any existing merging method. It aims to preserve critical weights from the base model, drawing on principles from continual learning~(CL) and model compression. Utilizing a task-agnostic calibration set, AIM selectively prioritizes essential weights during merging. We empirically demonstrate that AIM significantly enhances the performance of merged models across multiple benchmarks. Our findings suggest that considering the activation-space information can provide substantial advancements in the model merging strategies for LLMs with up to 40\% increase in benchmark performance.
A Probabilistic Inference Approach to Inference-Time Scaling of LLMs using Particle-Based Monte Carlo Methods
Feb 04, 2025Large language models (LLMs) have achieved significant performance gains via scaling up model sizes and/or data. However, recent evidence suggests diminishing returns from such approaches, motivating scaling the computation spent at inference time. Existing inference-time scaling methods, usually with reward models, cast the task as a search problem, which tends to be vulnerable to reward hacking as a consequence of approximation errors in reward models. In this paper, we instead cast inference-time scaling as a probabilistic inference task and leverage sampling-based techniques to explore the typical set of the state distribution of a state-space model with an approximate likelihood, rather than optimize for its mode directly. We propose a novel inference-time scaling approach by adapting particle-based Monte Carlo methods to this task. Our empirical evaluation demonstrates that our methods have a 4-16x better scaling rate over our deterministic search counterparts on various challenging mathematical reasoning tasks. Using our approach, we show that Qwen2.5-Math-1.5B-Instruct can surpass GPT-4o accuracy in only 4 rollouts, while Qwen2.5-Math-7B-Instruct scales to o1 level accuracy in only 32 rollouts. Our work not only presents an effective method to inference-time scaling, but also connects the rich literature in probabilistic inference with inference-time scaling of LLMs to develop more robust algorithms in future work. Code and further information is available at https://probabilistic-inference-scaling.github.io.
Unveiling the Secret Recipe: A Guide For Supervised Fine-Tuning Small LLMs
Dec 17, 2024The rise of large language models (LLMs) has created a significant disparity: industrial research labs with their computational resources, expert teams, and advanced infrastructures, can effectively fine-tune LLMs, while individual developers and small organizations face barriers due to limited resources. In this paper, we aim to bridge this gap by presenting a comprehensive study on supervised fine-tuning of LLMs using instruction-tuning datasets spanning diverse knowledge domains and skills. We focus on small-sized LLMs (3B to 7B parameters) for their cost-efficiency and accessibility. We explore various training configurations and strategies across four open-source pre-trained models. We provide detailed documentation of these configurations, revealing findings that challenge several common training practices, including hyperparameter recommendations from TULU and phased training recommended by Orca. Key insights from our work include: (i) larger batch sizes paired with lower learning rates lead to improved model performance on benchmarks such as MMLU, MTBench, and Open LLM Leaderboard; (ii) early-stage training dynamics, such as lower gradient norms and higher loss values, are strong indicators of better final model performance, enabling early termination of sub-optimal runs and significant computational savings; (iii) through a thorough exploration of hyperparameters like warmup steps and learning rate schedules, we provide guidance for practitioners and find that certain simplifications do not compromise performance; and (iv) we observed no significant difference in performance between phased and stacked training strategies, but stacked training is simpler and more sample efficient. With these findings holding robustly across datasets and models, we hope this study serves as a guide for practitioners fine-tuning small LLMs and promotes a more inclusive environment for LLM research.
Fantastic LLMs for Preference Data Annotation and How to (not) Find Them
Nov 04, 2024Preference tuning of large language models (LLMs) relies on high-quality human preference data, which is often expensive and time-consuming to gather. While existing methods can use trained reward models or proprietary model as judges for preference annotation, they have notable drawbacks: training reward models remain dependent on initial human data, and using proprietary model imposes license restrictions that inhibits commercial usage. In this paper, we introduce customized density ratio (CDR) that leverages open-source LLMs for data annotation, offering an accessible and effective solution. Our approach uses the log-density ratio between a well-aligned LLM and a less aligned LLM as a reward signal. We explores 221 different LLMs pairs and empirically demonstrate that increasing the performance gap between paired LLMs correlates with better reward generalization. Furthermore, we show that tailoring the density ratio reward function with specific criteria and preference exemplars enhances performance across domains and within target areas. In our experiment using density ratio from a pair of Mistral-7B models, CDR achieves a RewardBench score of 82.6, outperforming the best in-class trained reward functions and demonstrating competitive performance against SoTA models in Safety (91.0) and Reasoning (88.0) domains. We use CDR to annotate an on-policy preference dataset with which we preference tune Llama-3-8B-Instruct with SimPO. The final model achieves a 37.4% (+15.1%) win rate on ArenaHard and a 40.7% (+17.8%) win rate on Length-Controlled AlpacaEval 2.0, along with a score of 8.0 on MT-Bench.
DICE: Discrete Inversion Enabling Controllable Editing for Multinomial Diffusion and Masked Generative Models
Oct 10, 2024Discrete diffusion models have achieved success in tasks like image generation and masked language modeling but face limitations in controlled content editing. We introduce DICE (Discrete Inversion for Controllable Editing), the first approach to enable precise inversion for discrete diffusion models, including multinomial diffusion and masked generative models. By recording noise sequences and masking patterns during the reverse diffusion process, DICE enables accurate reconstruction and flexible editing of discrete data without the need for predefined masks or attention manipulation. We demonstrate the effectiveness of DICE across both image and text domains, evaluating it on models such as VQ-Diffusion, Paella, and RoBERTa. Our results show that DICE preserves high data fidelity while enhancing editing capabilities, offering new opportunities for fine-grained content manipulation in discrete spaces. For project webpage, see https://hexiaoxiao-cs.github.io/DICE/.
LInK: Learning Joint Representations of Design and Performance Spaces through Contrastive Learning for Mechanism Synthesis
May 31, 2024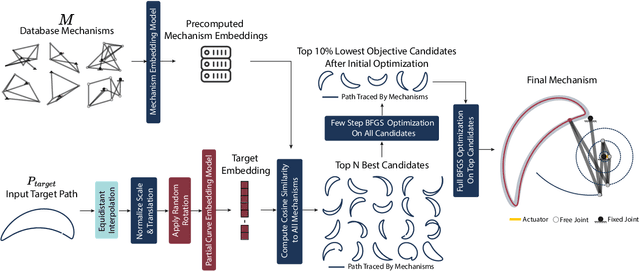

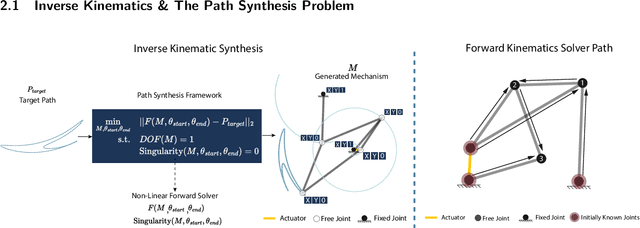
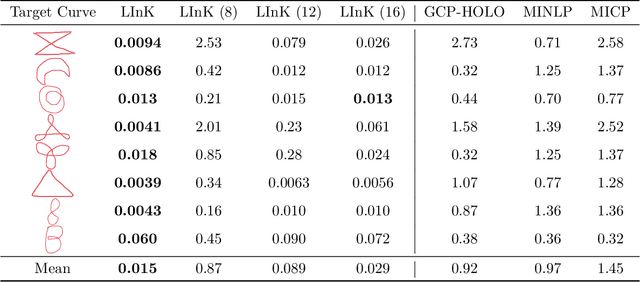
In this paper, we introduce LInK, a novel framework that integrates contrastive learning of performance and design space with optimization techniques for solving complex inverse problems in engineering design with discrete and continuous variables. We focus on the path synthesis problem for planar linkage mechanisms. By leveraging a multi-modal and transformation-invariant contrastive learning framework, LInK learns a joint representation that captures complex physics and design representations of mechanisms, enabling rapid retrieval from a vast dataset of over 10 million mechanisms. This approach improves precision through the warm start of a hierarchical unconstrained nonlinear optimization algorithm, combining the robustness of traditional optimization with the speed and adaptability of modern deep learning methods. Our results on an existing benchmark demonstrate that LInK outperforms existing methods with 28 times less error compared to a state-of-the-art approach while taking 20 times less time on an existing benchmark. Moreover, we introduce a significantly more challenging benchmark, named LINK-ABC, which involves synthesizing linkages that trace the trajectories of English capital alphabets - an inverse design benchmark task that existing methods struggle with due to large non-linearities and tiny feasible space. Our results demonstrate that LInK not only advances the field of mechanism design but also broadens the applicability of contrastive learning and optimization to other areas of engineering.
Spectrum-Aware Parameter Efficient Fine-Tuning for Diffusion Models
May 31, 2024Adapting large-scale pre-trained generative models in a parameter-efficient manner is gaining traction. Traditional methods like low rank adaptation achieve parameter efficiency by imposing constraints but may not be optimal for tasks requiring high representation capacity. We propose a novel spectrum-aware adaptation framework for generative models. Our method adjusts both singular values and their basis vectors of pretrained weights. Using the Kronecker product and efficient Stiefel optimizers, we achieve parameter-efficient adaptation of orthogonal matrices. We introduce Spectral Orthogonal Decomposition Adaptation (SODA), which balances computational efficiency and representation capacity. Extensive evaluations on text-to-image diffusion models demonstrate SODA's effectiveness, offering a spectrum-aware alternative to existing fine-tuning methods.
Adapting Differentially Private Synthetic Data to Relational Databases
May 29, 2024



Existing differentially private (DP) synthetic data generation mechanisms typically assume a single-source table. In practice, data is often distributed across multiple tables with relationships across tables. In this paper, we introduce the first-of-its-kind algorithm that can be combined with any existing DP mechanisms to generate synthetic relational databases. Our algorithm iteratively refines the relationship between individual synthetic tables to minimize their approximation errors in terms of low-order marginal distributions while maintaining referential integrity. Finally, we provide both DP and theoretical utility guarantees for our algorithm.