 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCADBench: A Multimodal Benchmark for AI-Assisted CAD Program Generation
May 11, 2026Recovering editable CAD programs from images or 3D observations is central to AI-assisted design, but progress is difficult to measure because existing evaluations are fragmented across datasets, modalities, and metrics. We introduce CADBench, a unified benchmark for multimodal CAD program generation. CADBench contains 18,000 evaluation samples spanning six benchmark families derived from DeepCAD, Fusion 360, ABC, MCB, and Objaverse; five input modalities including clean meshes, noisy meshes, single-view renders, photorealistic renders, and multi-view renders; and six metrics covering geometric fidelity, executability, and program compactness. STEP-based families are stratified by B-rep face count and all families are diversity-sampled to support controlled analysis across complexity and object variation. We benchmark eleven CAD-specialized and general-purpose vision-language systems, generating more than 1.4 million CAD programs. Under idealized inputs, specialized mesh-to-CAD models substantially outperform code-generating VLMs, which remain far from reliable CAD program reconstruction. CADBench further reveals three recurring failure modes: reconstruction quality degrades with geometric complexity, CAD-specialized models can be brittle under modality shift, and model rankings change across metrics. Together, these results position CADBench as a diagnostic testbed for measuring progress in editable 3D reconstruction and multimodal CAD understanding. The benchmark is publicly available at https://huggingface.co/datasets/DeCoDELab/CADBench.
GIFT: Bootstrapping Image-to-CAD Program Synthesis via Geometric Feedback
Mar 28, 2026Generating executable CAD programs from images requires alignment between visual geometry and symbolic program representations, a capability that current methods fail to learn reliably as design complexity increases. Existing fine-tuning approaches rely on either limited supervised datasets or expensive post-training pipelines, resulting in brittle systems that restrict progress in generative CAD design. We argue that the primary bottleneck lies not in model or algorithmic capacity, but in the scarcity of diverse training examples that align visual geometry with program syntax. This limitation is especially acute because the collection of diverse and verified engineering datasets is both expensive and difficult to scale, constraining the development of robust generative CAD models. We introduce Geometric Inference Feedback Tuning (GIFT), a data augmentation framework that leverages geometric feedback to turn test-time compute into a bootstrapped set of high-quality training samples. GIFT combines two mechanisms: Soft-Rejection Sampling (GIFT-REJECT), which retains diverse high-fidelity programs beyond exact ground-truth matches, and Failure-Driven Augmentation (GIFT-FAIL), which converts near-miss predictions into synthetic training examples that improve robustness on challenging geometries. By amortizing inference-time search into the model parameters, GIFT captures the benefits of test-time scaling while reducing inference compute by 80%. It improves mean IoU by 12% over a strong supervised baseline and remains competitive with more complex multimodal systems, without requiring additional human annotation or specialized architectures.
Engineering Regression Without Real-Data Training: Domain Adaptation for Tabular Foundation Models Using Multi-Dataset Embeddings
Mar 05, 2026Predictive modeling in engineering applications has long been dominated by bespoke models and small, siloed tabular datasets, limiting the applicability of large-scale learning approaches. Despite recent progress in tabular foundation models, the resulting synthetic training distributions used for pre-training may not reflect the statistical structure of engineering data, limiting transfer to engineering regression. We introduce TREDBench, a curated collection of 83 real-world tabular regression datasets with expert engineering/non-engineering labels, and use TabPFN 2.5's dataset-level embedding to study domain structure in a common representation space. We find that engineering datasets are partially distinguishable from non-engineering datasets, while standard procedurally generated datasets are highly distinguishable from engineering datasets, revealing a substantial synthetic-real domain gap. To bridge this gap without training on real engineering samples, we propose an embedding-guided synthetic data curation method: we generate and identify "engineering-like" synthetic datasets, and perform continued pre-training of TabPFN 2.5 using only the selected synthetic tasks. Across 35 engineering regression datasets, this synthetic-only adaptation improves predictive accuracy and data efficiency, outperforming TabPFN 2.5 on 29/35 datasets and AutoGluon on 27/35, with mean multiplicative data-efficiency gains of 1.75x and 4.44x, respectively. More broadly, our results indicate that principled synthetic data curation can convert procedural generators into domain-relevant "data engines," enabling foundation models to improve in data-sparse scientific and industrial domains where real data collection is the primary bottleneck.
TopoEdit: Fast Post-Optimization Editing of Topology Optimized Structures
Feb 25, 2026Despite topology optimization producing high-performance structures, late-stage localized revisions remain brittle: direct density-space edits (e.g., warping pixels, inserting holes, swapping infill) can sever load paths and sharply degrade compliance, while re-running optimization is slow and may drift toward a qualitatively different design. We present TopoEdit, a fast post-optimization editor that demonstrates how structured latent embeddings from a pre-trained topology foundation model (OAT) can be repurposed as an interface for physics-aware engineering edits. Given an optimized topology, TopoEdit encodes it into OAT's spatial latent, applies partial noising to preserve instance identity while increasing editability, and injects user intent through an edit-then-denoise diffusion pipeline. We instantiate three edit operators: drag-based topology warping with boundary-condition-consistent conditioning updates, shell-infill lattice replacement using a lattice-anchored reference latent with updated volume-fraction conditioning, and late-stage no-design region enforcement via masked latent overwrite followed by diffusion-based recovery. A consistency-preserving guided DDIM procedure localizes changes while allowing global structural adaptation; multiple candidates can be sampled and selected using a compliance-aware criterion, with optional short SIMP refinement for warps. Across diverse case studies and large edit sweeps, TopoEdit produces intention-aligned modifications that better preserve mechanical performance and avoid catastrophic failure modes compared to direct density-space edits, while generating edited candidates in sub-second diffusion time per sample.
TabPFN for Zero-shot Parametric Engineering Design Generation
Feb 02, 2026Deep generative models for engineering design often require substantial computational cost, large training datasets, and extensive retraining when design requirements or datasets change, limiting their applicability in real-world engineering design workflow. In this work, we propose a zero-shot generation framework for parametric engineering design based on TabPFN, enabling conditional design generation using only a limited number of reference samples and without any task-specific model training or fine-tuning. The proposed method generates design parameters sequentially conditioned on target performance indicators, providing a flexible alternative to conventional generative models. The effectiveness of the proposed approach is evaluated on three engineering design datasets, i.e., ship hull design, BlendedNet aircraft, and UIUC airfoil. Experimental results demonstrate that the proposed method achieves competitive diversity across highly structured parametric design spaces, remains robust to variations in sampling, resolution and parameter dimensionality of geometry generation, and achieves a low performance error (e.g., less than 2% in generated ship hull designs' performance). Compared with diffusion-based generative models, the proposed framework significantly reduces computational overhead and data requirements while preserving reliable generation performance. These results highlight the potential of zero-shot, data-efficient generation as a practical and efficient tool for engineering design, enabling rapid deployment, flexible adaptation to new design settings, and ease of integration into real-world engineering workflows.
FIRE: Multi-fidelity Regression with Distribution-conditioned In-context Learning using Tabular Foundation Models
Jan 29, 2026Multi-fidelity (MF) regression often operates in regimes of extreme data imbalance, where the commonly-used Gaussian-process (GP) surrogates struggle with cubic scaling costs and overfit to sparse high-fidelity observations, limiting efficiency and generalization in real-world applications. We introduce FIRE, a training-free MF framework that couples tabular foundation models (TFMs) to perform zero-shot in-context Bayesian inference via a high-fidelity correction model conditioned on the low-fidelity model's posterior predictive distributions. This cross-fidelity information transfer via distributional summaries captures heteroscedastic errors, enabling robust residual learning without model retraining. Across 31 benchmark problems spanning synthetic and real-world tasks (e.g., DrivAerNet, LCBench), FIRE delivers a stronger performance-time trade-off than seven state-of-the-art GP-based or deep learning MF regression methods, ranking highest in accuracy and uncertainty quantification with runtime advantages. Limitations include context window constraints and dependence on the quality of the pre-trained TFM's.
AI-Guided Human-In-the-Loop Inverse Design of High Performance Engineering Structures
Jan 15, 2026Inverse design tools such as Topology Optimization (TO) can achieve new levels of improvement for high-performance engineered structures. However, widespread use is hindered by high computational times and a black-box nature that inhibits user interaction. Human-in-the-loop TO approaches are emerging that integrate human intuition into the design generation process. However, these rely on the time-consuming bottleneck of iterative region selection for design modifications. To reduce the number of iterative trials, this contribution presents an AI co-pilot that uses machine learning to predict the user's preferred regions. The prediction model is configured as an image segmentation task with a U-Net architecture. It is trained on synthetic datasets where human preferences either identify the longest topological member or the most complex structural connection. The model successfully predicts plausible regions for modification and presents them to the user as AI recommendations. The human preference model demonstrates generalization across diverse and non-standard TO problems and exhibits emergent behavior outside the single-region selection training data. Demonstration examples show that the new human-in-the-loop TO approach that integrates the AI co-pilot can improve manufacturability or improve the linear buckling load by 39% while only increasing the total design time by 15 sec compared to conventional simplistic TO.
LAMP: Data-Efficient Linear Affine Weight-Space Models for Parameter-Controlled 3D Shape Generation and Extrapolation
Oct 26, 2025Generating high-fidelity 3D geometries that satisfy specific parameter constraints has broad applications in design and engineering. However, current methods typically rely on large training datasets and struggle with controllability and generalization beyond the training distributions. To overcome these limitations, we introduce LAMP (Linear Affine Mixing of Parametric shapes), a data-efficient framework for controllable and interpretable 3D generation. LAMP first aligns signed distance function (SDF) decoders by overfitting each exemplar from a shared initialization, then synthesizes new geometries by solving a parameter-constrained mixing problem in the aligned weight space. To ensure robustness, we further propose a safety metric that detects geometry validity via linearity mismatch. We evaluate LAMP on two 3D parametric benchmarks: DrivAerNet++ and BlendedNet. We found that LAMP enables (i) controlled interpolation within bounds with as few as 100 samples, (ii) safe extrapolation by up to 100% parameter difference beyond training ranges, (iii) physics performance-guided optimization under fixed parameters. LAMP significantly outperforms conditional autoencoder and Deep Network Interpolation (DNI) baselines in both extrapolation and data efficiency. Our results demonstrate that LAMP advances controllable, data-efficient, and safe 3D generation for design exploration, dataset generation, and performance-driven optimization.
GenCAD-3D: CAD Program Generation using Multimodal Latent Space Alignment and Synthetic Dataset Balancing
Sep 17, 2025CAD programs, structured as parametric sequences of commands that compile into precise 3D geometries, are fundamental to accurate and efficient engineering design processes. Generating these programs from nonparametric data such as point clouds and meshes remains a crucial yet challenging task, typically requiring extensive manual intervention. Current deep generative models aimed at automating CAD generation are significantly limited by imbalanced and insufficiently large datasets, particularly those lacking representation for complex CAD programs. To address this, we introduce GenCAD-3D, a multimodal generative framework utilizing contrastive learning for aligning latent embeddings between CAD and geometric encoders, combined with latent diffusion models for CAD sequence generation and retrieval. Additionally, we present SynthBal, a synthetic data augmentation strategy specifically designed to balance and expand datasets, notably enhancing representation of complex CAD geometries. Our experiments show that SynthBal significantly boosts reconstruction accuracy, reduces the generation of invalid CAD models, and markedly improves performance on high-complexity geometries, surpassing existing benchmarks. These advancements hold substantial implications for streamlining reverse engineering and enhancing automation in engineering design. We will publicly release our datasets and code, including a set of 51 3D-printed and laser-scanned parts on our project site.
BlendedNet: A Blended Wing Body Aircraft Dataset and Surrogate Model for Aerodynamic Predictions
Sep 10, 2025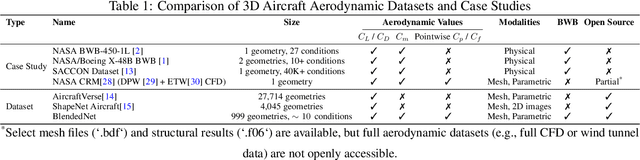
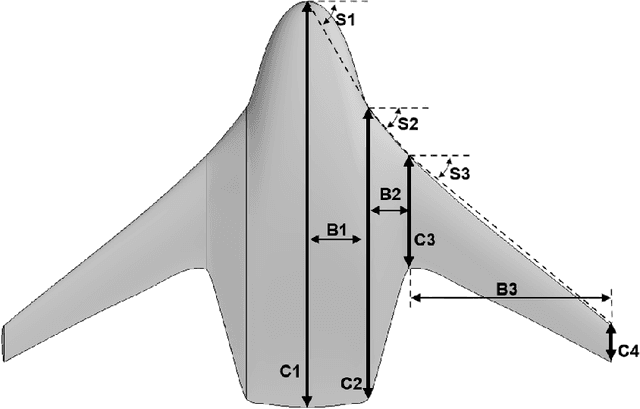
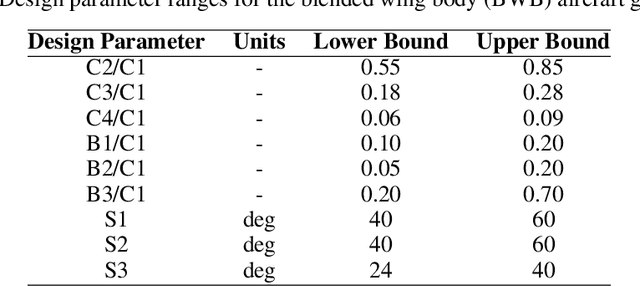
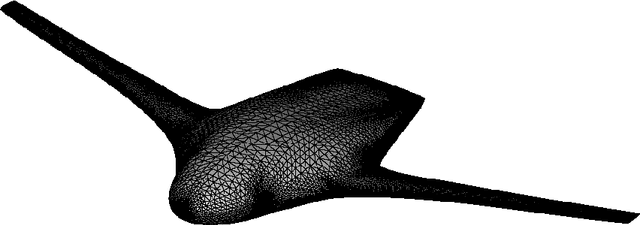
BlendedNet is a publicly available aerodynamic dataset of 999 blended wing body (BWB) geometries. Each geometry is simulated across about nine flight conditions, yielding 8830 converged RANS cases with the Spalart-Allmaras model and 9 to 14 million cells per case. The dataset is generated by sampling geometric design parameters and flight conditions, and includes detailed pointwise surface quantities needed to study lift and drag. We also introduce an end-to-end surrogate framework for pointwise aerodynamic prediction. The pipeline first uses a permutation-invariant PointNet regressor to predict geometric parameters from sampled surface point clouds, then conditions a Feature-wise Linear Modulation (FiLM) network on the predicted parameters and flight conditions to predict pointwise coefficients Cp, Cfx, and Cfz. Experiments show low errors in surface predictions across diverse BWBs. BlendedNet addresses data scarcity for unconventional configurations and enables research on data-driven surrogate modeling for aerodynamic design.