 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Judges in Design: Statistical Perspectives on Achieving Human Expert Equivalence With Vision-Language Models
Apr 01, 2025



The subjective evaluation of early stage engineering designs, such as conceptual sketches, traditionally relies on human experts. However, expert evaluations are time-consuming, expensive, and sometimes inconsistent. Recent advances in vision-language models (VLMs) offer the potential to automate design assessments, but it is crucial to ensure that these AI ``judges'' perform on par with human experts. However, no existing framework assesses expert equivalence. This paper introduces a rigorous statistical framework to determine whether an AI judge's ratings match those of human experts. We apply this framework in a case study evaluating four VLM-based judges on key design metrics (uniqueness, creativity, usefulness, and drawing quality). These AI judges employ various in-context learning (ICL) techniques, including uni- vs. multimodal prompts and inference-time reasoning. The same statistical framework is used to assess three trained novices for expert-equivalence. Results show that the top-performing AI judge, using text- and image-based ICL with reasoning, achieves expert-level agreement for uniqueness and drawing quality and outperforms or matches trained novices across all metrics. In 6/6 runs for both uniqueness and creativity, and 5/6 runs for both drawing quality and usefulness, its agreement with experts meets or exceeds that of the majority of trained novices. These findings suggest that reasoning-supported VLM models can achieve human-expert equivalence in design evaluation. This has implications for scaling design evaluation in education and practice, and provides a general statistical framework for validating AI judges in other domains requiring subjective content evaluation.
From Concept to Manufacturing: Evaluating Vision-Language Models for Engineering Design
Nov 21, 2023



Engineering Design is undergoing a transformative shift with the advent of AI, marking a new era in how we approach product, system, and service planning. Large language models have demonstrated impressive capabilities in enabling this shift. Yet, with text as their only input modality, they cannot leverage the large body of visual artifacts that engineers have used for centuries and are accustomed to. This gap is addressed with the release of multimodal vision language models, such as GPT-4V, enabling AI to impact many more types of tasks. In light of these advancements, this paper presents a comprehensive evaluation of GPT-4V, a vision language model, across a wide spectrum of engineering design tasks, categorized into four main areas: Conceptual Design, System-Level and Detailed Design, Manufacturing and Inspection, and Engineering Education Tasks. Our study assesses GPT-4V's capabilities in design tasks such as sketch similarity analysis, concept selection using Pugh Charts, material selection, engineering drawing analysis, CAD generation, topology optimization, design for additive and subtractive manufacturing, spatial reasoning challenges, and textbook problems. Through this structured evaluation, we not only explore GPT-4V's proficiency in handling complex design and manufacturing challenges but also identify its limitations in complex engineering design applications. Our research establishes a foundation for future assessments of vision language models, emphasizing their immense potential for innovating and enhancing the engineering design and manufacturing landscape. It also contributes a set of benchmark testing datasets, with more than 1000 queries, for ongoing advancements and applications in this field.
ADVISE: AI-accelerated Design of Evidence Synthesis for Global Development
May 02, 2023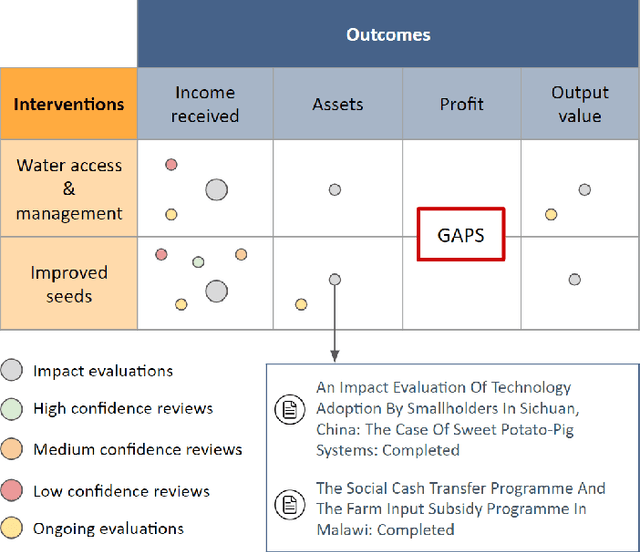



When designing evidence-based policies and programs, decision-makers must distill key information from a vast and rapidly growing literature base. Identifying relevant literature from raw search results is time and resource intensive, and is often done by manual screening. In this study, we develop an AI agent based on a bidirectional encoder representations from transformers (BERT) model and incorporate it into a human team designing an evidence synthesis product for global development. We explore the effectiveness of the human-AI hybrid team in accelerating the evidence synthesis process. To further improve team efficiency, we enhance the human-AI hybrid team through active learning (AL). Specifically, we explore different sampling strategies, including random sampling, least confidence (LC) sampling, and highest priority (HP) sampling, to study their influence on the collaborative screening process. Results show that incorporating the BERT-based AI agent into the human team can reduce the human screening effort by 68.5% compared to the case of no AI assistance and by 16.8% compared to the case of using a support vector machine (SVM)-based AI agent for identifying 80% of all relevant documents. When we apply the HP sampling strategy for AL, the human screening effort can be reduced even more: by 78.3% for identifying 80% of all relevant documents compared to no AI assistance. We apply the AL-enhanced human-AI hybrid teaming workflow in the design process of three evidence gap maps (EGMs) for USAID and find it to be highly effective. These findings demonstrate how AI can accelerate the development of evidence synthesis products and promote timely evidence-based decision making in global development in a human-AI hybrid teaming context.