 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrag-guided diffusion models for vehicle image generation
Jun 16, 2023
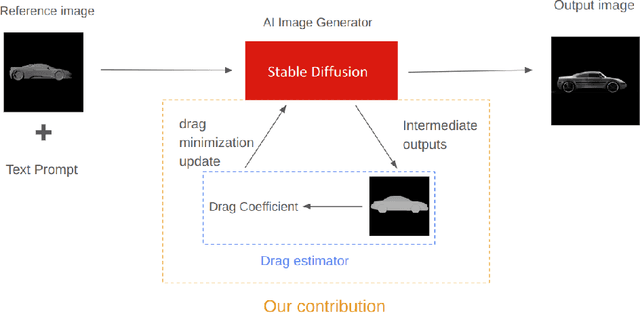

Denoising diffusion models trained at web-scale have revolutionized image generation. The application of these tools to engineering design is an intriguing possibility, but is currently limited by their inability to parse and enforce concrete engineering constraints. In this paper, we take a step towards this goal by proposing physics-based guidance, which enables optimization of a performance metric (as predicted by a surrogate model) during the generation process. As a proof-of-concept, we add drag guidance to Stable Diffusion, which allows this tool to generate images of novel vehicles while simultaneously minimizing their predicted drag coefficients.
Surrogate Modeling of Car Drag Coefficient with Depth and Normal Renderings
May 26, 2023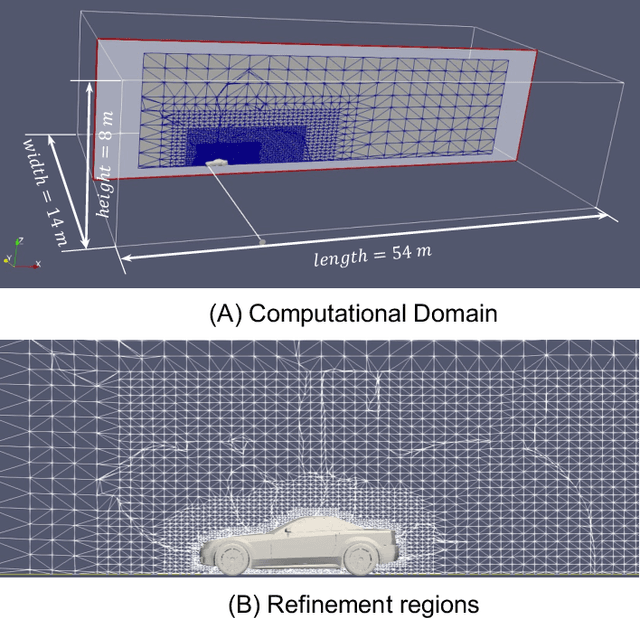
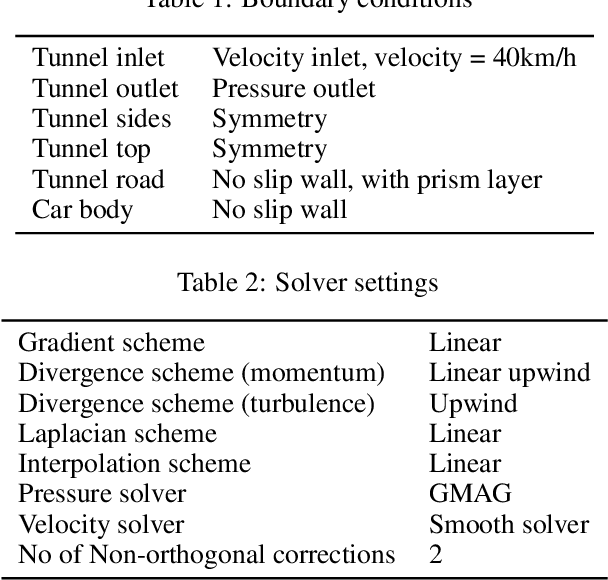
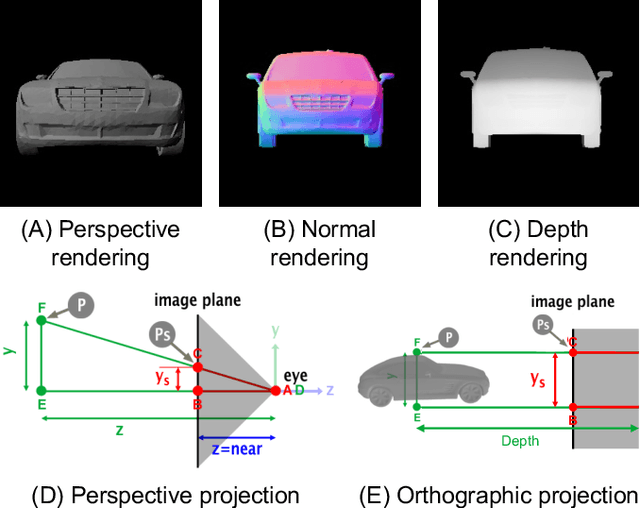
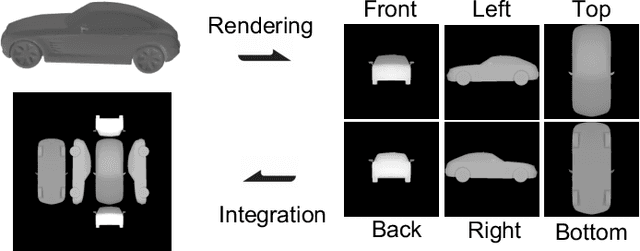
Generative AI models have made significant progress in automating the creation of 3D shapes, which has the potential to transform car design. In engineering design and optimization, evaluating engineering metrics is crucial. To make generative models performance-aware and enable them to create high-performing designs, surrogate modeling of these metrics is necessary. However, the currently used representations of three-dimensional (3D) shapes either require extensive computational resources to learn or suffer from significant information loss, which impairs their effectiveness in surrogate modeling. To address this issue, we propose a new two-dimensional (2D) representation of 3D shapes. We develop a surrogate drag model based on this representation to verify its effectiveness in predicting 3D car drag. We construct a diverse dataset of 9,070 high-quality 3D car meshes labeled by drag coefficients computed from computational fluid dynamics (CFD) simulations to train our model. Our experiments demonstrate that our model can accurately and efficiently evaluate drag coefficients with an $R^2$ value above 0.84 for various car categories. Moreover, the proposed representation method can be generalized to many other product categories beyond cars. Our model is implemented using deep neural networks, making it compatible with recent AI image generation tools (such as Stable Diffusion) and a significant step towards the automatic generation of drag-optimized car designs. We have made the dataset and code publicly available at https://decode.mit.edu/projects/dragprediction/.
Multi-modal Machine Learning for Vehicle Rating Predictions Using Image, Text, and Parametric Data
May 24, 2023



Accurate vehicle rating prediction can facilitate designing and configuring good vehicles. This prediction allows vehicle designers and manufacturers to optimize and improve their designs in a timely manner, enhance their product performance, and effectively attract consumers. However, most of the existing data-driven methods rely on data from a single mode, e.g., text, image, or parametric data, which results in a limited and incomplete exploration of the available information. These methods lack comprehensive analyses and exploration of data from multiple modes, which probably leads to inaccurate conclusions and hinders progress in this field. To overcome this limitation, we propose a multi-modal learning model for more comprehensive and accurate vehicle rating predictions. Specifically, the model simultaneously learns features from the parametric specifications, text descriptions, and images of vehicles to predict five vehicle rating scores, including the total score, critics score, performance score, safety score, and interior score. We compare the multi-modal learning model to the corresponding unimodal models and find that the multi-modal model's explanatory power is 4% - 12% higher than that of the unimodal models. On this basis, we conduct sensitivity analyses using SHAP to interpret our model and provide design and optimization directions to designers and manufacturers. Our study underscores the importance of the data-driven multi-modal learning approach for vehicle design, evaluation, and optimization. We have made the code publicly available at http://decode.mit.edu/projects/vehicleratings/.
ADVISE: AI-accelerated Design of Evidence Synthesis for Global Development
May 02, 2023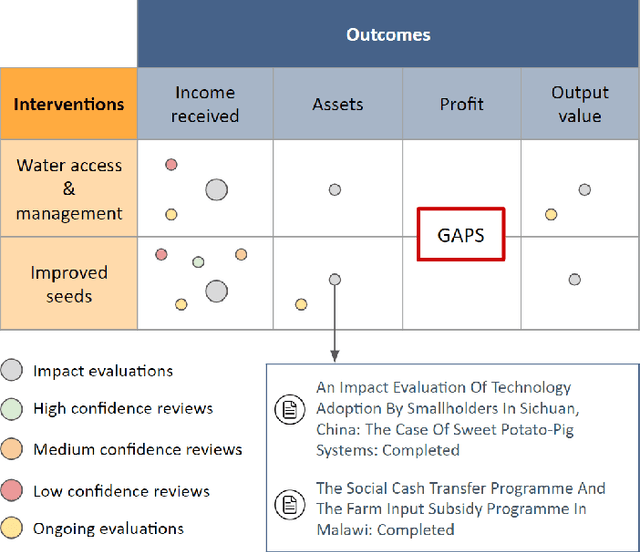



When designing evidence-based policies and programs, decision-makers must distill key information from a vast and rapidly growing literature base. Identifying relevant literature from raw search results is time and resource intensive, and is often done by manual screening. In this study, we develop an AI agent based on a bidirectional encoder representations from transformers (BERT) model and incorporate it into a human team designing an evidence synthesis product for global development. We explore the effectiveness of the human-AI hybrid team in accelerating the evidence synthesis process. To further improve team efficiency, we enhance the human-AI hybrid team through active learning (AL). Specifically, we explore different sampling strategies, including random sampling, least confidence (LC) sampling, and highest priority (HP) sampling, to study their influence on the collaborative screening process. Results show that incorporating the BERT-based AI agent into the human team can reduce the human screening effort by 68.5% compared to the case of no AI assistance and by 16.8% compared to the case of using a support vector machine (SVM)-based AI agent for identifying 80% of all relevant documents. When we apply the HP sampling strategy for AL, the human screening effort can be reduced even more: by 78.3% for identifying 80% of all relevant documents compared to no AI assistance. We apply the AL-enhanced human-AI hybrid teaming workflow in the design process of three evidence gap maps (EGMs) for USAID and find it to be highly effective. These findings demonstrate how AI can accelerate the development of evidence synthesis products and promote timely evidence-based decision making in global development in a human-AI hybrid teaming context.
Multi-modal Machine Learning in Engineering Design: A Review and Future Directions
Feb 14, 2023



Multi-modal machine learning (MMML), which involves integrating multiple modalities of data and their corresponding processing methods, has demonstrated promising results in various practical applications, such as text-to-image translation. This review paper summarizes the recent progress and challenges in using MMML for engineering design tasks. First, we introduce the different data modalities commonly used as design representations and involved in MMML, including text, 2D pixel data (e.g., images and sketches), and 3D shape data (e.g., voxels, point clouds, and meshes). We then provide an overview of the various approaches and techniques used for representing, fusing, aligning, synthesizing, and co-learning multi-modal data as five fundamental concepts of MMML. Next, we review the state-of-the-art capabilities of MMML that potentially apply to engineering design tasks, including design knowledge retrieval, design evaluation, and design synthesis. We also highlight the potential benefits and limitations of using MMML in these contexts. Finally, we discuss the challenges and future directions in using MMML for engineering design, such as the need for large labeled multi-modal design datasets, robust and scalable algorithms, integrating domain knowledge, and handling data heterogeneity and noise. Overall, this review paper provides a comprehensive overview of the current state and prospects of MMML for engineering design applications.
Patent Data for Engineering Design: A Review
Nov 15, 2021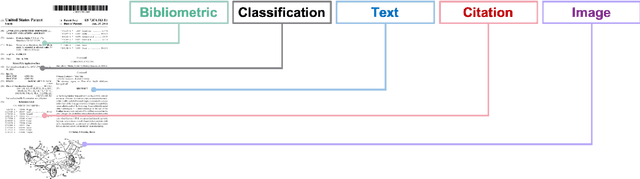

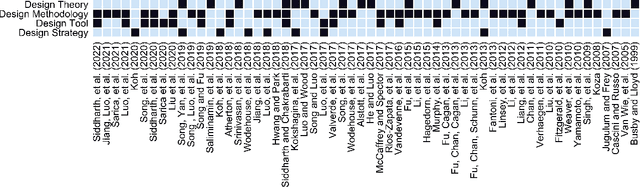
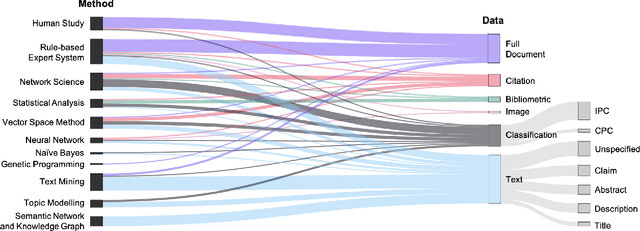
Patent data have been utilized for engineering design research for long because it contains massive amount of design information. Recent advances in artificial intelligence and data science present unprecedented opportunities to mine, analyse and make sense of patent data to develop design theory and methodology. Herein, we survey the patent-for-design literature by their contributions to design theories, methods, tools, and strategies, as well as different forms of patent data and various methods. Our review sheds light on promising future research directions for the field.