 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinGuard: Detecting Financial Regulatory Non-Compliance in LLM Interactions
May 28, 2026As large language models (LLMs) are increasingly deployed in financial services, a single non-compliant interaction can expose institutions to regulatory penalties and direct consumer harm. Existing guard models are built around general harm taxonomies and overlook violations grounded in specific financial regulations. We address this gap with a regulation-driven pipeline that operates directly on regulatory documents, inducing a financial compliance risk taxonomy and synthesizing grounded training data without any predefined violation categories. Instantiating the pipeline on Chinese financial regulations, we release \textbf{FinGuard-Bench}, to our knowledge the first benchmark for financial regulatory compliance detection, with expert-annotated labels at both the query and response levels. We further train \textbf{FinGuard}, a financial compliance detection model built on Qwen3-8B and trained on the regulation-grounded data via supervised fine-tuning and self-play reinforcement learning. On FinGuard-Bench, FinGuard substantially outperforms all baselines, including dedicated guard models and much larger general-purpose LLMs such as Qwen3.5-397B-A17B and GPT-5.1. Furthermore, FinGuard also preserves general safety capabilities and adapts to unseen institution-specific policies using policy documents alone. We will publicly release the code, prompts, and resources used in this work on GitHub.
Compass: Navigating Global Marine Lead Data Integration through Expert-Guided LLM Agent
May 28, 2026Marine lead (Pb) and its isotopes are critical tracers for ocean circulation and anthropogenic pollution, yet in-situ observations remain costly and sparse. While vast historical records exist, they lie buried within the unstructured content of academic papers, creating "data silos" inaccessible to comprehensive analysis. Manual extraction is unscalable, while general-purpose Large Language Models (LLMs) lack the necessary domain-specific knowledge, leading to hallucinations and scientifically invalid outputs. To address this, we introduce an expert-guided adaptation approach that enables LLMs to perform rigorous scientific data extraction without fine-tuning. We operationalize this approach through Compass, an LLM agent framework enhanced by a Knowledge Tree co-designed with marine scientists, which decomposes complex tasks into verifiable steps, guiding the agent's reasoning to ensure scientific validity. Deploying Compass across a corpus of over 230,000 relevant open-access papers, we successfully extract 3,751 previously unincorporated Pb records. This effort establishes the largest integrated marine Pb database to date. Beyond standard metrics, Compass demonstrates superior reliability through multi-layered validation, achieving 92% accuracy as confirmed through expert manual verification. The newly integrated data expand coverage in previously under-sampled regions such as the East China Sea and the Southern Ocean, providing an enriched data foundation for future scientific discoveries. We release an interactive visualization platform to facilitate open scientific access. Our work demonstrates that expert-guided agents can effectively bridge the gap between general-purpose LLMs and high-stakes scientific domains, enabling scalable data discovery in geosciences.
ESC-Skills: Discovering and Self-Evolving Skills for Emotional Support Conversations
May 27, 2026Existing emotional support conversation (ESC) systems mainly rely on end-to-end response generation or coarse strategy supervision, offering limited interpretability and little support for systematic skill improvement. We propose ESC-Skills, a skill-centric framework that discovers and self-evolves executable emotional support skills. We first model localized support interactions as Intervention Units (IUs), which capture state--action--outcome dynamics between seeker states, support interventions, and post-response emotional changes. Based on IUs extracted from both successful and failed ESC dialogues, we construct the ESC-Skills Bank, a repository of executable emotional support skills containing intervention guidance, applicability conditions, expected outcomes, and potential risks. To further improve robustness, we introduce a multi-profile self-evolutionary refinement framework in which an ESC agent interacts with diverse simulated seeker profiles under SAGE evaluation. The resulting interaction traces are analyzed to identify missing skills, unsafe interventions, and profile-specific failure patterns, which are then used to refine the Skills Bank through simulation-based verification. Experimental results demonstrate that ESC-Skills improves both response-level quality and dialogue-level emotional outcomes while providing more interpretable and controllable support behaviors. We will release the code, prompts, and ESC-Skills Bank at https://github.com/aliyun/qwen-dianjin.
GLeVE: Graph-Guided Lesion Grounding with Proposal Verification in 3D CT
May 21, 2026Grounding radiology report descriptions to 3D CT volumes is essential for verifiable clinical interpretation, yet remains challenging due to the semantic-spatial gap between free-text narratives and volumetric anatomy. Existing report-assisted and vision-language grounding methods typically rely on phrase-level alignment or dense pixel supervision, resulting in limited lesion-wise correspondence and suboptimal localization accuracy. We propose GLeVE, a graph-guided lesion grounding framework with anatomical prior verification and octree-based autoregressive refinement. GLeVE treats each lesion description as an atomic semantic unit and encodes organ attribution, attributes, and inter-lesion relations through relation-aware graph reasoning to produce discriminative lesion-wise queries. Anatomy-aware proposal generation with region-level verification enforces one-to-one text-lesion alignment, while hierarchical octree refinement progressively improves boundary delineation. Experiments on AbdomenAtlas 3.0 demonstrate consistent gains over classical multimodal foundation models and report-supervised baselines in both segmentation accuracy and lesion-level localization.
Mixtac: A Novel Bio-Inspired Hybrid Tactile Sensor with Synergistic Event-Frame Perception
May 18, 2026Vision based and event based tactile sensors are important in robotic manipulation research. However, they suffer from a fundamental tradeoff: vision based sensors have low sampling rates, while event based sensors are prone to drift during long term static force estimation. To solve this challenge and achieve human level tactile perception, the novel hybrid event frame tactile sensor (Mixtac) is proposed in this paper by emulating the synergistic function of biological mechanoreceptors, which achieves normal force estimation. The prototype leverages events for high frequency force tracking and frames for long term accuracy. The Frame Guided Event Recurrent Network (FGER-Net) was proposed to fuse the two data streams. Frames were used by the net to correct event drift during training and guide high frequency predictions during inference. Experiments demonstrated an MAE of 0.04 N. This paper could bridge the sampling rate gap from 0 to 500 Hz in current vision based tactile sensors and pave the way for human level robotic manipulation.
Multimodal OCR: Parse Anything from Documents
Mar 13, 2026We present Multimodal OCR (MOCR), a document parsing paradigm that jointly parses text and graphics into unified textual representations. Unlike conventional OCR systems that focus on text recognition and leave graphical regions as cropped pixels, our method, termed dots.mocr, treats visual elements such as charts, diagrams, tables, and icons as first-class parsing targets, enabling systems to parse documents while preserving semantic relationships across elements. It offers several advantages: (1) it reconstructs both text and graphics as structured outputs, enabling more faithful document reconstruction; (2) it supports end-to-end training over heterogeneous document elements, allowing models to exploit semantic relations between textual and visual components; and (3) it converts previously discarded graphics into reusable code-level supervision, unlocking multimodal supervision embedded in existing documents. To make this paradigm practical at scale, we build a comprehensive data engine from PDFs, rendered webpages, and native SVG assets, and train a compact 3B-parameter model through staged pretraining and supervised fine-tuning. We evaluate dots.mocr from two perspectives: document parsing and structured graphics parsing. On document parsing benchmarks, it ranks second only to Gemini 3 Pro on our OCR Arena Elo leaderboard, surpasses existing open-source document parsing systems, and sets a new state of the art of 83.9 on olmOCR Bench. On structured graphics parsing, dots.mocr achieves higher reconstruction quality than Gemini 3 Pro across image-to-SVG benchmarks, demonstrating strong performance on charts, UI layouts, scientific figures, and chemical diagrams. These results show a scalable path toward building large-scale image-to-code corpora for multimodal pretraining. Code and models are publicly available at https://github.com/rednote-hilab/dots.mocr.
EReCu: Pseudo-label Evolution Fusion and Refinement with Multi-Cue Learning for Unsupervised Camouflage Detection
Mar 12, 2026Unsupervised Camouflaged Object Detection (UCOD) remains a challenging task due to the high intrinsic similarity between target objects and their surroundings, as well as the reliance on noisy pseudo-labels that hinder fine-grained texture learning. While existing refinement strategies aim to alleviate label noise, they often overlook intrinsic perceptual cues, leading to boundary overflow and structural ambiguity. In contrast, learning without pseudo-label guidance yields coarse features with significant detail loss. To address these issues, we propose a unified UCOD framework that enhances both the reliability of pseudo-labels and the fidelity of features. Our approach introduces the Multi-Cue Native Perception module, which extracts intrinsic visual priors by integrating low-level texture cues with mid-level semantics, enabling precise alignment between masks and native object information. Additionally, Pseudo-Label Evolution Fusion intelligently refines labels through teacher-student interaction and utilizes depthwise separable convolution for efficient semantic denoising. It also incorporates Spectral Tensor Attention Fusion to effectively balance semantic and structural information through compact spectral aggregation across multi-layer attention maps. Finally, Local Pseudo-Label Refinement plays a pivotal role in local detail optimization by leveraging attention diversity to restore fine textures and enhance boundary fidelity. Extensive experiments on multiple UCOD datasets demonstrate that our method achieves state-of-the-art performance, characterized by superior detail perception, robust boundary alignment, and strong generalization under complex camouflage scenarios.
No Modality Left Behind: Adapting to Missing Modalities via Knowledge Distillation for Brain Tumor Segmentation
Sep 18, 2025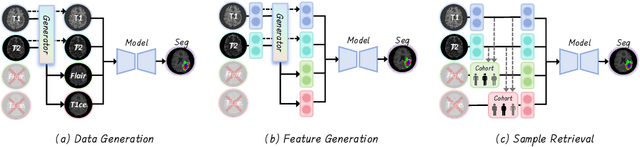
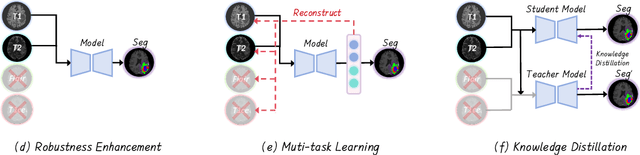
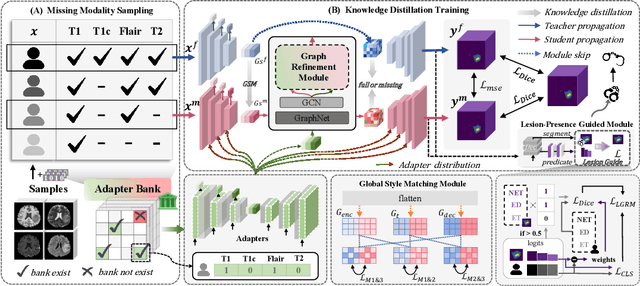
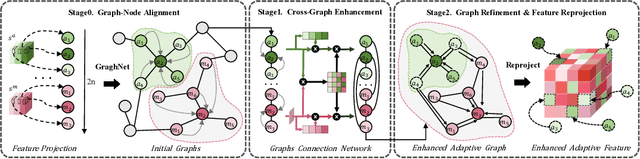
Accurate brain tumor segmentation is essential for preoperative evaluation and personalized treatment. Multi-modal MRI is widely used due to its ability to capture complementary tumor features across different sequences. However, in clinical practice, missing modalities are common, limiting the robustness and generalizability of existing deep learning methods that rely on complete inputs, especially under non-dominant modality combinations. To address this, we propose AdaMM, a multi-modal brain tumor segmentation framework tailored for missing-modality scenarios, centered on knowledge distillation and composed of three synergistic modules. The Graph-guided Adaptive Refinement Module explicitly models semantic associations between generalizable and modality-specific features, enhancing adaptability to modality absence. The Bi-Bottleneck Distillation Module transfers structural and textural knowledge from teacher to student models via global style matching and adversarial feature alignment. The Lesion-Presence-Guided Reliability Module predicts prior probabilities of lesion types through an auxiliary classification task, effectively suppressing false positives under incomplete inputs. Extensive experiments on the BraTS 2018 and 2024 datasets demonstrate that AdaMM consistently outperforms existing methods, exhibiting superior segmentation accuracy and robustness, particularly in single-modality and weak-modality configurations. In addition, we conduct a systematic evaluation of six categories of missing-modality strategies, confirming the superiority of knowledge distillation and offering practical guidance for method selection and future research. Our source code is available at https://github.com/Quanato607/AdaMM.
Fin-PRM: A Domain-Specialized Process Reward Model for Financial Reasoning in Large Language Models
Aug 21, 2025Process Reward Models (PRMs) have emerged as a promising framework for supervising intermediate reasoning in large language models (LLMs), yet existing PRMs are primarily trained on general or Science, Technology, Engineering, and Mathematics (STEM) domains and fall short in domain-specific contexts such as finance, where reasoning is more structured, symbolic, and sensitive to factual and regulatory correctness. We introduce \textbf{Fin-PRM}, a domain-specialized, trajectory-aware PRM tailored to evaluate intermediate reasoning steps in financial tasks. Fin-PRM integrates step-level and trajectory-level reward supervision, enabling fine-grained evaluation of reasoning traces aligned with financial logic. We apply Fin-PRM in both offline and online reward learning settings, supporting three key applications: (i) selecting high-quality reasoning trajectories for distillation-based supervised fine-tuning, (ii) providing dense process-level rewards for reinforcement learning, and (iii) guiding reward-informed Best-of-N inference at test time. Experimental results on financial reasoning benchmarks, including CFLUE and FinQA, demonstrate that Fin-PRM consistently outperforms general-purpose PRMs and strong domain baselines in trajectory selection quality. Downstream models trained with Fin-PRM yield substantial improvements with baselines, with gains of 12.9\% in supervised learning, 5.2\% in reinforcement learning, and 5.1\% in test-time performance. These findings highlight the value of domain-specialized reward modeling for aligning LLMs with expert-level financial reasoning. Our project resources will be available at https://github.com/aliyun/qwen-dianjin.
Bridging the Gap in Missing Modalities: Leveraging Knowledge Distillation and Style Matching for Brain Tumor Segmentation
Jul 30, 2025Accurate and reliable brain tumor segmentation, particularly when dealing with missing modalities, remains a critical challenge in medical image analysis. Previous studies have not fully resolved the challenges of tumor boundary segmentation insensitivity and feature transfer in the absence of key imaging modalities. In this study, we introduce MST-KDNet, aimed at addressing these critical issues. Our model features Multi-Scale Transformer Knowledge Distillation to effectively capture attention weights at various resolutions, Dual-Mode Logit Distillation to improve the transfer of knowledge, and a Global Style Matching Module that integrates feature matching with adversarial learning. Comprehensive experiments conducted on the BraTS and FeTS 2024 datasets demonstrate that MST-KDNet surpasses current leading methods in both Dice and HD95 scores, particularly in conditions with substantial modality loss. Our approach shows exceptional robustness and generalization potential, making it a promising candidate for real-world clinical applications. Our source code is available at https://github.com/Quanato607/MST-KDNet.
* 11 pages, 2 figures