 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedGym:A Unified Continuous-Time Benchmark for Dynamic Medical Treatment Reinforcement Learning
May 31, 2026Medical treatment recommendation poses several challenges to reinforcement learning (RL): patient physiology evolves in continuous time, measurements and interventions are performed at irregular intervals, and treatment effects vary substantially across individuals. Existing RL formulations and simulated environments, however, are based on discrete-time MDP or POMDP abstractions with fixed or pre-specified decision intervals. Thus, it remains difficult to evaluate whether RL methods can handle time-interval-dependent disease progression, personalized treatment response, and safety between consecutive measurement points. To address this gap, we introduce MedGym, a benchmark environment for dynamic treatment recommendation. MedGym models longitudinal patient evolution in a continuous-time framework and constructs a configurable medical RL benchmark from clinical data by using Physics-Informed Neural Networks. The resulting benchmark supports both offline and online RL, and enables direct comparison between discrete-time and continuous-time methods under irregular treatment timing and patient-specific dynamics. Besides, MedGym supports evaluation from clinically important perspectives, including personalization, trajectory-level safety, and the performance gap between model-based offline learning and online deployment. By providing a standardized and configurable benchmark for continuous-time dynamic treatment, MedGym aims to facilitate more realistic and informative evaluation of medical RL methods.
Interaction-Limited Safe Continuous-Time RL for Dynamical Medical Treatment
May 31, 2026Dynamic medical treatment requires deciding treatment intensity and intervention timing, while patient states evolve continuously and adverse events may occur between clinical interactions. Most existing treatment learning methods assume fixed schedules or enforce safety only at discrete decision points. We propose Interaction-Limited Safe Continuous-Time Reinforcement Learning, a framework that jointly optimizes treatment administration and clinical interaction timing under trajectory-level safety constraints. Our key idea is to reformulate the continuous time treatment problem as an option-based semi-Markov decision process, where each option specifies a continuous-time treatment policy and its duration. We develop a safety-tightening mechanism showing that suitably constructed constraints at interaction times guarantee safety over the full continuous-time trajectory with high probability. We further establish finite-sample guarantees for policy learning from logged treatment trajectories and introduce a practical data-driven conservative surrogate. Experiments show that the proposed adaptive interaction-timing mechanism improves both safety and treatment effectiveness over equidistant interaction schemes across different safe policy optimization methods.
Offline Guarded Safe Reinforcement Learning for Medical Treatment Optimization Strategies
May 22, 2025When applying offline reinforcement learning (RL) in healthcare scenarios, the out-of-distribution (OOD) issues pose significant risks, as inappropriate generalization beyond clinical expertise can result in potentially harmful recommendations. While existing methods like conservative Q-learning (CQL) attempt to address the OOD issue, their effectiveness is limited by only constraining action selection by suppressing uncertain actions. This action-only regularization imitates clinician actions that prioritize short-term rewards, but it fails to regulate downstream state trajectories, thereby limiting the discovery of improved long-term treatment strategies. To safely improve policy beyond clinician recommendations while ensuring that state-action trajectories remain in-distribution, we propose \textit{Offline Guarded Safe Reinforcement Learning} ($\mathsf{OGSRL}$), a theoretically grounded model-based offline RL framework. $\mathsf{OGSRL}$ introduces a novel dual constraint mechanism for improving policy with reliability and safety. First, the OOD guardian is established to specify clinically validated regions for safe policy exploration. By constraining optimization within these regions, it enables the reliable exploration of treatment strategies that outperform clinician behavior by leveraging the full patient state history, without drifting into unsupported state-action trajectories. Second, we introduce a safety cost constraint that encodes medical knowledge about physiological safety boundaries, providing domain-specific safeguards even in areas where training data might contain potentially unsafe interventions. Notably, we provide theoretical guarantees on safety and near-optimality: policies that satisfy these constraints remain in safe and reliable regions and achieve performance close to the best possible policy supported by the data.
Flipping-based Policy for Chance-Constrained Markov Decision Processes
Oct 09, 2024
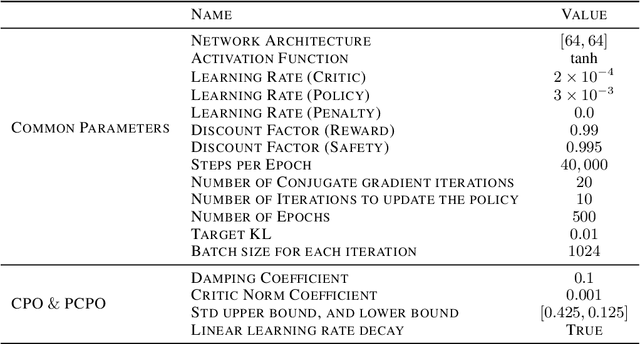
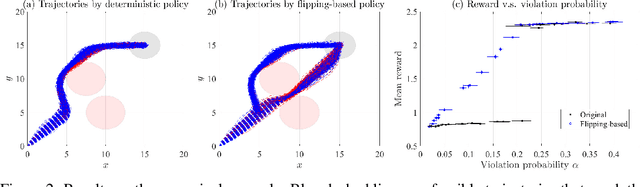

Safe reinforcement learning (RL) is a promising approach for many real-world decision-making problems where ensuring safety is a critical necessity. In safe RL research, while expected cumulative safety constraints (ECSCs) are typically the first choices, chance constraints are often more pragmatic for incorporating safety under uncertainties. This paper proposes a \textit{flipping-based policy} for Chance-Constrained Markov Decision Processes (CCMDPs). The flipping-based policy selects the next action by tossing a potentially distorted coin between two action candidates. The probability of the flip and the two action candidates vary depending on the state. We establish a Bellman equation for CCMDPs and further prove the existence of a flipping-based policy within the optimal solution sets. Since solving the problem with joint chance constraints is challenging in practice, we then prove that joint chance constraints can be approximated into Expected Cumulative Safety Constraints (ECSCs) and that there exists a flipping-based policy in the optimal solution sets for constrained MDPs with ECSCs. As a specific instance of practical implementations, we present a framework for adapting constrained policy optimization to train a flipping-based policy. This framework can be applied to other safe RL algorithms. We demonstrate that the flipping-based policy can improve the performance of the existing safe RL algorithms under the same limits of safety constraints on Safety Gym benchmarks.
Beyond Voice Assistants: Exploring Advantages and Risks of an In-Car Social Robot in Real Driving Scenarios
Feb 20, 2024



In-car Voice Assistants (VAs) play an increasingly critical role in automotive user interface design. However, existing VAs primarily perform simple 'query-answer' tasks, limiting their ability to sustain drivers' long-term attention. In this study, we investigate the effectiveness of an in-car Robot Assistant (RA) that offers functionalities beyond voice interaction. We aim to answer the question: How does the presence of a social robot impact user experience in real driving scenarios? Our study begins with a user survey to understand perspectives on in-car VAs and their influence on driving experiences. We then conduct non-driving and on-road experiments with selected participants to assess user experiences with an RA. Additionally, we conduct subjective ratings to evaluate user perceptions of the RA's personality, which is crucial for robot design. We also explore potential concerns regarding ethical risks. Finally, we provide a comprehensive discussion and recommendations for the future development of in-car RAs.
A Survey of Constraint Formulations in Safe Reinforcement Learning
Feb 03, 2024Ensuring safety is critical when applying reinforcement learning (RL) to real-world problems. Consequently, safe RL emerges as a fundamental and powerful paradigm for safely optimizing an agent's policy from experimental data. A popular safe RL approach is based on a constrained criterion, which solves the problem of maximizing expected cumulative reward under safety constraints. Though there has been recently a surge of such attempts to achieve safety in RL, a systematic understanding of the field is difficult due to 1) the diversity of constraint representations and 2) little discussion of their interrelations. To address this knowledge gap, we provide a comprehensive review of representative constraint formulations, along with a curated selection of algorithms specifically designed for each formulation. Furthermore, we elucidate the theoretical underpinnings that reveal the mathematical mutual relations among common problem formulations. We conclude with a discussion of the current state and future directions of safe reinforcement learning research.
Safe Exploration in Reinforcement Learning: A Generalized Formulation and Algorithms
Oct 05, 2023



Safe exploration is essential for the practical use of reinforcement learning (RL) in many real-world scenarios. In this paper, we present a generalized safe exploration (GSE) problem as a unified formulation of common safe exploration problems. We then propose a solution of the GSE problem in the form of a meta-algorithm for safe exploration, MASE, which combines an unconstrained RL algorithm with an uncertainty quantifier to guarantee safety in the current episode while properly penalizing unsafe explorations before actual safety violation to discourage them in future episodes. The advantage of MASE is that we can optimize a policy while guaranteeing with a high probability that no safety constraint will be violated under proper assumptions. Specifically, we present two variants of MASE with different constructions of the uncertainty quantifier: one based on generalized linear models with theoretical guarantees of safety and near-optimality, and another that combines a Gaussian process to ensure safety with a deep RL algorithm to maximize the reward. Finally, we demonstrate that our proposed algorithm achieves better performance than state-of-the-art algorithms on grid-world and Safety Gym benchmarks without violating any safety constraints, even during training.