 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Metrics to Meaning: Insights from a Mixed-Methods Field Experiment on Retail Robot Deployment
Jan 05, 2026We report a mixed-methods field experiment of a conversational service robot deployed under everyday staffing discretion in a live bedding store. Over 12 days we alternated three conditions--Baseline (no robot), Robot-only, and Robot+Fixture--and video-annotated the service funnel from passersby to purchase. An explanatory sequential design then used six post-experiment staff interviews to interpret the quantitative patterns. Quantitatively, the robot increased stopping per passerby (highest with the fixture), yet clerk-led downstream steps per stopper--clerk approach, store entry, assisted experience, and purchase--decreased. Interviews explained this divergence: clerks avoided interrupting ongoing robot-customer talk, struggled with ambiguous timing amid conversational latency, and noted child-centered attraction that often satisfied curiosity at the doorway. The fixture amplified visibility but also anchored encounters at the threshold, creating a well-defined micro-space where needs could ``close'' without moving inside. We synthesize these strands into an integrative account from the initial show of interest on the part of a customer to their entering the store and derive actionable guidance. The results advance the understanding of interactions between customers, staff members, and the robot and offer practical recommendations for deploying service robots in high-touch retail.
Value-Based Large Language Model Agent Simulation for Mutual Evaluation of Trust and Interpersonal Closeness
Jul 16, 2025Large language models (LLMs) have emerged as powerful tools for simulating complex social phenomena using human-like agents with specific traits. In human societies, value similarity is important for building trust and close relationships; however, it remains unexplored whether this principle holds true in artificial societies comprising LLM agents. Therefore, this study investigates the influence of value similarity on relationship-building among LLM agents through two experiments. First, in a preliminary experiment, we evaluated the controllability of values in LLMs to identify the most effective model and prompt design for controlling the values. Subsequently, in the main experiment, we generated pairs of LLM agents imbued with specific values and analyzed their mutual evaluations of trust and interpersonal closeness following a dialogue. The experiments were conducted in English and Japanese to investigate language dependence. The results confirmed that pairs of agents with higher value similarity exhibited greater mutual trust and interpersonal closeness. Our findings demonstrate that the LLM agent simulation serves as a valid testbed for social science theories, contributes to elucidating the mechanisms by which values influence relationship building, and provides a foundation for inspiring new theories and insights into the social sciences.
Public Acceptance of Cybernetic Avatars in the service sector: Evidence from a Large-Scale Survey in Dubai
Jun 17, 2025


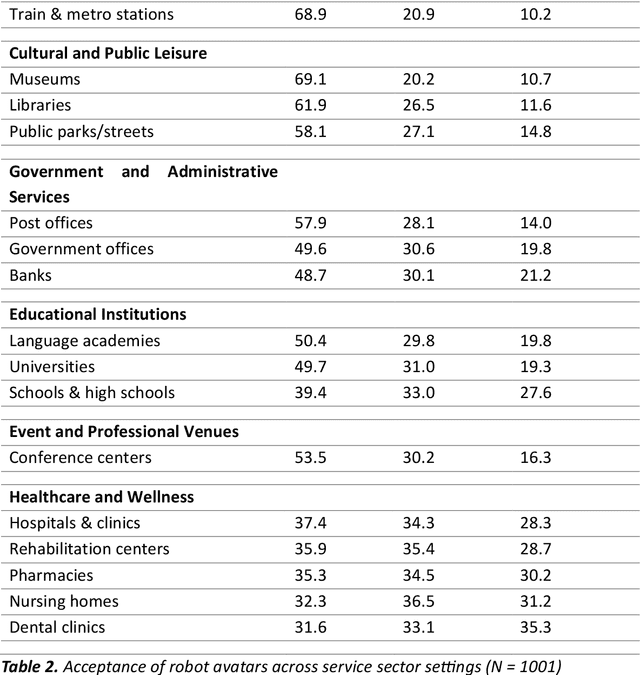
Cybernetic avatars are hybrid interaction robots or digital representations that combine autonomous capabilities with teleoperated control. This study investigates the acceptance of cybernetic avatars in the highly multicultural society of Dubai, with particular emphasis on robotic avatars for customer service. Specifically, we explore how acceptance varies as a function of robot appearance (e.g., android, robotic-looking, cartoonish), deployment settings (e.g., shopping malls, hotels, hospitals), and functional tasks (e.g., providing information, patrolling). To this end, we conducted a large-scale survey with over 1,000 participants. Overall, cybernetic avatars received a high level of acceptance, with physical robot avatars receiving higher acceptance than digital avatars. In terms of appearance, robot avatars with a highly anthropomorphic robotic appearance were the most accepted, followed by cartoonish designs and androids. Animal-like appearances received the lowest level of acceptance. Among the tasks, providing information and guidance was rated as the most valued. Shopping malls, airports, public transport stations, and museums were the settings with the highest acceptance, whereas healthcare-related spaces received lower levels of support. An analysis by community cluster revealed among others that Emirati respondents showed significantly greater acceptance of android appearances compared to the overall sample, while participants from the 'Other Asia' cluster were significantly more accepting of cartoonish appearances. Our study underscores the importance of incorporating citizen feedback into the design and deployment of cybernetic avatars from the early stages to enhance acceptance of this technology in society.
Hypothesis on the Functional Advantages of the Selection-Broadcast Cycle Structure: Global Workspace Theory and Dealing with a Real-Time World
May 20, 2025



This paper discusses the functional advantages of the Selection-Broadcast Cycle structure proposed by Global Workspace Theory (GWT), inspired by human consciousness, particularly focusing on its applicability to artificial intelligence and robotics in dynamic, real-time scenarios. While previous studies often examined the Selection and Broadcast processes independently, this research emphasizes their combined cyclic structure and the resulting benefits for real-time cognitive systems. Specifically, the paper identifies three primary benefits: Dynamic Thinking Adaptation, Experience-Based Adaptation, and Immediate Real-Time Adaptation. This work highlights GWT's potential as a cognitive architecture suitable for sophisticated decision-making and adaptive performance in unsupervised, dynamic environments. It suggests new directions for the development and implementation of robust, general-purpose AI and robotics systems capable of managing complex, real-world tasks.
The First MPDD Challenge: Multimodal Personality-aware Depression Detection
May 15, 2025


Depression is a widespread mental health issue affecting diverse age groups, with notable prevalence among college students and the elderly. However, existing datasets and detection methods primarily focus on young adults, neglecting the broader age spectrum and individual differences that influence depression manifestation. Current approaches often establish a direct mapping between multimodal data and depression indicators, failing to capture the complexity and diversity of depression across individuals. This challenge includes two tracks based on age-specific subsets: Track 1 uses the MPDD-Elderly dataset for detecting depression in older adults, and Track 2 uses the MPDD-Young dataset for detecting depression in younger participants. The Multimodal Personality-aware Depression Detection (MPDD) Challenge aims to address this gap by incorporating multimodal data alongside individual difference factors. We provide a baseline model that fuses audio and video modalities with individual difference information to detect depression manifestations in diverse populations. This challenge aims to promote the development of more personalized and accurate de pression detection methods, advancing mental health research and fostering inclusive detection systems. More details are available on the official challenge website: https://hacilab.github.io/MPDDChallenge.github.io.
Quadrupedal Spine Control Strategies: Exploring Correlations Between System Dynamic Responses and Human Perspectives
May 05, 2025Unlike their biological cousins, the majority of existing quadrupedal robots are constructed with rigid chassis. This results in motion that is either beetle-like or distinctly robotic, lacking the natural fluidity characteristic of mammalian movements. Existing literature on quadrupedal robots with spinal configurations primarily focuses on energy efficiency and does not consider the effects in human-robot interaction scenarios. Our contributions include an initial investigation into various trajectory generation strategies for a quadrupedal robot with a four degree of freedom spine, and an analysis on the effect that such methods have on human perception of gait naturalness compared to a fixed spine baseline. The strategies were evaluated using videos of walking, trotting and turning simulations. Among the four different strategies developed, the optimised time varying and the foot-tracking strategies were perceived to be more natural than the baseline in a randomised trial with 50 participants. Although none of the strategies demonstrated any energy efficiency improvements over the no-spine baseline, some showed greater footfall consistency at higher speeds. Given the greater likeability drawn from the more natural locomotion patterns, this type of robot displays potential for applications in social robot scenarios such as elderly care, where energy efficiency is not a primary concern.
* 27 pages, 13 figures
Beyond Voice Assistants: Exploring Advantages and Risks of an In-Car Social Robot in Real Driving Scenarios
Feb 20, 2024



In-car Voice Assistants (VAs) play an increasingly critical role in automotive user interface design. However, existing VAs primarily perform simple 'query-answer' tasks, limiting their ability to sustain drivers' long-term attention. In this study, we investigate the effectiveness of an in-car Robot Assistant (RA) that offers functionalities beyond voice interaction. We aim to answer the question: How does the presence of a social robot impact user experience in real driving scenarios? Our study begins with a user survey to understand perspectives on in-car VAs and their influence on driving experiences. We then conduct non-driving and on-road experiments with selected participants to assess user experiences with an RA. Additionally, we conduct subjective ratings to evaluate user perceptions of the RA's personality, which is crucial for robot design. We also explore potential concerns regarding ethical risks. Finally, we provide a comprehensive discussion and recommendations for the future development of in-car RAs.
Using joint training speaker encoder with consistency loss to achieve cross-lingual voice conversion and expressive voice conversion
Jul 01, 2023



Voice conversion systems have made significant advancements in terms of naturalness and similarity in common voice conversion tasks. However, their performance in more complex tasks such as cross-lingual voice conversion and expressive voice conversion remains imperfect. In this study, we propose a novel approach that combines a jointly trained speaker encoder and content features extracted from the cross-lingual speech recognition model Whisper to achieve high-quality cross-lingual voice conversion. Additionally, we introduce a speaker consistency loss to the joint encoder, which improves the similarity between the converted speech and the reference speech. To further explore the capabilities of the joint speaker encoder, we use the phonetic posteriorgram as the content feature, which enables the model to effectively reproduce both the speaker characteristics and the emotional aspects of the reference speech.
I Know Your Feelings Before You Do: Predicting Future Affective Reactions in Human-Computer Dialogue
Mar 17, 2023



Current Spoken Dialogue Systems (SDSs) often serve as passive listeners that respond only after receiving user speech. To achieve human-like dialogue, we propose a novel future prediction architecture that allows an SDS to anticipate future affective reactions based on its current behaviors before the user speaks. In this work, we investigate two scenarios: speech and laughter. In speech, we propose to predict the user's future emotion based on its temporal relationship with the system's current emotion and its causal relationship with the system's current Dialogue Act (DA). In laughter, we propose to predict the occurrence and type of the user's laughter using the system's laughter behaviors in the current turn. Preliminary analysis of human-robot dialogue demonstrated synchronicity in the emotions and laughter displayed by the human and robot, as well as DA-emotion causality in their dialogue. This verifies that our architecture can contribute to the development of an anticipatory SDS.
QuickVC: Any-to-many Voice Conversion Using Inverse Short-time Fourier Transform for Faster Conversion
Feb 23, 2023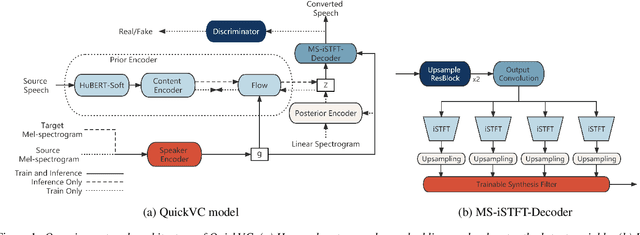



With the development of automatic speech recognition (ASR) and text-to-speech (TTS) technology, high-quality voice conversion (VC) can be achieved by extracting source content information and target speaker information to reconstruct waveforms. However, current methods still require improvement in terms of inference speed. In this study, we propose a lightweight VITS-based VC model that uses the HuBERT-Soft model to extract content information features without speaker information. Through subjective and objective experiments on synthesized speech, the proposed model demonstrates competitive results in terms of naturalness and similarity. Importantly, unlike the original VITS model, we use the inverse short-time Fourier transform (iSTFT) to replace the most computationally expensive part. Experimental results show that our model can generate samples at over 5000 kHz on the 3090 GPU and over 250 kHz on the i9-10900K CPU, achieving competitive speed for the same hardware configuration.