 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing joint training speaker encoder with consistency loss to achieve cross-lingual voice conversion and expressive voice conversion
Jul 01, 2023



Voice conversion systems have made significant advancements in terms of naturalness and similarity in common voice conversion tasks. However, their performance in more complex tasks such as cross-lingual voice conversion and expressive voice conversion remains imperfect. In this study, we propose a novel approach that combines a jointly trained speaker encoder and content features extracted from the cross-lingual speech recognition model Whisper to achieve high-quality cross-lingual voice conversion. Additionally, we introduce a speaker consistency loss to the joint encoder, which improves the similarity between the converted speech and the reference speech. To further explore the capabilities of the joint speaker encoder, we use the phonetic posteriorgram as the content feature, which enables the model to effectively reproduce both the speaker characteristics and the emotional aspects of the reference speech.
QuickVC: Any-to-many Voice Conversion Using Inverse Short-time Fourier Transform for Faster Conversion
Feb 23, 2023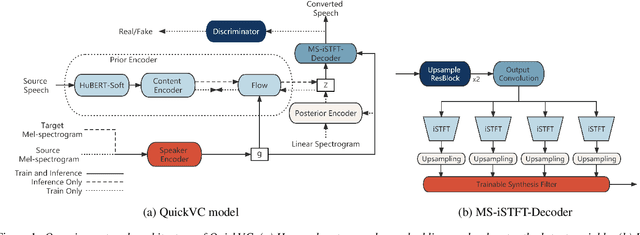



With the development of automatic speech recognition (ASR) and text-to-speech (TTS) technology, high-quality voice conversion (VC) can be achieved by extracting source content information and target speaker information to reconstruct waveforms. However, current methods still require improvement in terms of inference speed. In this study, we propose a lightweight VITS-based VC model that uses the HuBERT-Soft model to extract content information features without speaker information. Through subjective and objective experiments on synthesized speech, the proposed model demonstrates competitive results in terms of naturalness and similarity. Importantly, unlike the original VITS model, we use the inverse short-time Fourier transform (iSTFT) to replace the most computationally expensive part. Experimental results show that our model can generate samples at over 5000 kHz on the 3090 GPU and over 250 kHz on the i9-10900K CPU, achieving competitive speed for the same hardware configuration.
CycleTransGAN-EVC: A CycleGAN-based Emotional Voice Conversion Model with Transformer
Nov 30, 2021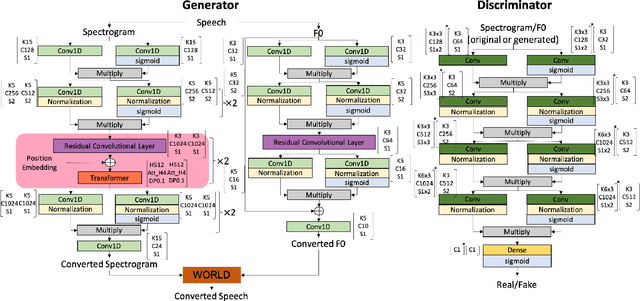

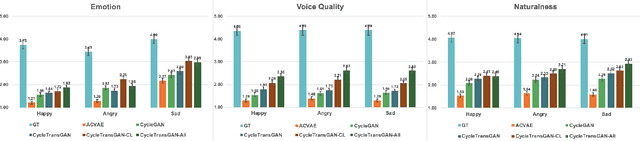
In this study, we explore the transformer's ability to capture intra-relations among frames by augmenting the receptive field of models. Concretely, we propose a CycleGAN-based model with the transformer and investigate its ability in the emotional voice conversion task. In the training procedure, we adopt curriculum learning to gradually increase the frame length so that the model can see from the short segment till the entire speech. The proposed method was evaluated on the Japanese emotional speech dataset and compared to several baselines (ACVAE, CycleGAN) with objective and subjective evaluations. The results show that our proposed model is able to convert emotion with higher strength and quality.
SeMemNN: A Semantic Matrix-Based Memory Neural Network for Text Classification
Mar 04, 2020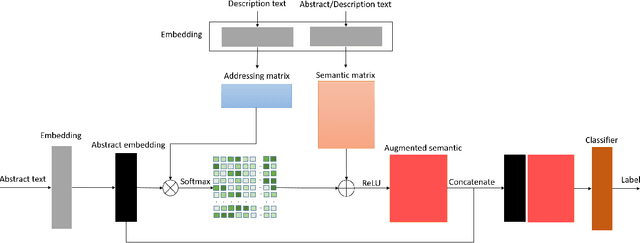
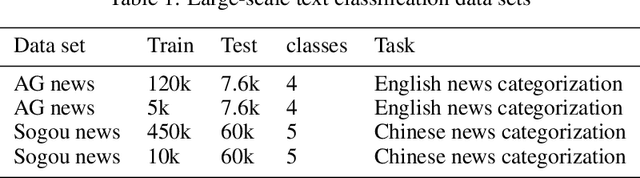
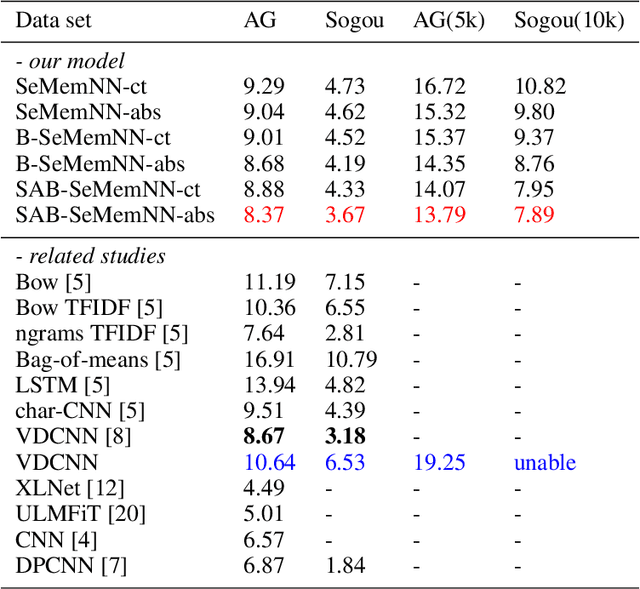
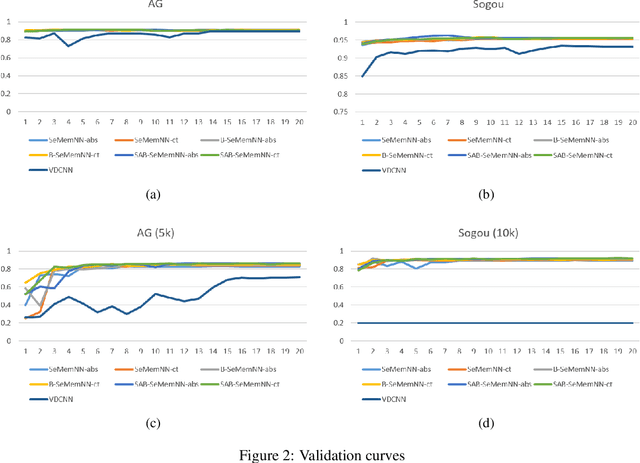
Text categorization is the task of assigning labels to documents written in a natural language, and it has numerous real-world applications including sentiment analysis as well as traditional topic assignment tasks. In this paper, we propose 5 different configurations for the semantic matrix-based memory neural network with end-to-end learning manner and evaluate our proposed method on two corpora of news articles (AG news, Sogou news). The best performance of our proposed method outperforms the baseline VDCNN models on the text classification task and gives a faster speed for learning semantics. Moreover, we also evaluate our model on small scale datasets. The results show that our proposed method can still achieve better results in comparison to VDCNN on the small scale dataset. This paper is to appear in the Proceedings of the 2020 IEEE 14th International Conference on Semantic Computing (ICSC 2020), San Diego, California, 2020.