 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonality-guided Public-Private Domain Disentangled Hypergraph-Former Network for Multimodal Depression Detection
Nov 16, 2025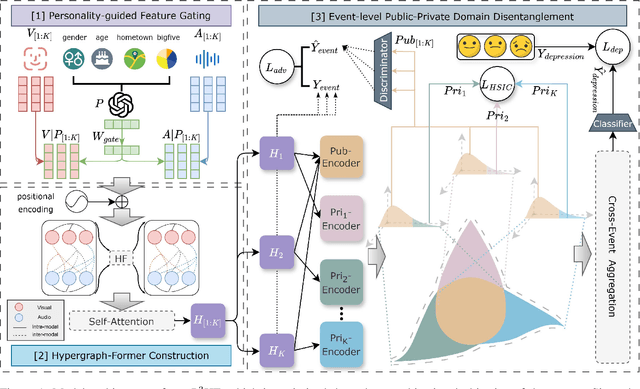
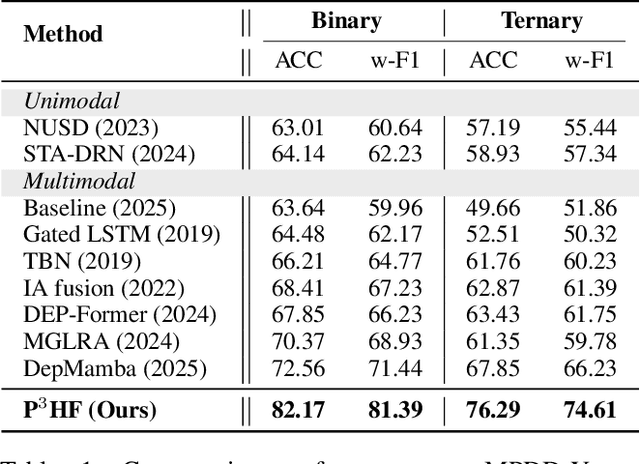
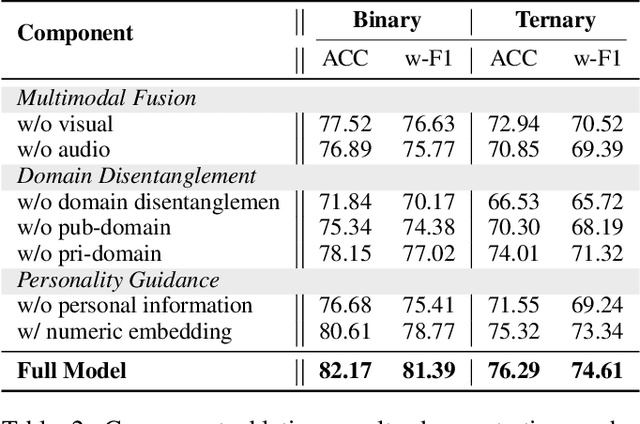
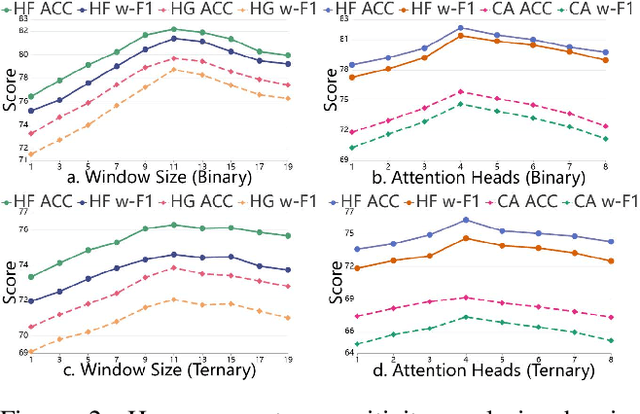
Depression represents a global mental health challenge requiring efficient and reliable automated detection methods. Current Transformer- or Graph Neural Networks (GNNs)-based multimodal depression detection methods face significant challenges in modeling individual differences and cross-modal temporal dependencies across diverse behavioral contexts. Therefore, we propose P$^3$HF (Personality-guided Public-Private Domain Disentangled Hypergraph-Former Network) with three key innovations: (1) personality-guided representation learning using LLMs to transform discrete individual features into contextual descriptions for personalized encoding; (2) Hypergraph-Former architecture modeling high-order cross-modal temporal relationships; (3) event-level domain disentanglement with contrastive learning for improved generalization across behavioral contexts. Experiments on MPDD-Young dataset show P$^3$HF achieves around 10\% improvement on accuracy and weighted F1 for binary and ternary depression classification task over existing methods. Extensive ablation studies validate the independent contribution of each architectural component, confirming that personality-guided representation learning and high-order hypergraph reasoning are both essential for generating robust, individual-aware depression-related representations. The code is released at https://github.com/hacilab/P3HF.
The First MPDD Challenge: Multimodal Personality-aware Depression Detection
May 15, 2025
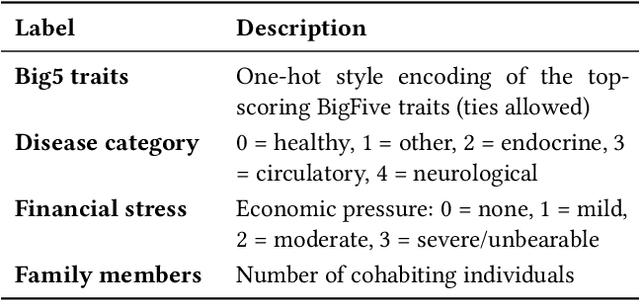


Depression is a widespread mental health issue affecting diverse age groups, with notable prevalence among college students and the elderly. However, existing datasets and detection methods primarily focus on young adults, neglecting the broader age spectrum and individual differences that influence depression manifestation. Current approaches often establish a direct mapping between multimodal data and depression indicators, failing to capture the complexity and diversity of depression across individuals. This challenge includes two tracks based on age-specific subsets: Track 1 uses the MPDD-Elderly dataset for detecting depression in older adults, and Track 2 uses the MPDD-Young dataset for detecting depression in younger participants. The Multimodal Personality-aware Depression Detection (MPDD) Challenge aims to address this gap by incorporating multimodal data alongside individual difference factors. We provide a baseline model that fuses audio and video modalities with individual difference information to detect depression manifestations in diverse populations. This challenge aims to promote the development of more personalized and accurate de pression detection methods, advancing mental health research and fostering inclusive detection systems. More details are available on the official challenge website: https://hacilab.github.io/MPDDChallenge.github.io.
I Know Your Feelings Before You Do: Predicting Future Affective Reactions in Human-Computer Dialogue
Mar 17, 2023



Current Spoken Dialogue Systems (SDSs) often serve as passive listeners that respond only after receiving user speech. To achieve human-like dialogue, we propose a novel future prediction architecture that allows an SDS to anticipate future affective reactions based on its current behaviors before the user speaks. In this work, we investigate two scenarios: speech and laughter. In speech, we propose to predict the user's future emotion based on its temporal relationship with the system's current emotion and its causal relationship with the system's current Dialogue Act (DA). In laughter, we propose to predict the occurrence and type of the user's laughter using the system's laughter behaviors in the current turn. Preliminary analysis of human-robot dialogue demonstrated synchronicity in the emotions and laughter displayed by the human and robot, as well as DA-emotion causality in their dialogue. This verifies that our architecture can contribute to the development of an anticipatory SDS.
CycleTransGAN-EVC: A CycleGAN-based Emotional Voice Conversion Model with Transformer
Nov 30, 2021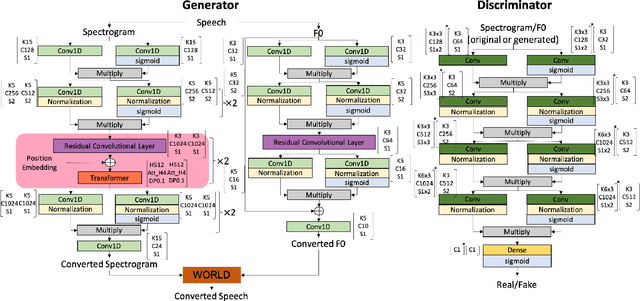

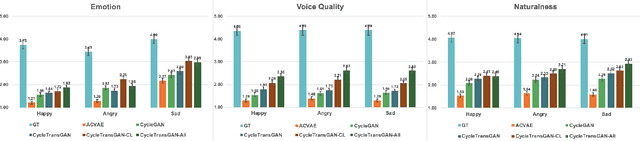
In this study, we explore the transformer's ability to capture intra-relations among frames by augmenting the receptive field of models. Concretely, we propose a CycleGAN-based model with the transformer and investigate its ability in the emotional voice conversion task. In the training procedure, we adopt curriculum learning to gradually increase the frame length so that the model can see from the short segment till the entire speech. The proposed method was evaluated on the Japanese emotional speech dataset and compared to several baselines (ACVAE, CycleGAN) with objective and subjective evaluations. The results show that our proposed model is able to convert emotion with higher strength and quality.
JPS-daprinfo: A Dataset for Japanese Dialog Act Analysis and People-related Information Detection
Mar 06, 2021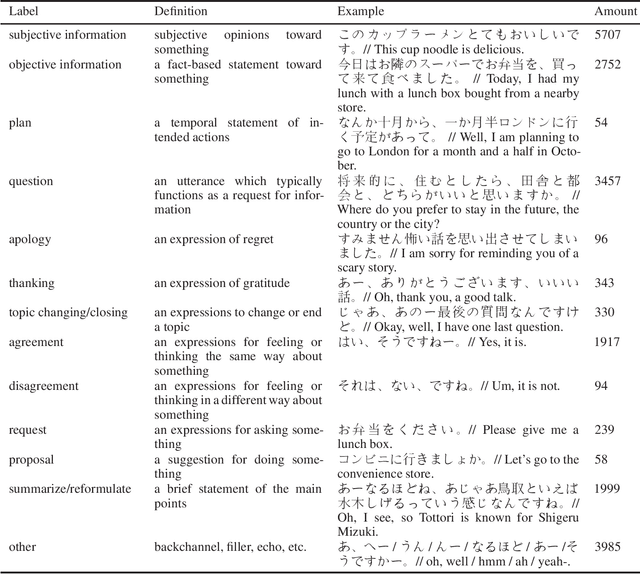
We conducted a labeling work on a spoken Japanese dataset (I-JAS) for the text classification, which contains 50 interview dialogues of two-way Japanese conversation that discuss the participants' past present and future. Each dialogue is 30 minutes long. From this dataset, we selected the interview dialogues of native Japanese speakers as the samples. Given the dataset, we annotated sentences with 13 labels. The labeling work was conducted by native Japanese speakers who have experiences with data annotation. The total amount of the annotated samples is 20130.
SeMemNN: A Semantic Matrix-Based Memory Neural Network for Text Classification
Mar 04, 2020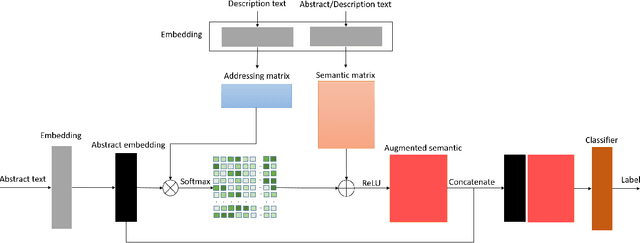
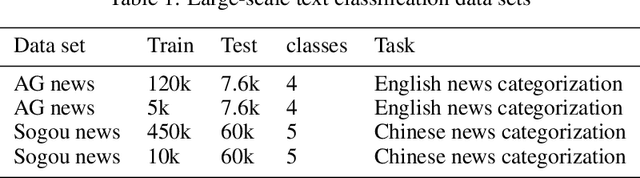
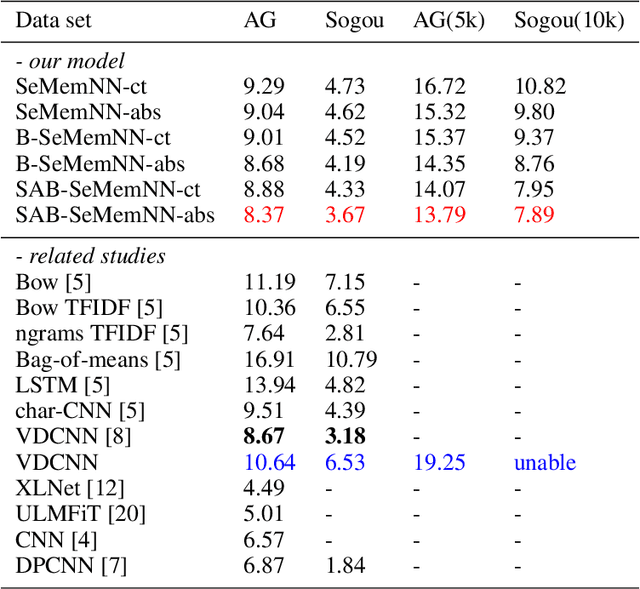
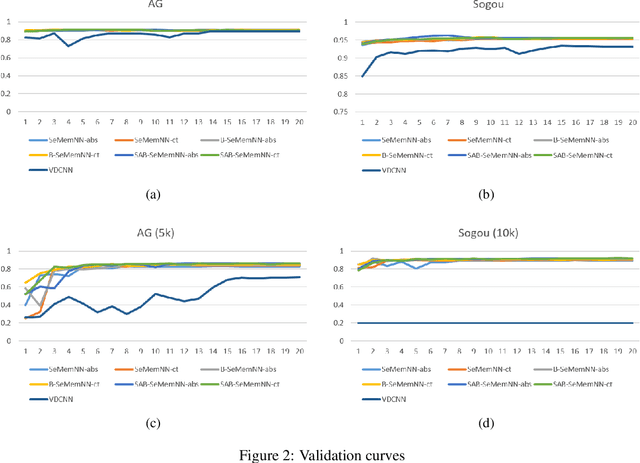
Text categorization is the task of assigning labels to documents written in a natural language, and it has numerous real-world applications including sentiment analysis as well as traditional topic assignment tasks. In this paper, we propose 5 different configurations for the semantic matrix-based memory neural network with end-to-end learning manner and evaluate our proposed method on two corpora of news articles (AG news, Sogou news). The best performance of our proposed method outperforms the baseline VDCNN models on the text classification task and gives a faster speed for learning semantics. Moreover, we also evaluate our model on small scale datasets. The results show that our proposed method can still achieve better results in comparison to VDCNN on the small scale dataset. This paper is to appear in the Proceedings of the 2020 IEEE 14th International Conference on Semantic Computing (ICSC 2020), San Diego, California, 2020.