 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe First MPDD Challenge: Multimodal Personality-aware Depression Detection
May 15, 2025


Depression is a widespread mental health issue affecting diverse age groups, with notable prevalence among college students and the elderly. However, existing datasets and detection methods primarily focus on young adults, neglecting the broader age spectrum and individual differences that influence depression manifestation. Current approaches often establish a direct mapping between multimodal data and depression indicators, failing to capture the complexity and diversity of depression across individuals. This challenge includes two tracks based on age-specific subsets: Track 1 uses the MPDD-Elderly dataset for detecting depression in older adults, and Track 2 uses the MPDD-Young dataset for detecting depression in younger participants. The Multimodal Personality-aware Depression Detection (MPDD) Challenge aims to address this gap by incorporating multimodal data alongside individual difference factors. We provide a baseline model that fuses audio and video modalities with individual difference information to detect depression manifestations in diverse populations. This challenge aims to promote the development of more personalized and accurate de pression detection methods, advancing mental health research and fostering inclusive detection systems. More details are available on the official challenge website: https://hacilab.github.io/MPDDChallenge.github.io.
Multi-scale Sparse Representation-Based Shadow Inpainting for Retinal OCT Images
Feb 23, 2022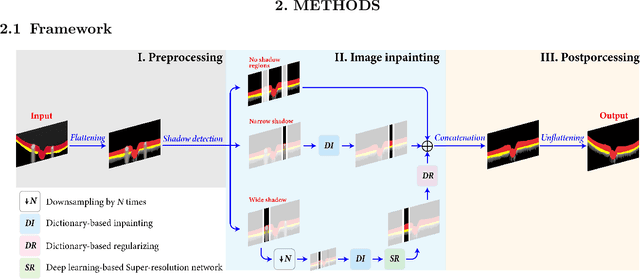


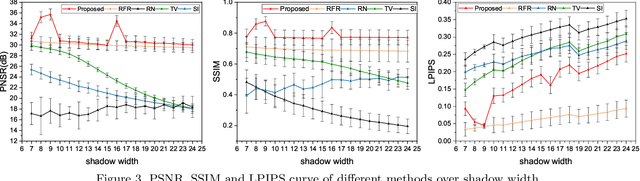
Inpainting shadowed regions cast by superficial blood vessels in retinal optical coherence tomography (OCT) images is critical for accurate and robust machine analysis and clinical diagnosis. Traditional sequence-based approaches such as propagating neighboring information to gradually fill in the missing regions are cost-effective. But they generate less satisfactory outcomes when dealing with larger missing regions and texture-rich structures. Emerging deep learning-based methods such as encoder-decoder networks have shown promising results in natural image inpainting tasks. However, they typically need a long computational time for network training in addition to the high demand on the size of datasets, which makes it difficult to be applied on often small medical datasets. To address these challenges, we propose a novel multi-scale shadow inpainting framework for OCT images by synergically applying sparse representation and deep learning: sparse representation is used to extract features from a small amount of training images for further inpainting and to regularize the image after the multi-scale image fusion, while convolutional neural network (CNN) is employed to enhance the image quality. During the image inpainting, we divide preprocessed input images into different branches based on the shadow width to harvest complementary information from different scales. Finally, a sparse representation-based regularizing module is designed to refine the generated contents after multi-scale feature aggregation. Experiments are conducted to compare our proposal versus both traditional and deep learning-based techniques on synthetic and real-world shadows. Results demonstrate that our proposed method achieves favorable image inpainting in terms of visual quality and quantitative metrics, especially when wide shadows are presented.
Frequency-Aware Physics-Inspired Degradation Model for Real-World Image Super-Resolution
Nov 05, 2021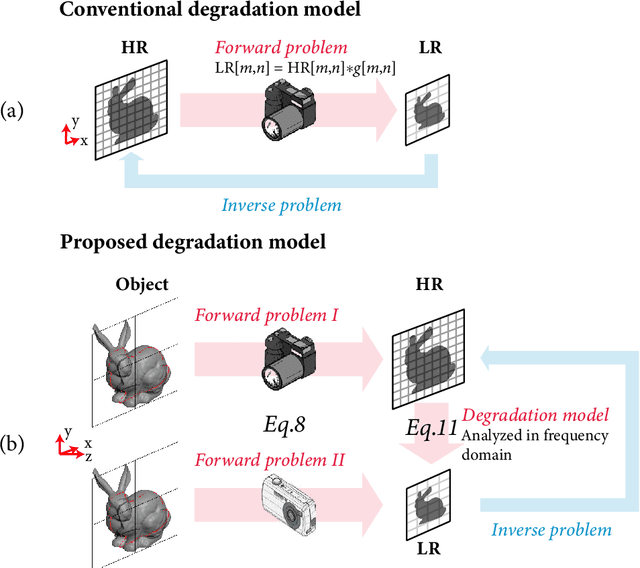

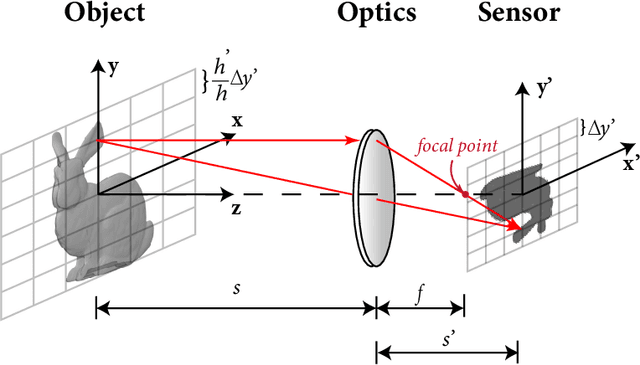
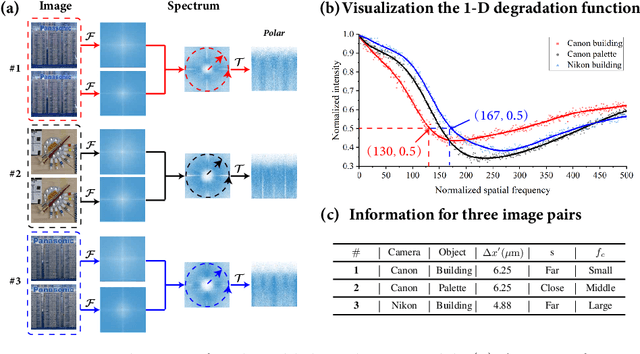
Current learning-based single image super-resolution (SISR) algorithms underperform on real data due to the deviation in the assumed degrada-tion process from that in the real-world scenario. Conventional degradation processes consider applying blur, noise, and downsampling (typicallybicubic downsampling) on high-resolution (HR) images to synthesize low-resolution (LR) counterparts. However, few works on degradation modelling have taken the physical aspects of the optical imaging system intoconsideration. In this paper, we analyze the imaging system optically andexploit the characteristics of the real-world LR-HR pairs in the spatial frequency domain. We formulate a real-world physics-inspired degradationmodel by considering bothopticsandsensordegradation; The physical degradation of an imaging system is modelled as a low-pass filter, whose cut-off frequency is dictated by the object distance, the focal length of thelens, and the pixel size of the image sensor. In particular, we propose to use a convolutional neural network (CNN) to learn the cutoff frequency of real-world degradation process. The learned network is then applied to synthesize LR images from unpaired HR images. The synthetic HR-LR image pairs are later used to train an SISR network. We evaluatethe effectiveness and generalization capability of the proposed degradation model on real-world images captured by different imaging systems. Experimental results showcase that the SISR network trained by using our synthetic data performs favorably against the network using the traditional degradation model. Moreover, our results are comparable to that obtained by the same network trained by using real-world LR-HR pairs, which are challenging to obtain in real scenes.
Large depth of range Maxwellian-viewing SMV near-eye display based on a Pancharatnam-Berry optical element
May 17, 2021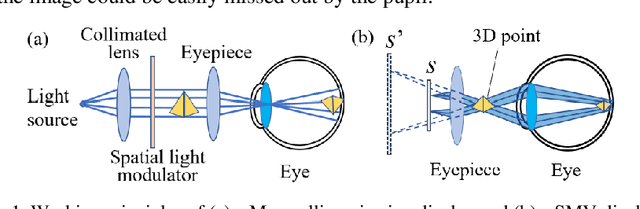
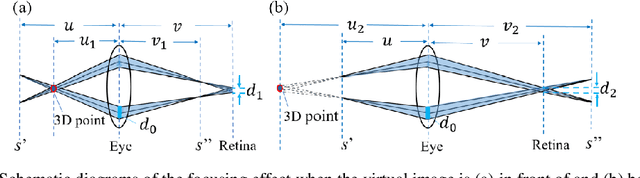
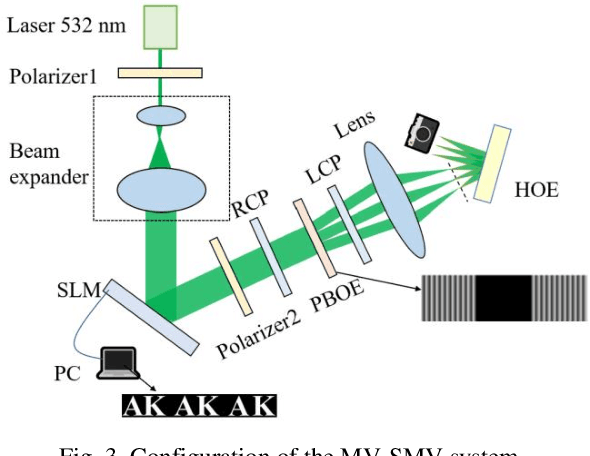
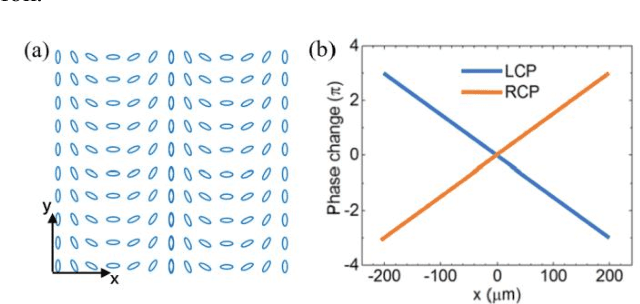
In order to overcome the accommodation and convergence (A-C) conflict that commonly causes visual fatigue in AR display, we propose a Maxwellian-viewing-super-multi-view (MV-SMV) near-eye display system based on a Pancharatnam-Berry optical element (PBOE). The PBOE, which is constituted with an array of high-efficiency polarization gratings, is implemented to direct different views to different directions simultaneously, constructing the 3D light field. Meanwhile, each view is like a Maxwellian view display that possesses a small viewpoint and a large depth of field (DOF). Hence, the MV-SMV display can display virtual images with correct accommodation depth cue within a large DOF. We implement a proof-of-concept MV-SMV display prototype with 3 x 1 and 3 x 2 viewpoints using a 1D PBOE and a 2D PBOE, respectively, and achieve a DOF of 4.37 diopters experimentally.
Multi-scale GCN-assisted two-stage network for joint segmentation of retinal layers and disc in peripapillary OCT images
Feb 09, 2021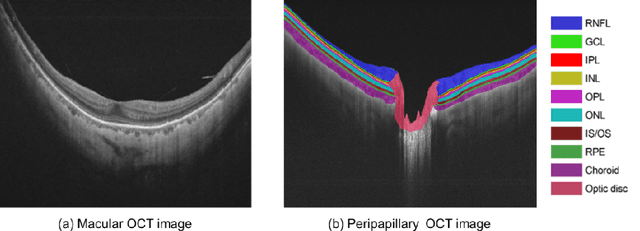
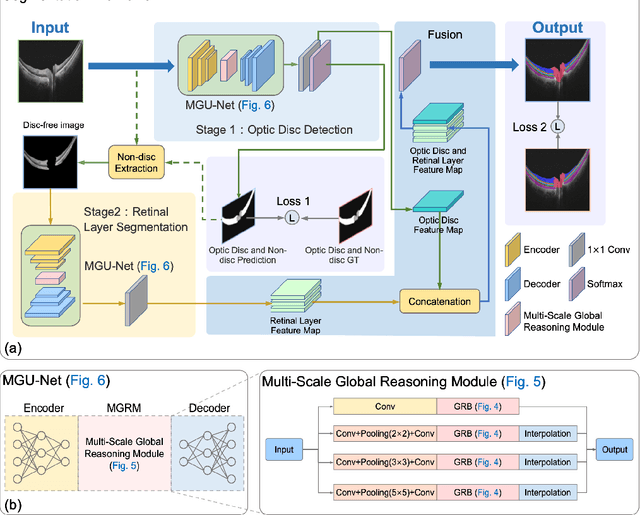
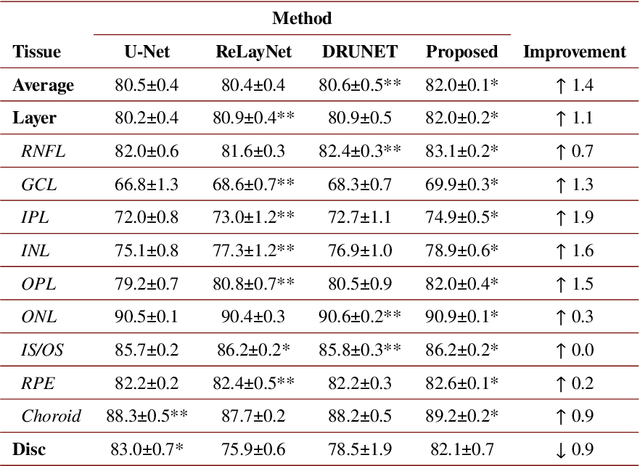
An accurate and automated tissue segmentation algorithm for retinal optical coherence tomography (OCT) images is crucial for the diagnosis of glaucoma. However, due to the presence of the optic disc, the anatomical structure of the peripapillary region of the retina is complicated and is challenging for segmentation. To address this issue, we developed a novel graph convolutional network (GCN)-assisted two-stage framework to simultaneously label the nine retinal layers and the optic disc. Specifically, a multi-scale global reasoning module is inserted between the encoder and decoder of a U-shape neural network to exploit anatomical prior knowledge and perform spatial reasoning. We conducted experiments on human peripapillary retinal OCT images. The Dice score of the proposed segmentation network is 0.820$\pm$0.001 and the pixel accuracy is 0.830$\pm$0.002, both of which outperform those from other state-of-the-art techniques.