 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal and Provable Calibration in High-Dimensional Binary Classification: Angular Calibration and Platt Scaling
Feb 21, 2025We study the fundamental problem of calibrating a linear binary classifier of the form $\sigma(\hat{w}^\top x)$, where the feature vector $x$ is Gaussian, $\sigma$ is a link function, and $\hat{w}$ is an estimator of the true linear weight $w^\star$. By interpolating with a noninformative $\textit{chance classifier}$, we construct a well-calibrated predictor whose interpolation weight depends on the angle $\angle(\hat{w}, w_\star)$ between the estimator $\hat{w}$ and the true linear weight $w_\star$. We establish that this angular calibration approach is provably well-calibrated in a high-dimensional regime where the number of samples and features both diverge, at a comparable rate. The angle $\angle(\hat{w}, w_\star)$ can be consistently estimated. Furthermore, the resulting predictor is uniquely $\textit{Bregman-optimal}$, minimizing the Bregman divergence to the true label distribution within a suitable class of calibrated predictors. Our work is the first to provide a calibration strategy that satisfies both calibration and optimality properties provably in high dimensions. Additionally, we identify conditions under which a classical Platt-scaling predictor converges to our Bregman-optimal calibrated solution. Thus, Platt-scaling also inherits these desirable properties provably in high dimensions.
ROTI-GCV: Generalized Cross-Validation for right-ROTationally Invariant Data
Jun 17, 2024Two key tasks in high-dimensional regularized regression are tuning the regularization strength for good predictions and estimating the out-of-sample risk. It is known that the standard approach -- $k$-fold cross-validation -- is inconsistent in modern high-dimensional settings. While leave-one-out and generalized cross-validation remain consistent in some high-dimensional cases, they become inconsistent when samples are dependent or contain heavy-tailed covariates. To model structured sample dependence and heavy tails, we use right-rotationally invariant covariate distributions - a crucial concept from compressed sensing. In the common modern proportional asymptotics regime where the number of features and samples grow comparably, we introduce a new framework, ROTI-GCV, for reliably performing cross-validation. Along the way, we propose new estimators for the signal-to-noise ratio and noise variance under these challenging conditions. We conduct extensive experiments that demonstrate the power of our approach and its superiority over existing methods.
Understanding Optimal Feature Transfer via a Fine-Grained Bias-Variance Analysis
Apr 18, 2024In the transfer learning paradigm models learn useful representations (or features) during a data-rich pretraining stage, and then use the pretrained representation to improve model performance on data-scarce downstream tasks. In this work, we explore transfer learning with the goal of optimizing downstream performance. We introduce a simple linear model that takes as input an arbitrary pretrained feature transform. We derive exact asymptotics of the downstream risk and its fine-grained bias-variance decomposition. Our finding suggests that using the ground-truth featurization can result in "double-divergence" of the asymptotic risk, indicating that it is not necessarily optimal for downstream performance. We then identify the optimal pretrained representation by minimizing the asymptotic downstream risk averaged over an ensemble of downstream tasks. Our analysis reveals the relative importance of learning the task-relevant features and structures in the data covariates and characterizes how each contributes to controlling the downstream risk from a bias-variance perspective. Moreover, we uncover a phase transition phenomenon where the optimal pretrained representation transitions from hard to soft selection of relevant features and discuss its connection to principal component regression.
Spectrum-Aware Adjustment: A New Debiasing Framework with Applications to Principal Components Regression
Sep 14, 2023



We introduce a new debiasing framework for high-dimensional linear regression that bypasses the restrictions on covariate distributions imposed by modern debiasing technology. We study the prevalent setting where the number of features and samples are both large and comparable. In this context, state-of-the-art debiasing technology uses a degrees-of-freedom correction to remove shrinkage bias of regularized estimators and conduct inference. However, this method requires that the observed samples are i.i.d., the covariates follow a mean zero Gaussian distribution, and reliable covariance matrix estimates for observed features are available. This approach struggles when (i) covariates are non-Gaussian with heavy tails or asymmetric distributions, (ii) rows of the design exhibit heterogeneity or dependencies, and (iii) reliable feature covariance estimates are lacking. To address these, we develop a new strategy where the debiasing correction is a rescaled gradient descent step (suitably initialized) with step size determined by the spectrum of the sample covariance matrix. Unlike prior work, we assume that eigenvectors of this matrix are uniform draws from the orthogonal group. We show this assumption remains valid in diverse situations where traditional debiasing fails, including designs with complex row-column dependencies, heavy tails, asymmetric properties, and latent low-rank structures. We establish asymptotic normality of our proposed estimator (centered and scaled) under various convergence notions. Moreover, we develop a consistent estimator for its asymptotic variance. Lastly, we introduce a debiased Principal Component Regression (PCR) technique using our Spectrum-Aware approach. In varied simulations and real data experiments, we observe that our method outperforms degrees-of-freedom debiasing by a margin.
Balancing Risk and Reward: An Automated Phased Release Strategy
May 16, 2023Phased releases are a common strategy in the technology industry for gradually releasing new products or updates through a sequence of A/B tests in which the number of treated units gradually grows until full deployment or deprecation. Performing phased releases in a principled way requires selecting the proportion of units assigned to the new release in a way that balances the risk of an adverse effect with the need to iterate and learn from the experiment rapidly. In this paper, we formalize this problem and propose an algorithm that automatically determines the release percentage at each stage in the schedule, balancing the need to control risk while maximizing ramp-up speed. Our framework models the challenge as a constrained batched bandit problem that ensures that our pre-specified experimental budget is not depleted with high probability. Our proposed algorithm leverages an adaptive Bayesian approach in which the maximal number of units assigned to the treatment is determined by the posterior distribution, ensuring that the probability of depleting the remaining budget is low. Notably, our approach analytically solves the ramp sizes by inverting probability bounds, eliminating the need for challenging rare-event Monte Carlo simulation. It only requires computing means and variances of outcome subsets, making it highly efficient and parallelizable.
Automatic Identification of Coal and Rock/Gangue Based on DenseNet and Gaussian Process
Aug 31, 2022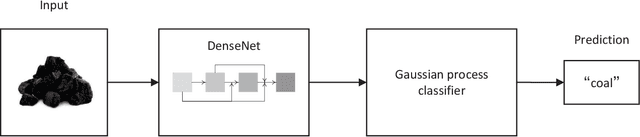
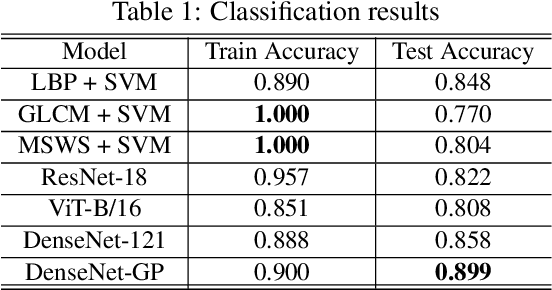

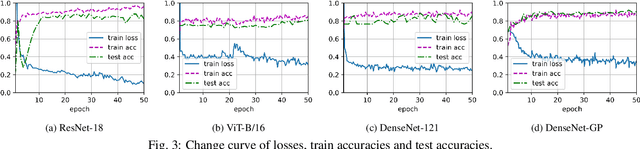
To improve the purity of coal and prevent damage to the coal mining machine, it is necessary to identify coal and rock in underground coal mines. At the same time, the mined coal needs to be purified to remove rock and gangue. These two procedures are manually operated by workers in most coal mines. The realization of automatic identification and purification is not only conducive to the automation of coal mines, but also ensures the safety of workers. We discuss the possibility of using image-based methods to distinguish them. In order to find a solution that can be used in both scenarios, a model that forwards image feature extracted by DenseNet to Gaussian process is proposed, which is trained on images taken on surface and achieves high accuracy on images taken underground. This indicates our method is powerful in few-shot learning such as identification of coal and rock/gangue and might be beneficial for realizing automation in coal mines.
Modeling Temporal-Modal Entity Graph for Procedural Multimodal Machine Comprehension
Apr 06, 2022Procedural Multimodal Documents (PMDs) organize textual instructions and corresponding images step by step. Comprehending PMDs and inducing their representations for the downstream reasoning tasks is designated as Procedural MultiModal Machine Comprehension (M3C). In this study, we approach Procedural M3C at a fine-grained level (compared with existing explorations at a document or sentence level), that is, entity. With delicate consideration, we model entity both in its temporal and cross-modal relation and propose a novel Temporal-Modal Entity Graph (TMEG). Specifically, graph structure is formulated to capture textual and visual entities and trace their temporal-modal evolution. In addition, a graph aggregation module is introduced to conduct graph encoding and reasoning. Comprehensive experiments across three Procedural M3C tasks are conducted on a traditional dataset RecipeQA and our new dataset CraftQA, which can better evaluate the generalization of TMEG.
Multi-scale Sparse Representation-Based Shadow Inpainting for Retinal OCT Images
Feb 23, 2022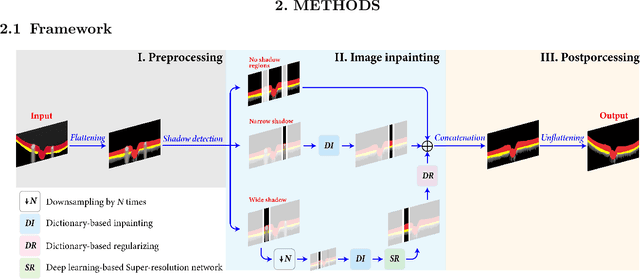


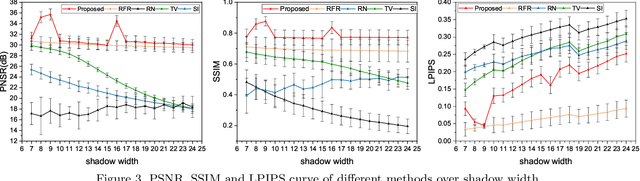
Inpainting shadowed regions cast by superficial blood vessels in retinal optical coherence tomography (OCT) images is critical for accurate and robust machine analysis and clinical diagnosis. Traditional sequence-based approaches such as propagating neighboring information to gradually fill in the missing regions are cost-effective. But they generate less satisfactory outcomes when dealing with larger missing regions and texture-rich structures. Emerging deep learning-based methods such as encoder-decoder networks have shown promising results in natural image inpainting tasks. However, they typically need a long computational time for network training in addition to the high demand on the size of datasets, which makes it difficult to be applied on often small medical datasets. To address these challenges, we propose a novel multi-scale shadow inpainting framework for OCT images by synergically applying sparse representation and deep learning: sparse representation is used to extract features from a small amount of training images for further inpainting and to regularize the image after the multi-scale image fusion, while convolutional neural network (CNN) is employed to enhance the image quality. During the image inpainting, we divide preprocessed input images into different branches based on the shadow width to harvest complementary information from different scales. Finally, a sparse representation-based regularizing module is designed to refine the generated contents after multi-scale feature aggregation. Experiments are conducted to compare our proposal versus both traditional and deep learning-based techniques on synthetic and real-world shadows. Results demonstrate that our proposed method achieves favorable image inpainting in terms of visual quality and quantitative metrics, especially when wide shadows are presented.
Culture-inspired Multi-modal Color Palette Generation and Colorization: A Chinese Youth Subculture Case
Feb 10, 2021

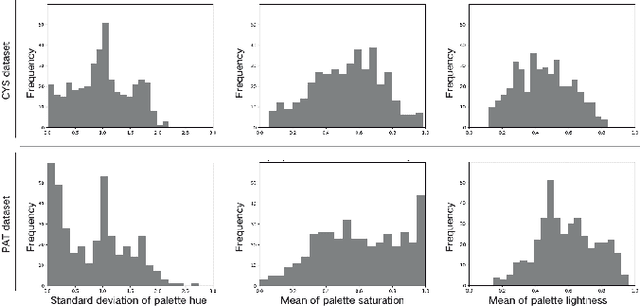
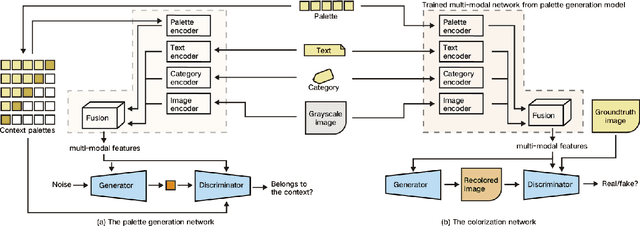
Color is an essential component of graphic design, acting not only as a visual factor but also carrying cultural implications. However, existing research on algorithmic color palette generation and colorization largely ignores the cultural aspect. In this paper, we contribute to this line of research by first constructing a unique color dataset inspired by a specific culture, i.e., Chinese Youth Subculture (CYS), which is an vibrant and trending cultural group especially for the Gen Z population. We show that the colors used in CYS have special aesthetic and semantic characteristics that are different from generic color theory. We then develop an interactive multi-modal generative framework to create CYS-styled color palettes, which can be used to put a CYS twist on images using our automatic colorization model. Our framework is illustrated via a demo system designed with the human-in-the-loop principle that constantly provides feedback to our algorithms. User studies are also conducted to evaluate our generation results.