 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-aware optical coherence tomography image super-resolution via conditional generative adversarial neural network
Jul 20, 2023



Optical coherence tomography (OCT) has stimulated a wide range of medical image-based diagnosis and treatment in fields such as cardiology and ophthalmology. Such applications can be further facilitated by deep learning-based super-resolution technology, which improves the capability of resolving morphological structures. However, existing deep learning-based method only focuses on spatial distribution and disregard frequency fidelity in image reconstruction, leading to a frequency bias. To overcome this limitation, we propose a frequency-aware super-resolution framework that integrates three critical frequency-based modules (i.e., frequency transformation, frequency skip connection, and frequency alignment) and frequency-based loss function into a conditional generative adversarial network (cGAN). We conducted a large-scale quantitative study from an existing coronary OCT dataset to demonstrate the superiority of our proposed framework over existing deep learning frameworks. In addition, we confirmed the generalizability of our framework by applying it to fish corneal images and rat retinal images, demonstrating its capability to super-resolve morphological details in eye imaging.
Multi-scale reconstruction of undersampled spectral-spatial OCT data for coronary imaging using deep learning
Apr 25, 2022
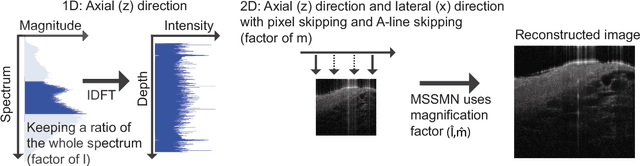
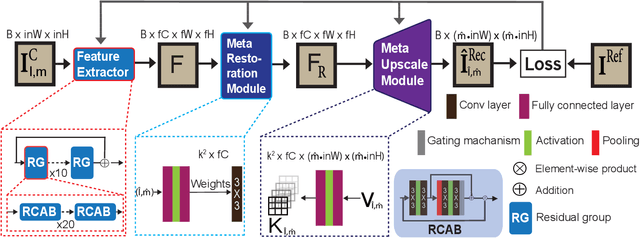

Coronary artery disease (CAD) is a cardiovascular condition with high morbidity and mortality. Intravascular optical coherence tomography (IVOCT) has been considered as an optimal imagining system for the diagnosis and treatment of CAD. Constrained by Nyquist theorem, dense sampling in IVOCT attains high resolving power to delineate cellular structures/ features. There is a trade-off between high spatial resolution and fast scanning rate for coronary imaging. In this paper, we propose a viable spectral-spatial acquisition method that down-scales the sampling process in both spectral and spatial domain while maintaining high quality in image reconstruction. The down-scaling schedule boosts data acquisition speed without any hardware modifications. Additionally, we propose a unified multi-scale reconstruction framework, namely Multiscale- Spectral-Spatial-Magnification Network (MSSMN), to resolve highly down-scaled (compressed) OCT images with flexible magnification factors. We incorporate the proposed methods into Spectral Domain OCT (SD-OCT) imaging of human coronary samples with clinical features such as stent and calcified lesions. Our experimental results demonstrate that spectral-spatial downscaled data can be better reconstructed than data that is downscaled solely in either spectral or spatial domain. Moreover, we observe better reconstruction performance using MSSMN than using existing reconstruction methods. Our acquisition method and multi-scale reconstruction framework, in combination, may allow faster SD-OCT inspection with high resolution during coronary intervention.
Multi-scale Sparse Representation-Based Shadow Inpainting for Retinal OCT Images
Feb 23, 2022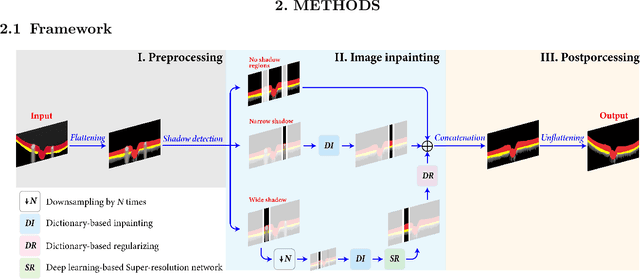


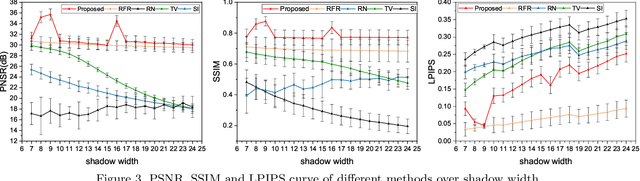
Inpainting shadowed regions cast by superficial blood vessels in retinal optical coherence tomography (OCT) images is critical for accurate and robust machine analysis and clinical diagnosis. Traditional sequence-based approaches such as propagating neighboring information to gradually fill in the missing regions are cost-effective. But they generate less satisfactory outcomes when dealing with larger missing regions and texture-rich structures. Emerging deep learning-based methods such as encoder-decoder networks have shown promising results in natural image inpainting tasks. However, they typically need a long computational time for network training in addition to the high demand on the size of datasets, which makes it difficult to be applied on often small medical datasets. To address these challenges, we propose a novel multi-scale shadow inpainting framework for OCT images by synergically applying sparse representation and deep learning: sparse representation is used to extract features from a small amount of training images for further inpainting and to regularize the image after the multi-scale image fusion, while convolutional neural network (CNN) is employed to enhance the image quality. During the image inpainting, we divide preprocessed input images into different branches based on the shadow width to harvest complementary information from different scales. Finally, a sparse representation-based regularizing module is designed to refine the generated contents after multi-scale feature aggregation. Experiments are conducted to compare our proposal versus both traditional and deep learning-based techniques on synthetic and real-world shadows. Results demonstrate that our proposed method achieves favorable image inpainting in terms of visual quality and quantitative metrics, especially when wide shadows are presented.
Frequency-Aware Physics-Inspired Degradation Model for Real-World Image Super-Resolution
Nov 05, 2021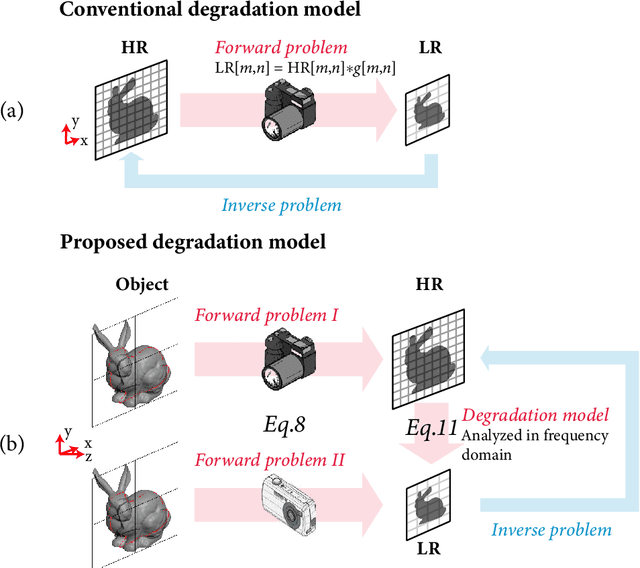

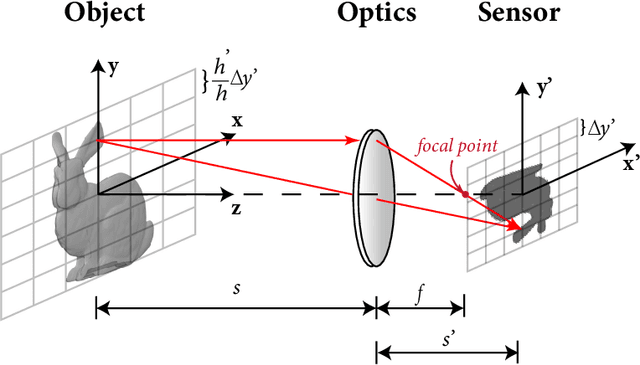
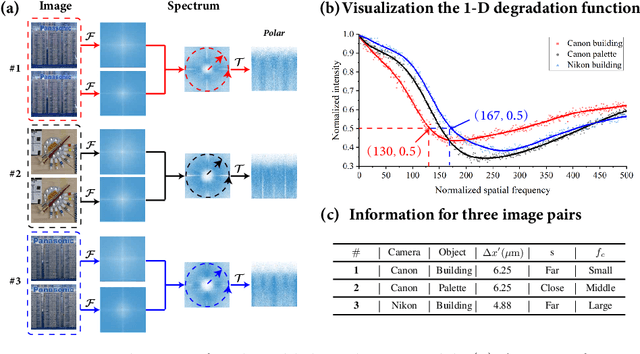
Current learning-based single image super-resolution (SISR) algorithms underperform on real data due to the deviation in the assumed degrada-tion process from that in the real-world scenario. Conventional degradation processes consider applying blur, noise, and downsampling (typicallybicubic downsampling) on high-resolution (HR) images to synthesize low-resolution (LR) counterparts. However, few works on degradation modelling have taken the physical aspects of the optical imaging system intoconsideration. In this paper, we analyze the imaging system optically andexploit the characteristics of the real-world LR-HR pairs in the spatial frequency domain. We formulate a real-world physics-inspired degradationmodel by considering bothopticsandsensordegradation; The physical degradation of an imaging system is modelled as a low-pass filter, whose cut-off frequency is dictated by the object distance, the focal length of thelens, and the pixel size of the image sensor. In particular, we propose to use a convolutional neural network (CNN) to learn the cutoff frequency of real-world degradation process. The learned network is then applied to synthesize LR images from unpaired HR images. The synthetic HR-LR image pairs are later used to train an SISR network. We evaluatethe effectiveness and generalization capability of the proposed degradation model on real-world images captured by different imaging systems. Experimental results showcase that the SISR network trained by using our synthetic data performs favorably against the network using the traditional degradation model. Moreover, our results are comparable to that obtained by the same network trained by using real-world LR-HR pairs, which are challenging to obtain in real scenes.
Multi-scale GCN-assisted two-stage network for joint segmentation of retinal layers and disc in peripapillary OCT images
Feb 09, 2021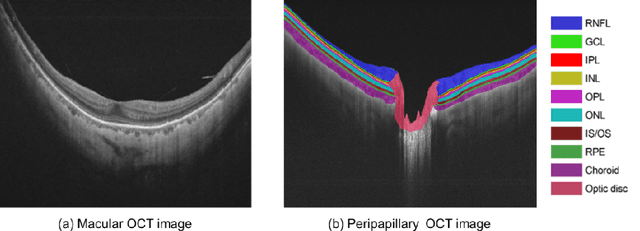
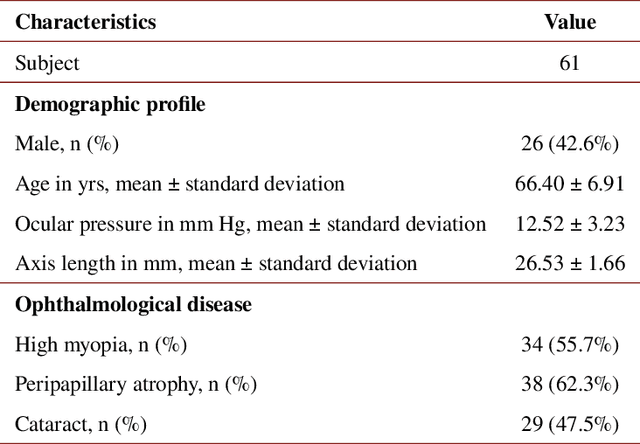
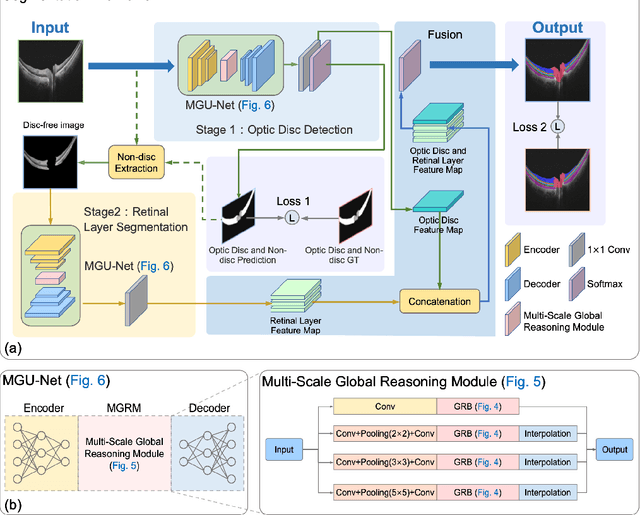
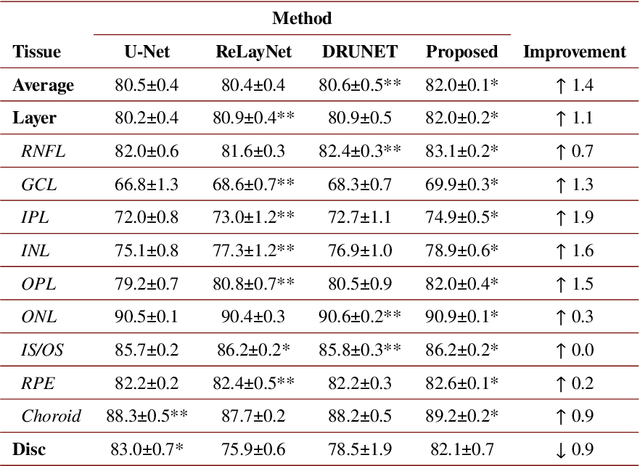
An accurate and automated tissue segmentation algorithm for retinal optical coherence tomography (OCT) images is crucial for the diagnosis of glaucoma. However, due to the presence of the optic disc, the anatomical structure of the peripapillary region of the retina is complicated and is challenging for segmentation. To address this issue, we developed a novel graph convolutional network (GCN)-assisted two-stage framework to simultaneously label the nine retinal layers and the optic disc. Specifically, a multi-scale global reasoning module is inserted between the encoder and decoder of a U-shape neural network to exploit anatomical prior knowledge and perform spatial reasoning. We conducted experiments on human peripapillary retinal OCT images. The Dice score of the proposed segmentation network is 0.820$\pm$0.001 and the pixel accuracy is 0.830$\pm$0.002, both of which outperform those from other state-of-the-art techniques.