 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Aware Physics-Inspired Degradation Model for Real-World Image Super-Resolution
Nov 05, 2021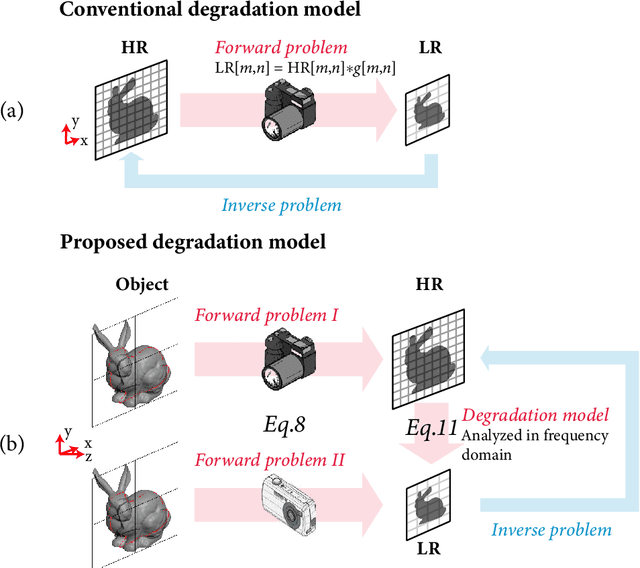

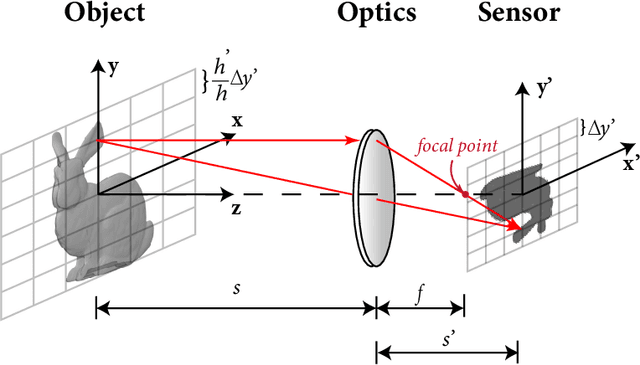
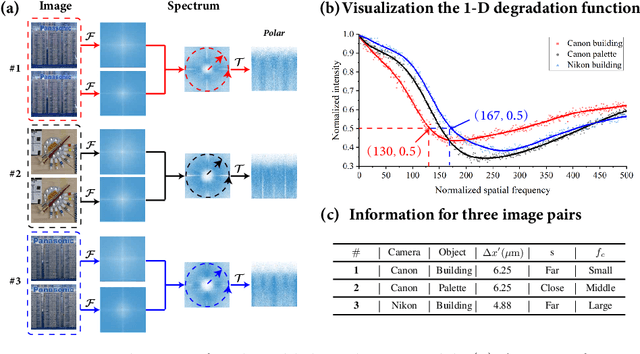
Current learning-based single image super-resolution (SISR) algorithms underperform on real data due to the deviation in the assumed degrada-tion process from that in the real-world scenario. Conventional degradation processes consider applying blur, noise, and downsampling (typicallybicubic downsampling) on high-resolution (HR) images to synthesize low-resolution (LR) counterparts. However, few works on degradation modelling have taken the physical aspects of the optical imaging system intoconsideration. In this paper, we analyze the imaging system optically andexploit the characteristics of the real-world LR-HR pairs in the spatial frequency domain. We formulate a real-world physics-inspired degradationmodel by considering bothopticsandsensordegradation; The physical degradation of an imaging system is modelled as a low-pass filter, whose cut-off frequency is dictated by the object distance, the focal length of thelens, and the pixel size of the image sensor. In particular, we propose to use a convolutional neural network (CNN) to learn the cutoff frequency of real-world degradation process. The learned network is then applied to synthesize LR images from unpaired HR images. The synthetic HR-LR image pairs are later used to train an SISR network. We evaluatethe effectiveness and generalization capability of the proposed degradation model on real-world images captured by different imaging systems. Experimental results showcase that the SISR network trained by using our synthetic data performs favorably against the network using the traditional degradation model. Moreover, our results are comparable to that obtained by the same network trained by using real-world LR-HR pairs, which are challenging to obtain in real scenes.
Characterizing Concept Drift
Apr 08, 2016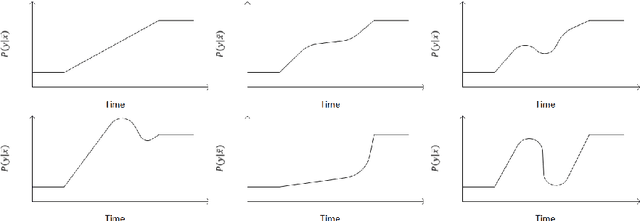
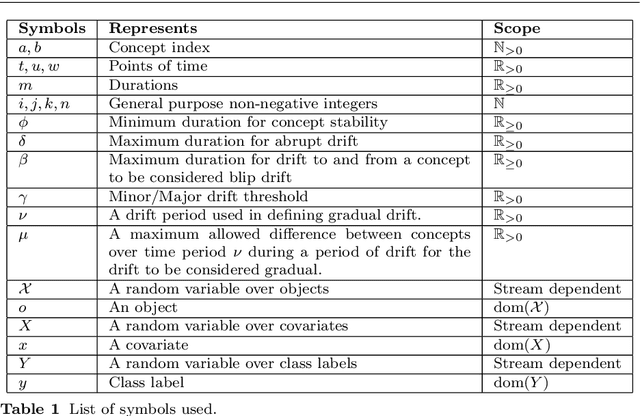
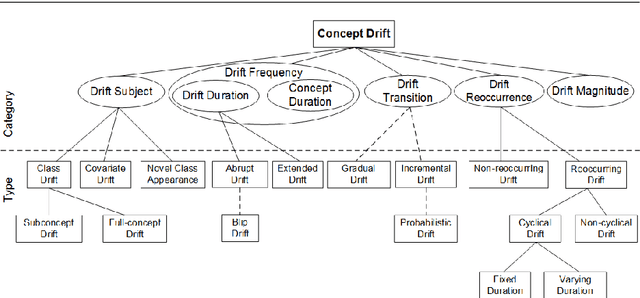
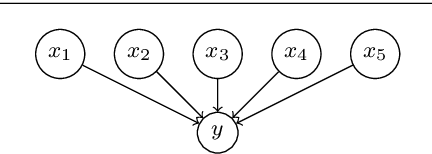
Most machine learning models are static, but the world is dynamic, and increasing online deployment of learned models gives increasing urgency to the development of efficient and effective mechanisms to address learning in the context of non-stationary distributions, or as it is commonly called concept drift. However, the key issue of characterizing the different types of drift that can occur has not previously been subjected to rigorous definition and analysis. In particular, while some qualitative drift categorizations have been proposed, few have been formally defined, and the quantitative descriptions required for precise and objective understanding of learner performance have not existed. We present the first comprehensive framework for quantitative analysis of drift. This supports the development of the first comprehensive set of formal definitions of types of concept drift. The formal definitions clarify ambiguities and identify gaps in previous definitions, giving rise to a new comprehensive taxonomy of concept drift types and a solid foundation for research into mechanisms to detect and address concept drift.
* Accepted for publication in Data Mining and Knowledge Discovery
Predicting Near-Future Churners and Win-Backs in the Telecommunications Industry
Oct 24, 2012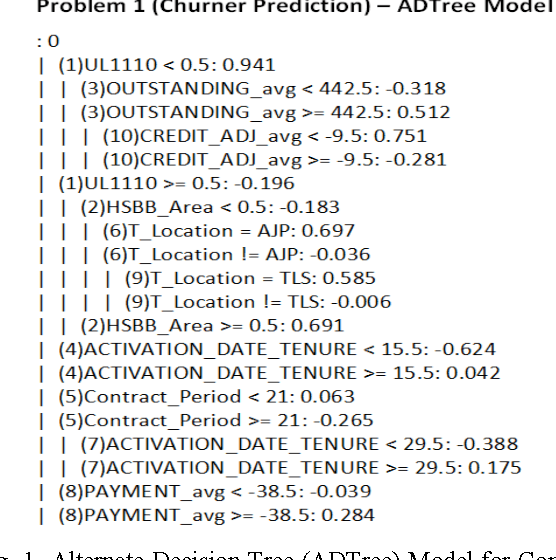



In this work, we presented the strategies and techniques that we have developed for predicting the near-future churners and win-backs for a telecom company. On a large-scale and real-world database containing customer profiles and some transaction data from a telecom company, we first analyzed the data schema, developed feature computation strategies and then extracted a large set of relevant features that can be associated with the customer churning and returning behaviors. Our features include both the original driver factors as well as some derived features. We evaluated our features on the imbalance corrected dataset, i.e. under-sampled dataset and compare a large number of existing machine learning tools, especially decision tree-based classifiers, for predicting the churners and win-backs. In general, we find RandomForest and SimpleCart learning algorithms generally perform well and tend to provide us with highly competitive prediction performance. Among the top-15 driver factors that signal the churn behavior, we find that the service utilization, e.g. last two months' download and upload volume, last three months' average upload and download, and the payment related factors are the most indicative features for predicting if churn will happen soon. Such features can collectively tell discrepancies between the service plans, payments and the dynamically changing utilization needs of the customers. Our proposed features and their computational strategy exhibit reasonable precision performance to predict churn behavior in near future.