 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Fundus Transformer for Multi-modal Diabetic Retinopathy Grading with Cataract
Nov 01, 2024



Diabetic retinopathy (DR) is a leading cause of blindness worldwide and a common complication of diabetes. As two different imaging tools for DR grading, color fundus photography (CFP) and infrared fundus photography (IFP) are highly-correlated and complementary in clinical applications. To the best of our knowledge, this is the first study that explores a novel multi-modal deep learning framework to fuse the information from CFP and IFP towards more accurate DR grading. Specifically, we construct a dual-stream architecture Cross-Fundus Transformer (CFT) to fuse the ViT-based features of two fundus image modalities. In particular, a meticulously engineered Cross-Fundus Attention (CFA) module is introduced to capture the correspondence between CFP and IFP images. Moreover, we adopt both the single-modality and multi-modality supervisions to maximize the overall performance for DR grading. Extensive experiments on a clinical dataset consisting of 1,713 pairs of multi-modal fundus images demonstrate the superiority of our proposed method. Our code will be released for public access.
Cross-Field Transformer for Diabetic Retinopathy Grading on Two-field Fundus Images
Dec 01, 2022Automatic diabetic retinopathy (DR) grading based on fundus photography has been widely explored to benefit the routine screening and early treatment. Existing researches generally focus on single-field fundus images, which have limited field of view for precise eye examinations. In clinical applications, ophthalmologists adopt two-field fundus photography as the dominating tool, where the information from each field (i.e.,macula-centric and optic disc-centric) is highly correlated and complementary, and benefits comprehensive decisions. However, automatic DR grading based on two-field fundus photography remains a challenging task due to the lack of publicly available datasets and effective fusion strategies. In this work, we first construct a new benchmark dataset (DRTiD) for DR grading, consisting of 3,100 two-field fundus images. To the best of our knowledge, it is the largest public DR dataset with diverse and high-quality two-field images. Then, we propose a novel DR grading approach, namely Cross-Field Transformer (CrossFiT), to capture the correspondence between two fields as well as the long-range spatial correlations within each field. Considering the inherent two-field geometric constraints, we particularly define aligned position embeddings to preserve relative consistent position in fundus. Besides, we perform masked cross-field attention during interaction to flter the noisy relations between fields. Extensive experiments on our DRTiD dataset and a public DeepDRiD dataset demonstrate the effectiveness of our CrossFiT network. The new dataset and the source code of CrossFiT will be publicly available at https://github.com/FDU-VTS/DRTiD.
Deep-OCTA: Ensemble Deep Learning Approaches for Diabetic Retinopathy Analysis on OCTA Images
Oct 02, 2022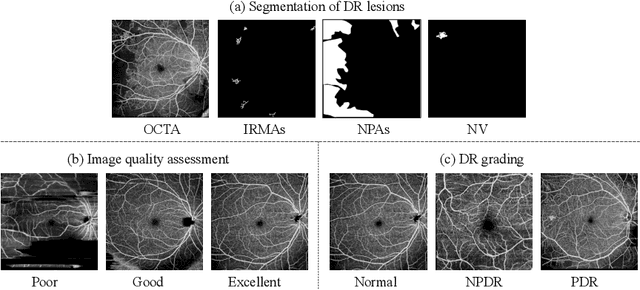
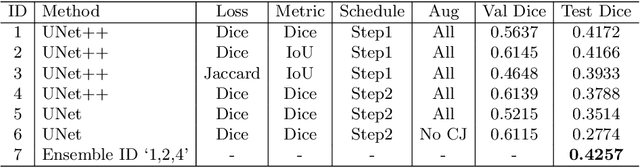
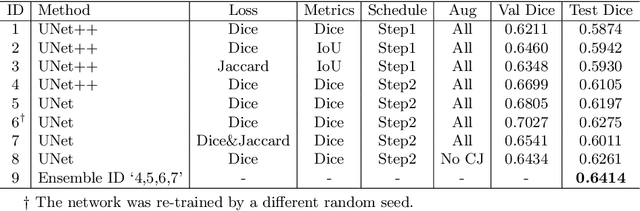
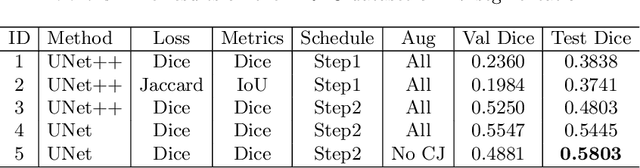
The ultra-wide optical coherence tomography angiography (OCTA) has become an important imaging modality in diabetic retinopathy (DR) diagnosis. However, there are few researches focusing on automatic DR analysis using ultra-wide OCTA. In this paper, we present novel and practical deep-learning solutions based on ultra-wide OCTA for the Diabetic Retinopathy Analysis Challenge (DRAC). In the segmentation of DR lesions task, we utilize UNet and UNet++ to segment three lesions with strong data augmentation and model ensemble. In the image quality assessment task, we create an ensemble of InceptionV3, SE-ResNeXt, and Vision Transformer models. Pre-training on the large dataset as well as the hybrid MixUp and CutMix strategy are both adopted to boost the generalization ability of our model. In the DR grading task, we build a Vision Transformer (ViT) and fnd that the ViT model pre-trained on color fundus images serves as a useful substrate for OCTA images. Our proposed methods ranked 4th, 3rd, and 5th on the three leaderboards of DRAC, respectively. The source code will be made available at https://github.com/FDU-VTS/DRAC.
Multi-scale GCN-assisted two-stage network for joint segmentation of retinal layers and disc in peripapillary OCT images
Feb 09, 2021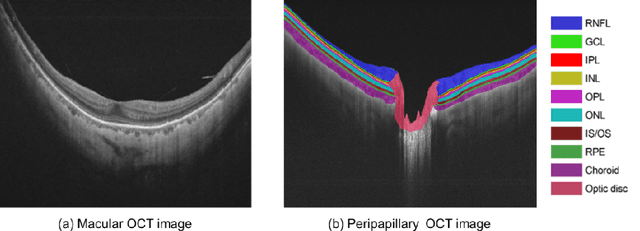
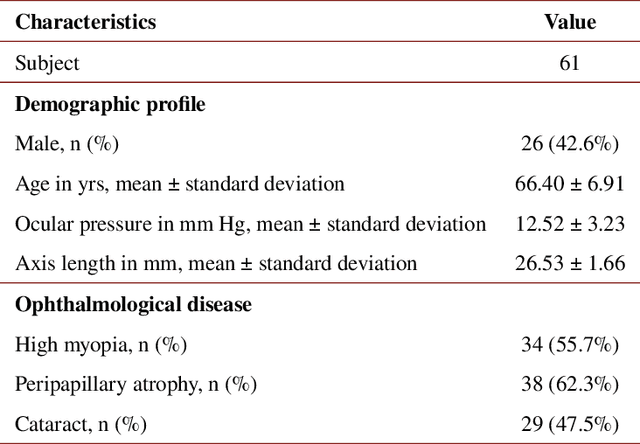
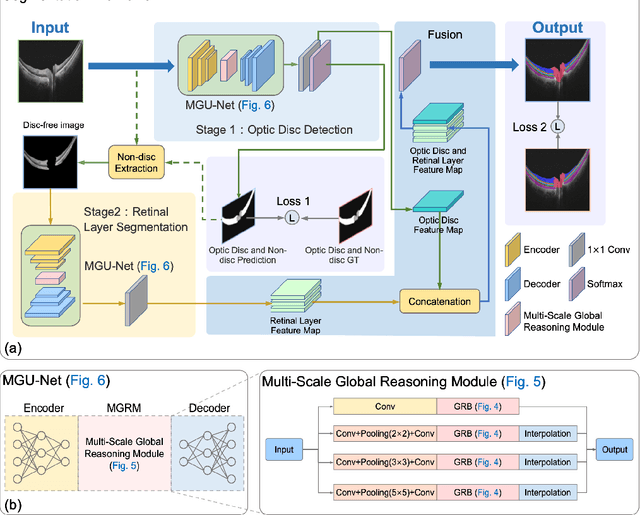
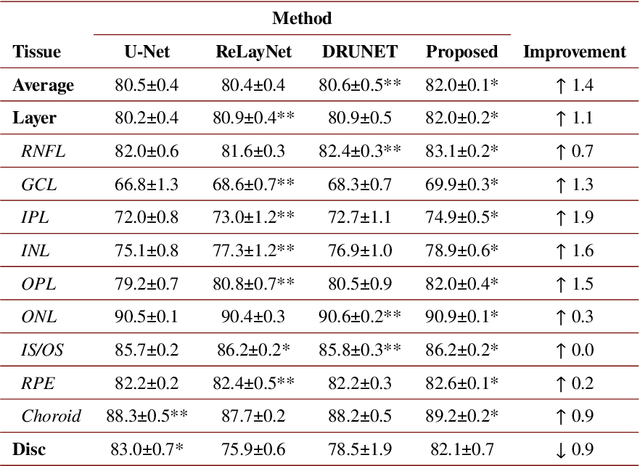
An accurate and automated tissue segmentation algorithm for retinal optical coherence tomography (OCT) images is crucial for the diagnosis of glaucoma. However, due to the presence of the optic disc, the anatomical structure of the peripapillary region of the retina is complicated and is challenging for segmentation. To address this issue, we developed a novel graph convolutional network (GCN)-assisted two-stage framework to simultaneously label the nine retinal layers and the optic disc. Specifically, a multi-scale global reasoning module is inserted between the encoder and decoder of a U-shape neural network to exploit anatomical prior knowledge and perform spatial reasoning. We conducted experiments on human peripapillary retinal OCT images. The Dice score of the proposed segmentation network is 0.820$\pm$0.001 and the pixel accuracy is 0.830$\pm$0.002, both of which outperform those from other state-of-the-art techniques.