 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoseRAD2026 Challenge dataset: AI accelerated photon and proton dose calculation for radiotherapy
Apr 14, 2026Purpose: Accurate dose calculation is essential in radiotherapy for precise tumor irradiation while sparing healthy tissue. With the growing adoption of MRI-guided and real-time adaptive radiotherapy, fast and accurate dose calculation on CT and MRI is increasingly needed. The DoseRAD2026 dataset and challenge provide a public benchmark of paired CT and MRI data with beam-level photon and proton Monte Carlo dose distributions for developing and evaluating advanced dose calculation methods. Acquisition and validation methods: The dataset comprises paired CT and MRI from 115 patients (75 training, 40 testing) treated on an MRI-linac for thoracic or abdominal lesions, derived from the SynthRAD2025 dataset. Pre-processing included deformable image registration, air-cavity correction, and resampling. Ground-truth photon (6 MV) and proton dose distributions were computed using open-source Monte Carlo algorithms, yielding 40,500 photon beams and 81,000 proton beamlets. Data format and usage notes: Data are organized into photon and proton subsets with paired CT-MRI images, beam-level dose distributions, and JSON beam configuration files. Files are provided in compressed MetaImage (.mha) format. The dataset is released under CC BY-NC 4.0, with training data available from April 2026 and the test set withheld until March 2030. Potential applications: The dataset supports benchmarking of fast dose calculation methods, including beam-level dose estimation for photon and proton therapy, MRI-based dose calculation in MRI-guided workflows, and real-time adaptive radiotherapy.
Towards Generalist Intelligence in Dentistry: Vision Foundation Models for Oral and Maxillofacial Radiology
Oct 16, 2025Oral and maxillofacial radiology plays a vital role in dental healthcare, but radiographic image interpretation is limited by a shortage of trained professionals. While AI approaches have shown promise, existing dental AI systems are restricted by their single-modality focus, task-specific design, and reliance on costly labeled data, hindering their generalization across diverse clinical scenarios. To address these challenges, we introduce DentVFM, the first family of vision foundation models (VFMs) designed for dentistry. DentVFM generates task-agnostic visual representations for a wide range of dental applications and uses self-supervised learning on DentVista, a large curated dental imaging dataset with approximately 1.6 million multi-modal radiographic images from various medical centers. DentVFM includes 2D and 3D variants based on the Vision Transformer (ViT) architecture. To address gaps in dental intelligence assessment and benchmarks, we introduce DentBench, a comprehensive benchmark covering eight dental subspecialties, more diseases, imaging modalities, and a wide geographical distribution. DentVFM shows impressive generalist intelligence, demonstrating robust generalization to diverse dental tasks, such as disease diagnosis, treatment analysis, biomarker identification, and anatomical landmark detection and segmentation. Experimental results indicate DentVFM significantly outperforms supervised, self-supervised, and weakly supervised baselines, offering superior generalization, label efficiency, and scalability. Additionally, DentVFM enables cross-modality diagnostics, providing more reliable results than experienced dentists in situations where conventional imaging is unavailable. DentVFM sets a new paradigm for dental AI, offering a scalable, adaptable, and label-efficient model to improve intelligent dental healthcare and address critical gaps in global oral healthcare.
Utilizing 3D Fast Spin Echo Anatomical Imaging to Reduce the Number of Contrast Preparations in $T_{1ρ}$ Quantification of Knee Cartilage Using Learning-Based Methods
Feb 13, 2025
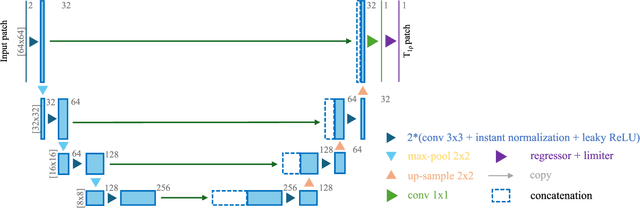
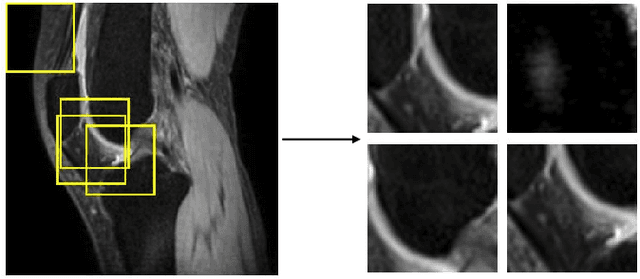

Purpose: To propose and evaluate an accelerated $T_{1\rho}$ quantification method that combines $T_{1\rho}$-weighted fast spin echo (FSE) images and proton density (PD)-weighted anatomical FSE images, leveraging deep learning models for $T_{1\rho}$ mapping. The goal is to reduce scan time and facilitate integration into routine clinical workflows for osteoarthritis (OA) assessment. Methods: This retrospective study utilized MRI data from 40 participants (30 OA patients and 10 healthy volunteers). A volume of PD-weighted anatomical FSE images and a volume of $T_{1\rho}$-weighted images acquired at a non-zero spin-lock time were used as input to train deep learning models, including a 2D U-Net and a multi-layer perceptron (MLP). $T_{1\rho}$ maps generated by these models were compared with ground truth maps derived from a traditional non-linear least squares (NLLS) fitting method using four $T_{1\rho}$-weighted images. Evaluation metrics included mean absolute error (MAE), mean absolute percentage error (MAPE), regional error (RE), and regional percentage error (RPE). Results: Deep learning models achieved RPEs below 5% across all evaluated scenarios, outperforming NLLS methods, especially in low signal-to-noise conditions. The best results were obtained using the 2D U-Net, which effectively leveraged spatial information for accurate $T_{1\rho}$ fitting. The proposed method demonstrated compatibility with shorter TSLs, alleviating RF hardware and specific absorption rate (SAR) limitations. Conclusion: The proposed approach enables efficient $T_{1\rho}$ mapping using PD-weighted anatomical images, reducing scan time while maintaining clinical standards. This method has the potential to facilitate the integration of quantitative MRI techniques into routine clinical practice, benefiting OA diagnosis and monitoring.
Cross-Fundus Transformer for Multi-modal Diabetic Retinopathy Grading with Cataract
Nov 01, 2024



Diabetic retinopathy (DR) is a leading cause of blindness worldwide and a common complication of diabetes. As two different imaging tools for DR grading, color fundus photography (CFP) and infrared fundus photography (IFP) are highly-correlated and complementary in clinical applications. To the best of our knowledge, this is the first study that explores a novel multi-modal deep learning framework to fuse the information from CFP and IFP towards more accurate DR grading. Specifically, we construct a dual-stream architecture Cross-Fundus Transformer (CFT) to fuse the ViT-based features of two fundus image modalities. In particular, a meticulously engineered Cross-Fundus Attention (CFA) module is introduced to capture the correspondence between CFP and IFP images. Moreover, we adopt both the single-modality and multi-modality supervisions to maximize the overall performance for DR grading. Extensive experiments on a clinical dataset consisting of 1,713 pairs of multi-modal fundus images demonstrate the superiority of our proposed method. Our code will be released for public access.
Unsupervised Domain Adaptation for Automated Knee Osteoarthritis Phenotype Classification
Dec 14, 2022Purpose: The aim of this study was to demonstrate the utility of unsupervised domain adaptation (UDA) in automated knee osteoarthritis (OA) phenotype classification using a small dataset (n=50). Materials and Methods: For this retrospective study, we collected 3,166 three-dimensional (3D) double-echo steady-state magnetic resonance (MR) images from the Osteoarthritis Initiative dataset and 50 3D turbo/fast spin-echo MR images from our institute (in 2020 and 2021) as the source and target datasets, respectively. For each patient, the degree of knee OA was initially graded according to the MRI Osteoarthritis Knee Score (MOAKS) before being converted to binary OA phenotype labels. The proposed UDA pipeline included (a) pre-processing, which involved automatic segmentation and region-of-interest cropping; (b) source classifier training, which involved pre-training phenotype classifiers on the source dataset; (c) target encoder adaptation, which involved unsupervised adaption of the source encoder to the target encoder and (d) target classifier validation, which involved statistical analysis of the target classification performance evaluated by the area under the receiver operating characteristic curve (AUROC), sensitivity, specificity and accuracy. Additionally, a classifier was trained without UDA for comparison. Results: The target classifier trained with UDA achieved improved AUROC, sensitivity, specificity and accuracy for both knee OA phenotypes compared with the classifier trained without UDA. Conclusion: The proposed UDA approach improves the performance of automated knee OA phenotype classification for small target datasets by utilising a large, high-quality source dataset for training. The results successfully demonstrated the advantages of the UDA approach in classification on small datasets.
Cross-Field Transformer for Diabetic Retinopathy Grading on Two-field Fundus Images
Dec 01, 2022Automatic diabetic retinopathy (DR) grading based on fundus photography has been widely explored to benefit the routine screening and early treatment. Existing researches generally focus on single-field fundus images, which have limited field of view for precise eye examinations. In clinical applications, ophthalmologists adopt two-field fundus photography as the dominating tool, where the information from each field (i.e.,macula-centric and optic disc-centric) is highly correlated and complementary, and benefits comprehensive decisions. However, automatic DR grading based on two-field fundus photography remains a challenging task due to the lack of publicly available datasets and effective fusion strategies. In this work, we first construct a new benchmark dataset (DRTiD) for DR grading, consisting of 3,100 two-field fundus images. To the best of our knowledge, it is the largest public DR dataset with diverse and high-quality two-field images. Then, we propose a novel DR grading approach, namely Cross-Field Transformer (CrossFiT), to capture the correspondence between two fields as well as the long-range spatial correlations within each field. Considering the inherent two-field geometric constraints, we particularly define aligned position embeddings to preserve relative consistent position in fundus. Besides, we perform masked cross-field attention during interaction to flter the noisy relations between fields. Extensive experiments on our DRTiD dataset and a public DeepDRiD dataset demonstrate the effectiveness of our CrossFiT network. The new dataset and the source code of CrossFiT will be publicly available at https://github.com/FDU-VTS/DRTiD.
Deep-OCTA: Ensemble Deep Learning Approaches for Diabetic Retinopathy Analysis on OCTA Images
Oct 02, 2022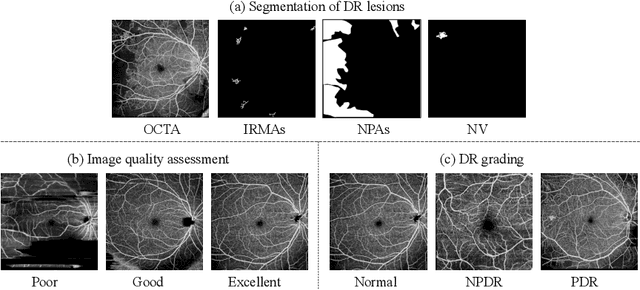
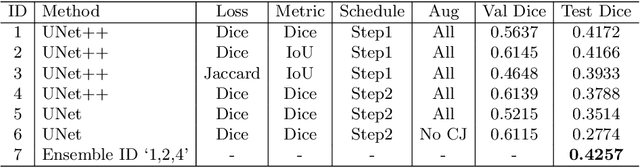
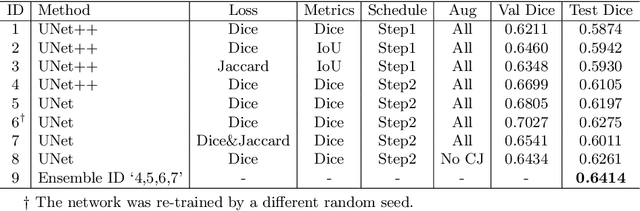
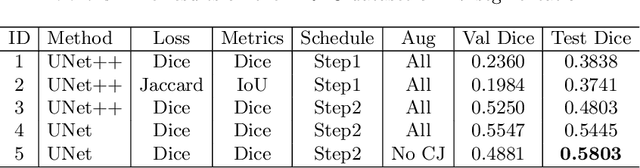
The ultra-wide optical coherence tomography angiography (OCTA) has become an important imaging modality in diabetic retinopathy (DR) diagnosis. However, there are few researches focusing on automatic DR analysis using ultra-wide OCTA. In this paper, we present novel and practical deep-learning solutions based on ultra-wide OCTA for the Diabetic Retinopathy Analysis Challenge (DRAC). In the segmentation of DR lesions task, we utilize UNet and UNet++ to segment three lesions with strong data augmentation and model ensemble. In the image quality assessment task, we create an ensemble of InceptionV3, SE-ResNeXt, and Vision Transformer models. Pre-training on the large dataset as well as the hybrid MixUp and CutMix strategy are both adopted to boost the generalization ability of our model. In the DR grading task, we build a Vision Transformer (ViT) and fnd that the ViT model pre-trained on color fundus images serves as a useful substrate for OCTA images. Our proposed methods ranked 4th, 3rd, and 5th on the three leaderboards of DRAC, respectively. The source code will be made available at https://github.com/FDU-VTS/DRAC.
Self-organized Polygon Formation Control based on Distributed Estimation
Aug 01, 2022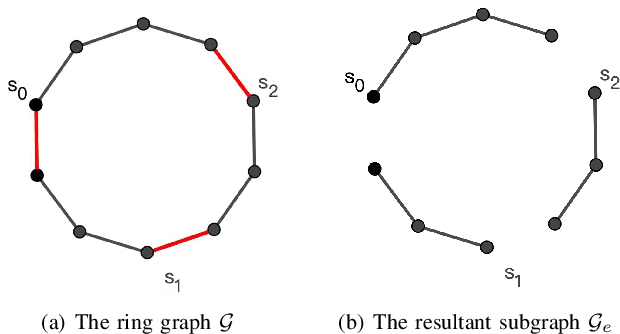
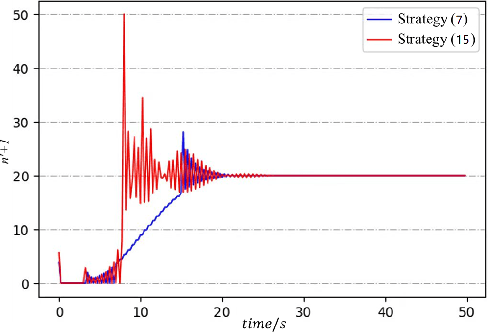
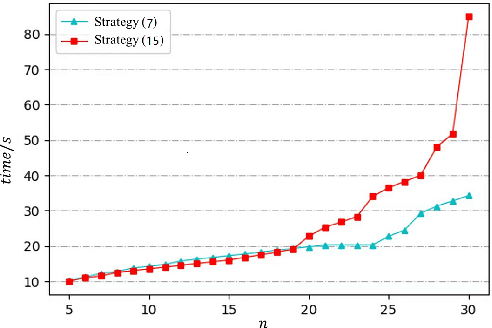
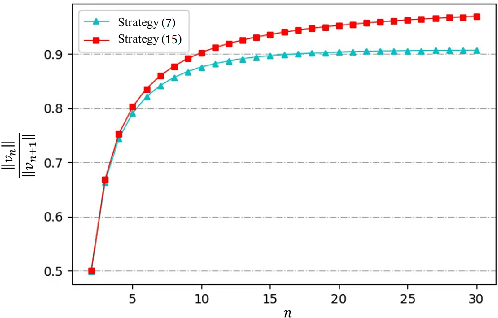
This paper studies the problem of controlling a multi-robot system to achieve a polygon formation in a self-organized manner. Different from the typical formation control strategies where robots are steered to satisfy the predefined control variables, such as pairwise distances, relative positions and bearings, the foremost idea of this paper is to achieve polygon formations by injecting control inputs randomly to a few robots (say, vertex robots) of the group, and the rest follow the simple principles of moving towards the midpoint of their two nearest neighbors in the ring graph without any external inputs. In our problem, a fleet of robots is initially distributed in the plane. The socalled vertex robots take the responsibility of determining the geometric shape of the entire formation and its overall size, while the others move so as to minimize the differences with two direct neighbors. In the first step, each vertex robot estimates the number of robots in its associated chain. Two types of control inputs that serve for the estimation are designed using the measurements from the latest and the last two time instants respectively. In the second step, the self-organized formation control law is proposed where only vertex robots receive external information. Comparisons between the two estimation strategies are carried out in terms of the convergence speed and robustness. The effectiveness of the whole control framework is further validated in both simulation and physical experiments.
Denoising of Three-Dimensional Fast Spin Echo Magnetic Resonance Images of Knee Joints using Spatial-Variant Noise-Relevant Residual Learning of Convolution Neural Network
Apr 21, 2022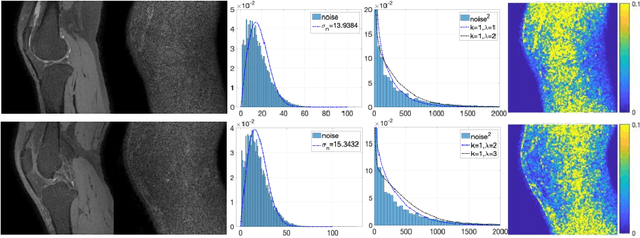
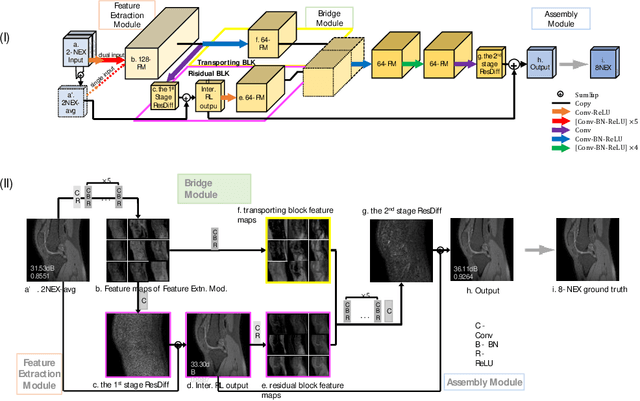
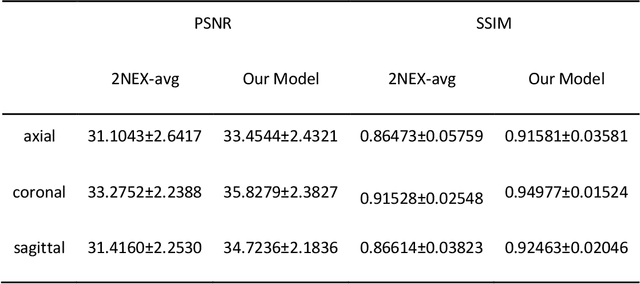

Two-dimensional (2D) fast spin echo (FSE) techniques play a central role in the clinical magnetic resonance imaging (MRI) of knee joints. Moreover, three-dimensional (3D) FSE provides high-isotropic-resolution magnetic resonance (MR) images of knee joints, but it has a reduced signal-to-noise ratio compared to 2D FSE. Deep-learning denoising methods are a promising approach for denoising MR images, but they are often trained using synthetic noise due to challenges in obtaining true noise distributions for MR images. In this study, inherent true noise information from 2-NEX acquisition was used to develop a deep-learning model based on residual learning of convolutional neural network (CNN), and this model was used to suppress the noise in 3D FSE MR images of knee joints. The proposed CNN used two-step residual learning over parallel transporting and residual blocks and was designed to comprehensively learn real noise features from 2-NEX training data. The results of an ablation study validated the network design. The new method achieved improved denoising performance of 3D FSE knee MR images compared with current state-of-the-art methods, based on the peak signal-to-noise ratio and structural similarity index measure. The improved image quality after denoising using the new method was verified by radiological evaluation. A deep CNN using the inherent spatial-varying noise information in 2-NEX acquisitions was developed. This method showed promise for clinical MRI assessments of the knee, and has potential applications for the assessment of other anatomical structures.
AutoKnow: Self-Driving Knowledge Collection for Products of Thousands of Types
Jun 24, 2020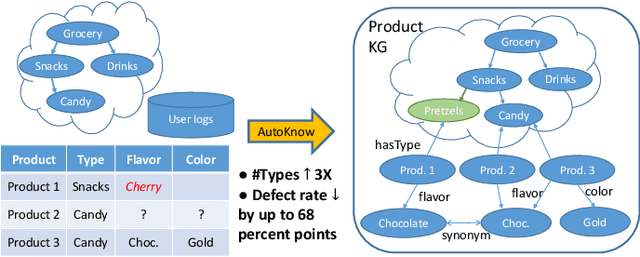

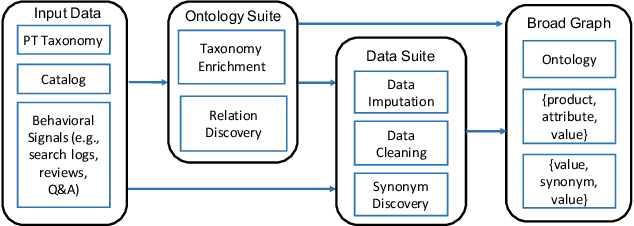
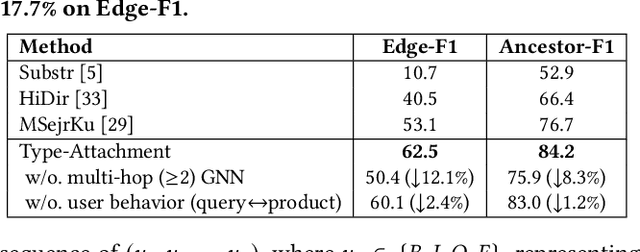
Can one build a knowledge graph (KG) for all products in the world? Knowledge graphs have firmly established themselves as valuable sources of information for search and question answering, and it is natural to wonder if a KG can contain information about products offered at online retail sites. There have been several successful examples of generic KGs, but organizing information about products poses many additional challenges, including sparsity and noise of structured data for products, complexity of the domain with millions of product types and thousands of attributes, heterogeneity across large number of categories, as well as large and constantly growing number of products. We describe AutoKnow, our automatic (self-driving) system that addresses these challenges. The system includes a suite of novel techniques for taxonomy construction, product property identification, knowledge extraction, anomaly detection, and synonym discovery. AutoKnow is (a) automatic, requiring little human intervention, (b) multi-scalable, scalable in multiple dimensions (many domains, many products, and many attributes), and (c) integrative, exploiting rich customer behavior logs. AutoKnow has been operational in collecting product knowledge for over 11K product types.