 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSMOS: Multi-organ segmentation facilitated by medical report supervision
Sep 04, 2024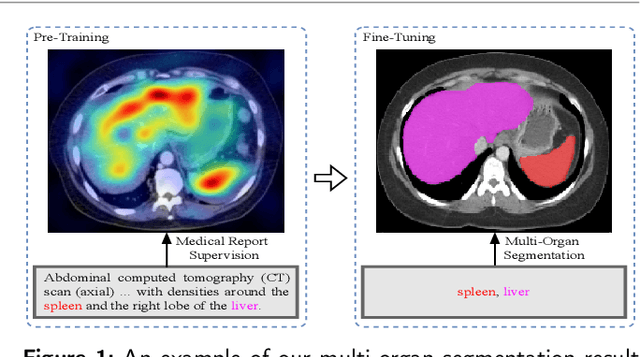
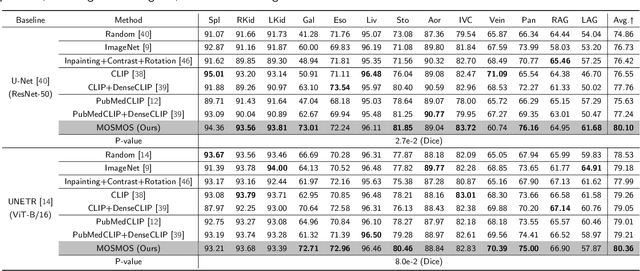
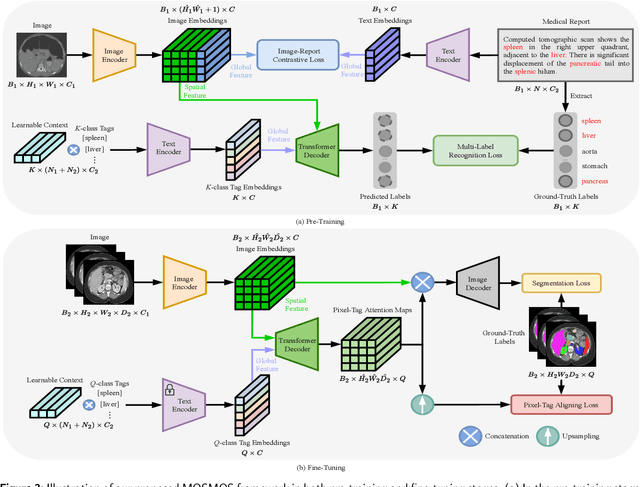
Owing to a large amount of multi-modal data in modern medical systems, such as medical images and reports, Medical Vision-Language Pre-training (Med-VLP) has demonstrated incredible achievements in coarse-grained downstream tasks (i.e., medical classification, retrieval, and visual question answering). However, the problem of transferring knowledge learned from Med-VLP to fine-grained multi-organ segmentation tasks has barely been investigated. Multi-organ segmentation is challenging mainly due to the lack of large-scale fully annotated datasets and the wide variation in the shape and size of the same organ between individuals with different diseases. In this paper, we propose a novel pre-training & fine-tuning framework for Multi-Organ Segmentation by harnessing Medical repOrt Supervision (MOSMOS). Specifically, we first introduce global contrastive learning to maximally align the medical image-report pairs in the pre-training stage. To remedy the granularity discrepancy, we further leverage multi-label recognition to implicitly learn the semantic correspondence between image pixels and organ tags. More importantly, our pre-trained models can be transferred to any segmentation model by introducing the pixel-tag attention maps. Different network settings, i.e., 2D U-Net and 3D UNETR, are utilized to validate the generalization. We have extensively evaluated our approach using different diseases and modalities on BTCV, AMOS, MMWHS, and BRATS datasets. Experimental results in various settings demonstrate the effectiveness of our framework. This framework can serve as the foundation to facilitate future research on automatic annotation tasks under the supervision of medical reports.
Cross-Field Transformer for Diabetic Retinopathy Grading on Two-field Fundus Images
Dec 01, 2022Automatic diabetic retinopathy (DR) grading based on fundus photography has been widely explored to benefit the routine screening and early treatment. Existing researches generally focus on single-field fundus images, which have limited field of view for precise eye examinations. In clinical applications, ophthalmologists adopt two-field fundus photography as the dominating tool, where the information from each field (i.e.,macula-centric and optic disc-centric) is highly correlated and complementary, and benefits comprehensive decisions. However, automatic DR grading based on two-field fundus photography remains a challenging task due to the lack of publicly available datasets and effective fusion strategies. In this work, we first construct a new benchmark dataset (DRTiD) for DR grading, consisting of 3,100 two-field fundus images. To the best of our knowledge, it is the largest public DR dataset with diverse and high-quality two-field images. Then, we propose a novel DR grading approach, namely Cross-Field Transformer (CrossFiT), to capture the correspondence between two fields as well as the long-range spatial correlations within each field. Considering the inherent two-field geometric constraints, we particularly define aligned position embeddings to preserve relative consistent position in fundus. Besides, we perform masked cross-field attention during interaction to flter the noisy relations between fields. Extensive experiments on our DRTiD dataset and a public DeepDRiD dataset demonstrate the effectiveness of our CrossFiT network. The new dataset and the source code of CrossFiT will be publicly available at https://github.com/FDU-VTS/DRTiD.
Pyramid Region-based Slot Attention Network for Temporal Action Proposal Generation
Jun 21, 2022
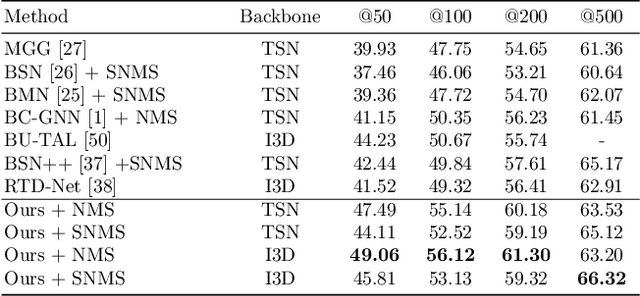
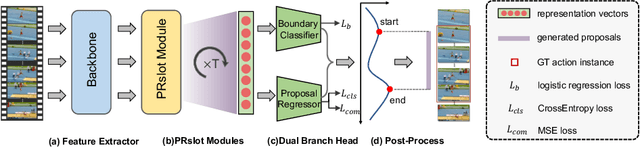

It has been found that temporal action proposal generation, which aims to discover the temporal action instances within the range of the start and end frames in the untrimmed videos, can largely benefit from proper temporal and semantic context exploitation. The latest efforts were dedicated to considering the temporal context and similarity-based semantic contexts through self-attention modules. However, they still suffer from cluttered background information and limited contextual feature learning. In this paper, we propose a novel Pyramid Region-based Slot Attention (PRSlot) module to address these issues. Instead of using the similarity computation, our PRSlot module directly learns the local relations in an encoder-decoder manner and generates the representation of a local region enhanced based on the attention over input features called \textit{slot}. Specifically, upon the input snippet-level features, PRSlot module takes the target snippet as \textit{query}, its surrounding region as \textit{key} and then generates slot representations for each \textit{query-key} slot by aggregating the local snippet context with a parallel pyramid strategy. Based on PRSlot modules, we present a novel Pyramid Region-based Slot Attention Network termed PRSA-Net to learn a unified visual representation with rich temporal and semantic context for better proposal generation. Extensive experiments are conducted on two widely adopted THUMOS14 and ActivityNet-1.3 benchmarks. Our PRSA-Net outperforms other state-of-the-art methods. In particular, we improve the AR@100 from the previous best 50.67% to 56.12% for proposal generation and raise the mAP under 0.5 tIoU from 51.9\% to 58.7\% for action detection on THUMOS14. \textit{Code is available at} \url{https://github.com/handhand123/PRSA-Net}
CREAM: Weakly Supervised Object Localization via Class RE-Activation Mapping
May 27, 2022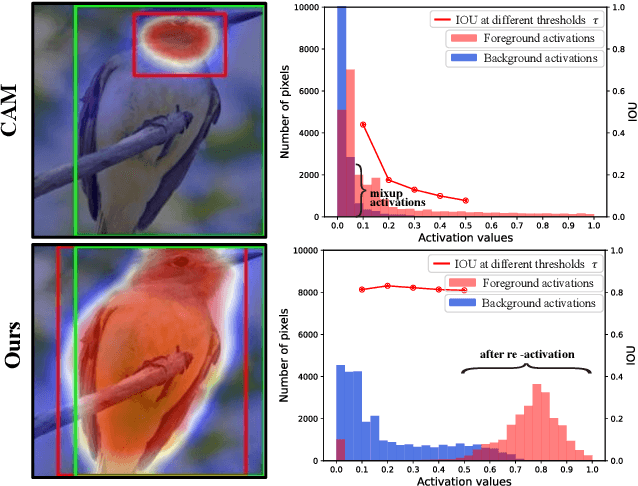
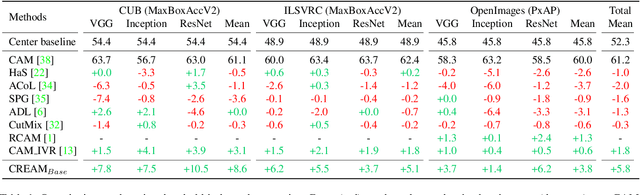
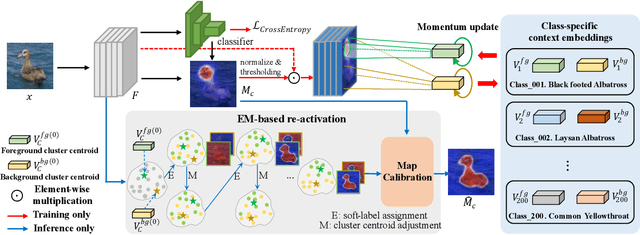
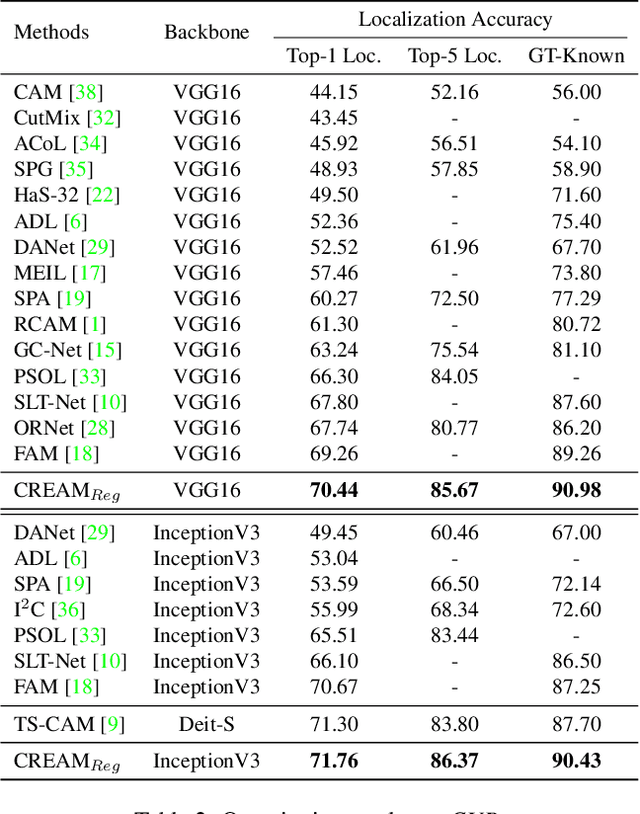
Weakly Supervised Object Localization (WSOL) aims to localize objects with image-level supervision. Existing works mainly rely on Class Activation Mapping (CAM) derived from a classification model. However, CAM-based methods usually focus on the most discriminative parts of an object (i.e., incomplete localization problem). In this paper, we empirically prove that this problem is associated with the mixup of the activation values between less discriminative foreground regions and the background. To address it, we propose Class RE-Activation Mapping (CREAM), a novel clustering-based approach to boost the activation values of the integral object regions. To this end, we introduce class-specific foreground and background context embeddings as cluster centroids. A CAM-guided momentum preservation strategy is developed to learn the context embeddings during training. At the inference stage, the re-activation mapping is formulated as a parameter estimation problem under Gaussian Mixture Model, which can be solved by deriving an unsupervised Expectation-Maximization based soft-clustering algorithm. By simply integrating CREAM into various WSOL approaches, our method significantly improves their performance. CREAM achieves the state-of-the-art performance on CUB, ILSVRC and OpenImages benchmark datasets. Code will be available at https://github.com/Jazzcharles/CREAM.
Self-Supervised Video Representation Learning with Motion-Contrastive Perception
Apr 10, 2022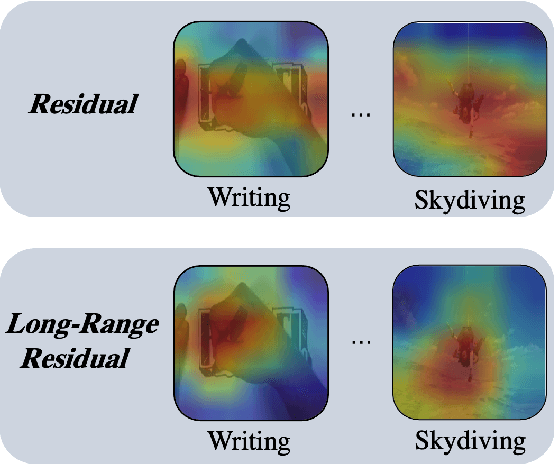
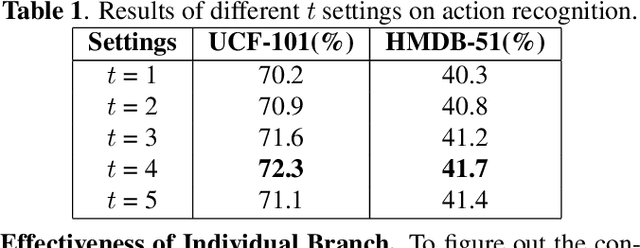
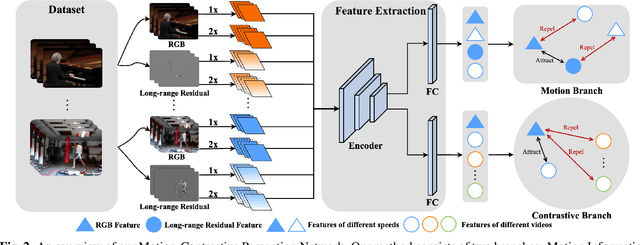

Visual-only self-supervised learning has achieved significant improvement in video representation learning. Existing related methods encourage models to learn video representations by utilizing contrastive learning or designing specific pretext tasks. However, some models are likely to focus on the background, which is unimportant for learning video representations. To alleviate this problem, we propose a new view called long-range residual frame to obtain more motion-specific information. Based on this, we propose the Motion-Contrastive Perception Network (MCPNet), which consists of two branches, namely, Motion Information Perception (MIP) and Contrastive Instance Perception (CIP), to learn generic video representations by focusing on the changing areas in videos. Specifically, the MIP branch aims to learn fine-grained motion features, and the CIP branch performs contrastive learning to learn overall semantics information for each instance. Experiments on two benchmark datasets UCF-101 and HMDB-51 show that our method outperforms current state-of-the-art visual-only self-supervised approaches.
MM-Pyramid: Multimodal Pyramid Attentional Network for Audio-Visual Event Localization and Video Parsing
Nov 24, 2021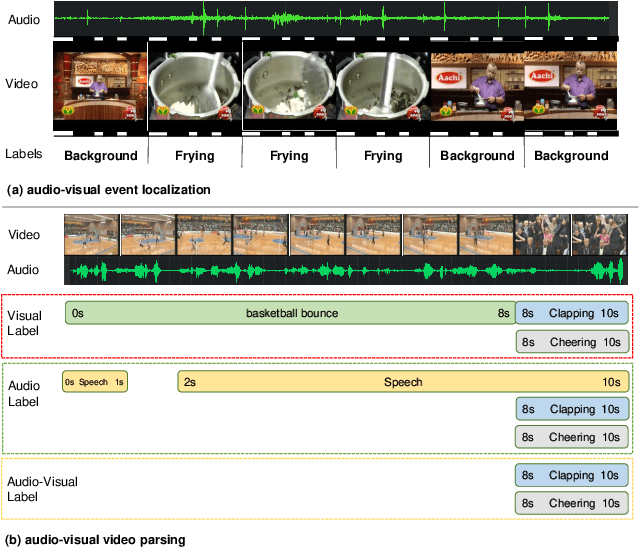
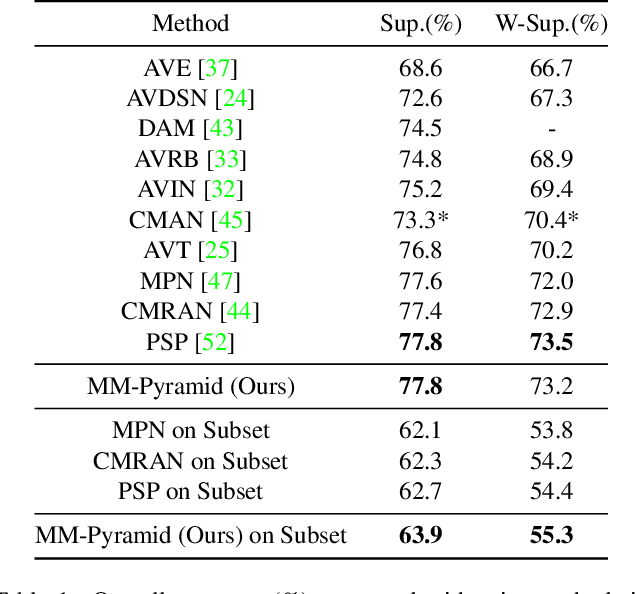
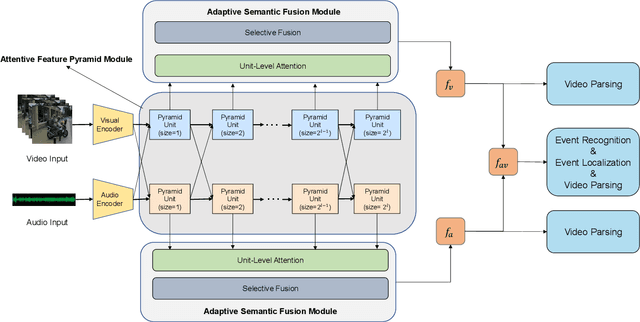
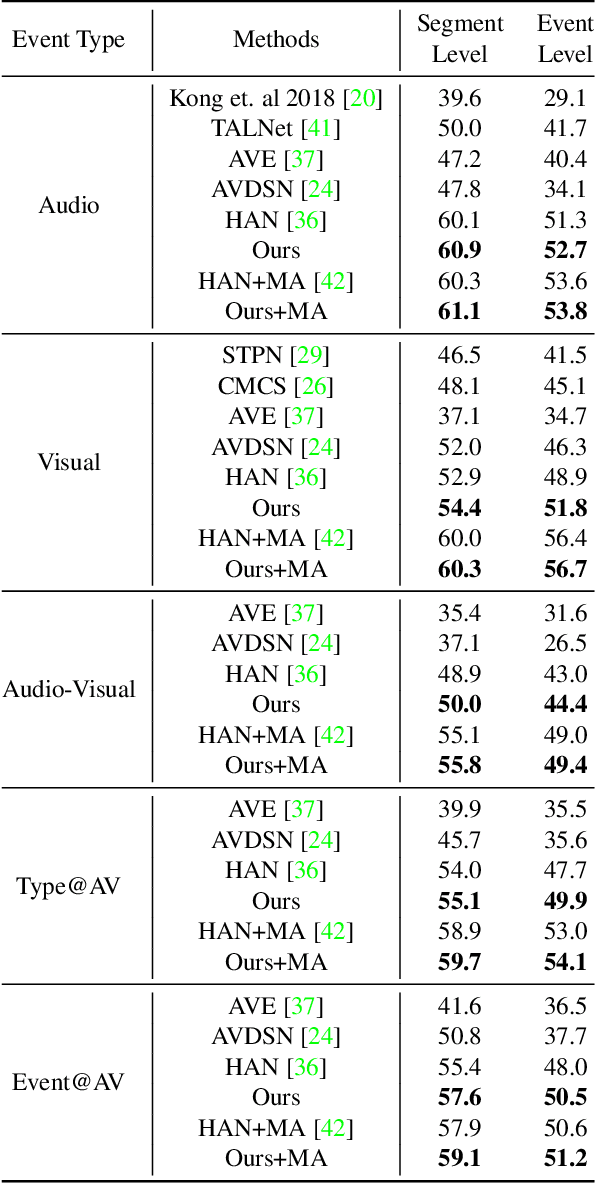
Recognizing and localizing events in videos is a fundamental task for video understanding. Since events may occur in auditory and visual modalities, multimodal detailed perception is essential for complete scene comprehension. Most previous works attempted to analyze videos from a holistic perspective. However, they do not consider semantic information at multiple scales, which makes the model difficult to localize events in various lengths. In this paper, we present a Multimodal Pyramid Attentional Network (MM-Pyramid) that captures and integrates multi-level temporal features for audio-visual event localization and audio-visual video parsing. Specifically, we first propose the attentive feature pyramid module. This module captures temporal pyramid features via several stacking pyramid units, each of them is composed of a fixed-size attention block and dilated convolution block. We also design an adaptive semantic fusion module, which leverages a unit-level attention block and a selective fusion block to integrate pyramid features interactively. Extensive experiments on audio-visual event localization and weakly-supervised audio-visual video parsing tasks verify the effectiveness of our approach.
Evaluating Two-Stream CNN for Video Classification
Apr 08, 2015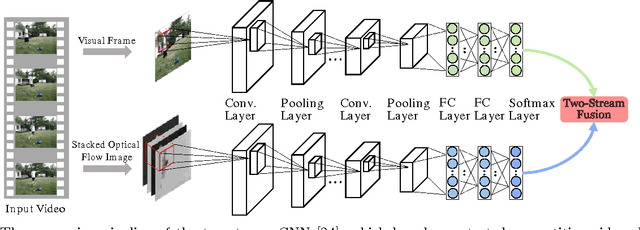
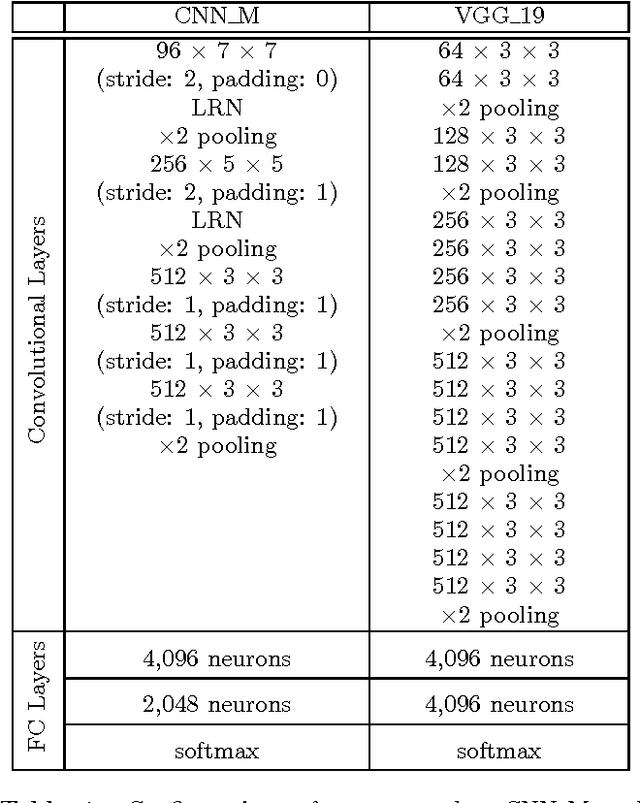
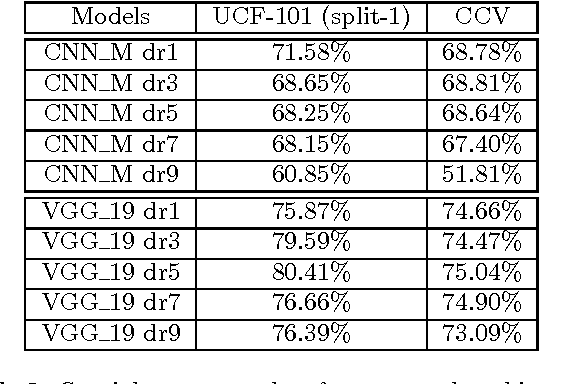
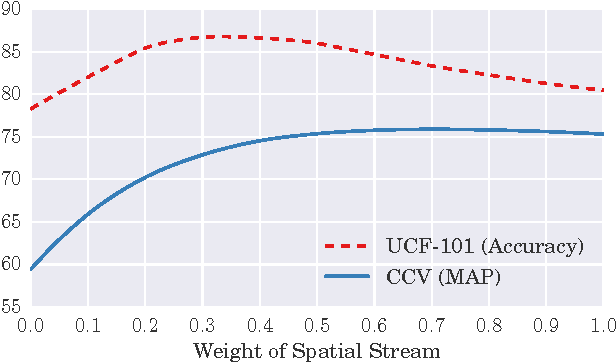
Videos contain very rich semantic information. Traditional hand-crafted features are known to be inadequate in analyzing complex video semantics. Inspired by the huge success of the deep learning methods in analyzing image, audio and text data, significant efforts are recently being devoted to the design of deep nets for video analytics. Among the many practical needs, classifying videos (or video clips) based on their major semantic categories (e.g., "skiing") is useful in many applications. In this paper, we conduct an in-depth study to investigate important implementation options that may affect the performance of deep nets on video classification. Our evaluations are conducted on top of a recent two-stream convolutional neural network (CNN) pipeline, which uses both static frames and motion optical flows, and has demonstrated competitive performance against the state-of-the-art methods. In order to gain insights and to arrive at a practical guideline, many important options are studied, including network architectures, model fusion, learning parameters and the final prediction methods. Based on the evaluations, very competitive results are attained on two popular video classification benchmarks. We hope that the discussions and conclusions from this work can help researchers in related fields to quickly set up a good basis for further investigations along this very promising direction.